MM-Food-100K
收藏魔搭社区2026-05-22 更新2025-11-03 收录
下载链接:
https://modelscope.cn/datasets/Codatta/MM-Food-100K
下载链接
链接失效反馈官方服务:
资源简介:
## Overview

This project aims to introduce and release a comprehensive food image dataset designed specifically for computer vision tasks, particularly food recognition, classification, and nutritional analysis. We hope this dataset will provide a reliable resource for researchers and developers to advance the field of food AI. By publishing on Hugging Face, we expect to foster community collaboration and accelerate innovation in applications such as smart recipe recommendations, meal management, and health monitoring systems.
- **Technical Report** - [MM-Food-100K: A 100,000-Sample Multimodal Food Intelligence Dataset with Verifiable Provenance](https://huggingface.co/papers/2508.10429)
## Motivation
Tracking what we eat is key to achieving health goals, but traditional food diaries are a chore. While new AI applications can quickly log meals with a photo, their accuracy still has significant shortcomings. Existing AI models perform poorly when dealing with diverse global foods; for example, calorie estimation for Asian dishes can have an error rate as high as 76%. Even advanced models often fail to accurately estimate portion sizes and nutritional content.
| **<font style="color:rgb(27, 28, 29);">Dataset Name & Link</font>** | **<font style="color:rgb(27, 28, 29);">Data Size & Labels</font>** | **<font style="color:rgb(27, 28, 29);">Primary Focus</font>** | **<font style="color:rgb(27, 28, 29);">Key Characteristics / Limitations</font>** | **<font style="color:rgb(27, 28, 29);">Food Type (Packaging)</font>** |
| --- | --- | --- | --- | --- |
| <font style="color:rgb(27, 28, 29);">Food 101 </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/ethz/food101) | <font style="color:rgb(27, 28, 29);">75.8k images, 101 categories</font> | <font style="color:rgb(27, 28, 29);">Global food classification</font> | <font style="color:rgb(27, 28, 29);">Images only, no nutritional or weight data. Diverse but shallow.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
| <font style="color:rgb(27, 28, 29);">indian_food_images </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/rajistics/indian_food_images) | <font style="color:rgb(27, 28, 29);">5.33k images, 20 categories</font> | <font style="color:rgb(27, 28, 29);">Indian food classification</font> | <font style="color:rgb(27, 28, 29);">Niche focus, small dataset. Images only.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
| <font style="color:rgb(27, 28, 29);">chinese_food_caption </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/zmao/chinese_food_caption) | <font style="color:rgb(27, 28, 29);">720 images, text descriptions</font> | <font style="color:rgb(27, 28, 29);">Chinese food descriptions</font> | <font style="color:rgb(27, 28, 29);">Very small dataset, non-classified, text-heavy. No nutritional or weight data.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
| <font style="color:rgb(27, 28, 29);">Food Ingredients and Recipes Dataset with Images </font>[<font style="color:rgb(27, 28, 29);">Kaggle</font>](https://www.kaggle.com/datasets/pes12017000148/food-ingredients-and-recipe-dataset-with-images?resource=download) | <font style="color:rgb(27, 28, 29);">13.6k images, ingredients & recipes</font> | <font style="color:rgb(27, 28, 29);">Food ingredients and preparation instructions</font> | <font style="color:rgb(27, 28, 29);">Scraped from recipe platforms. Focus on components, not direct nutritional values or weights.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
| <font style="color:rgb(27, 28, 29);">Food500Cap </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/advancedcv/Food500Cap) | <font style="color:rgb(27, 28, 29);">19.9k images, categories & text descriptions</font> | <font style="color:rgb(27, 28, 29);">Food classification and description</font> | <font style="color:rgb(27, 28, 29);">Similar to Chinese food caption but larger. No nutritional or weight data.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
| <font style="color:rgb(27, 28, 29);">openfoodfacts_package_weights </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/FoodIntake/openfoodfacts_package_weights) | <font style="color:rgb(27, 28, 29);">457k entries, categories, brand, quantity, language</font> | <font style="color:rgb(27, 28, 29);">Packaged food data from Open Food Facts</font> | <font style="color:rgb(27, 28, 29);">Only dataset with weight data, but exclusively for packaged foods. Crowdsourced, variable quality.</font> | **<font style="color:rgb(27, 28, 29);">Packaged</font>** |
| <font style="color:rgb(27, 28, 29);">FoodSeg103 </font>[<font style="color:rgb(27, 28, 29);">HuggingFace</font>](https://huggingface.co/datasets/EduardoPacheco/FoodSeg103) | <font style="color:rgb(27, 28, 29);">4.98k images, food categories</font> | <font style="color:rgb(27, 28, 29);">Food segmentation (multiple foods per image)</font> | <font style="color:rgb(27, 28, 29);">Focus on identifying multiple items in one image. Small. No nutritional or weight data.</font> | <font style="color:rgb(27, 28, 29);">Unpackaged</font> |
We conducted a detailed review of prominent food datasets on Hugging Face and Kaggle and found the following limitations:
+ **Insufficient Food Diversity:** The datasets lack richness in terms of quantity, variety, and geographical coverage, differing significantly from real-world scenarios.
+ **Monolithic Annotation Information:** Annotations are overly simplistic, primarily focused on food name classification, without descriptions of portion sizes, nutritional content, or other crucial details.
+ **Unrealistic Image Quality:** The images are often highly curated, bearing little resemblance to the casual, real-world photos taken by users in application settings.
This reveals a core problem: we lack a comprehensive, high-quality food dataset that is more aligned with real-world application scenarios. Most existing datasets are small in scale, typically consisting of simple image-to-food-name mappings, and rarely provide crucial information like actual weight and calories. This makes it difficult for AI models to achieve precise performance with complex, real-world meals.
As people become increasingly focused on healthy eating and personalized nutrition, the demand for AI models that can accurately identify and analyze food has grown. While existing food datasets have laid a foundation for research in this field, there is still room for improvement in diversity, annotation granularity, and quantity. Our motivation is to build a larger, more representative, and meticulously annotated food dataset to overcome the limitations of existing resources.
## Dataset Contents

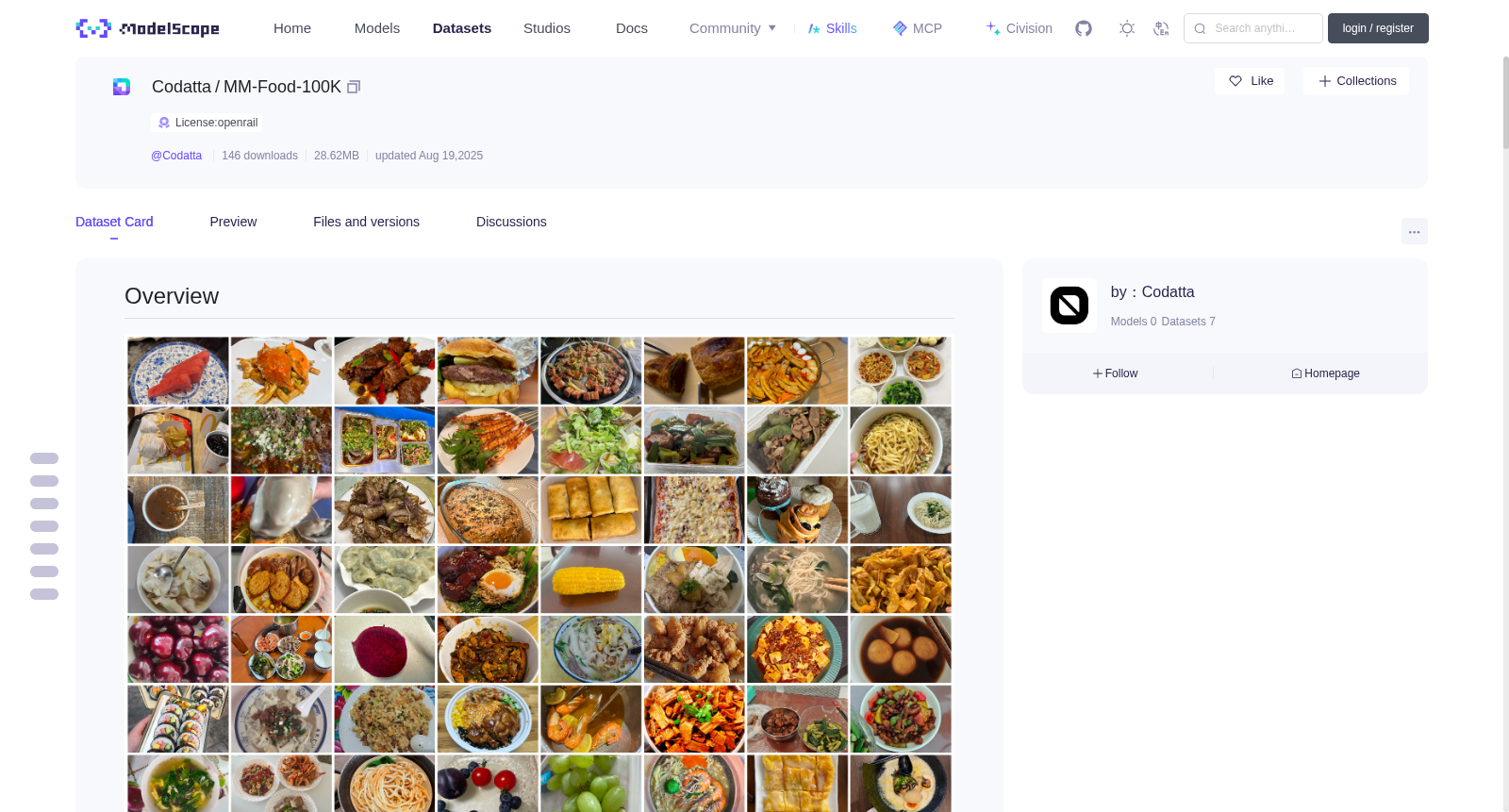
(*Examples of food images with mixed annotations — green cells are human-labeled, red cells are AI-predicted — showing dish details, ingredients, cooking methods, and nutrition.*)
This dataset consists of high-quality food images and detailed metadata, designed for granular food analysis. Unlike traditional datasets that only provide image classification labels, our resource offers multi-level, structured information that supports more complex AI applications. Each data record includes an image URL and corresponding metadata in JSON format, containing the following key fields:
+ `image_url`: A link to the image file.
+ `dish_name`: The main category or dish name of the food, e.g., "Fried Eggs with Toast."
+ `food_type`: Describes the source or context of the food, e.g., "Homemade food," "Restaurant food," etc.
+ `ingredients`: A list of the food's ingredients, e.g., `["eggs", "bread", "olive oil"]`, which provides the basis for ingredient recognition.
+ `portion_size`: The estimated weight of each major ingredient, e.g., `["eggs:100g", "bread:50g"]`. This is crucial for precise nutritional estimation.
+ `nutritional_profile`: Detailed nutritional information presented in JSON format, including `calories_kcal` (calories), `protein_g` (protein), `fat_g` (fat), and `carbohydrate_g` (carbohydrates).
+ `cooking_method`: The method used to cook the food, e.g., "Frying" or "Stir-frying," which is essential for understanding the food preparation process.
+ `camera_or_phone_prob` & `online_download_prob`: Probability values indicating the image source (user-taken photo vs. online download), which helps in assessing data authenticity.
+ `food_prob`: A probability value indicating that the image contains food, ensuring the validity of the data.
This multi-modal data structure, which combines images with in-depth information on ingredients, weight, nutrition, and cooking methods, makes it a core resource for training the next generation of AI nutritional analysis models and health management applications.
## Key Statistics
Preliminary statistics for this dataset demonstrate its scale and diversity:
+ **Number of Images**: 100,000 food images.
+ **Distribution of Food Types**:
| <font style="color:rgb(0, 0, 0);">food_type</font> | <font style="color:rgb(0, 0, 0);">cnt</font> |
| --- | --- |
| <font style="color:rgb(0, 0, 0);">Homemade food</font> | <font style="color:rgb(0, 0, 0);">46555</font> |
| <font style="color:rgb(0, 0, 0);">Restaurant food</font> | <font style="color:rgb(0, 0, 0);">35461</font> |
| <font style="color:rgb(0, 0, 0);">Raw vegetables and fruits</font> | <font style="color:rgb(0, 0, 0);">9357</font> |
| <font style="color:rgb(0, 0, 0);">Packaged food</font> | <font style="color:rgb(0, 0, 0);">8354</font> |
| <font style="color:rgb(0, 0, 0);">Others</font> | <font style="color:rgb(0, 0, 0);">273</font> |
+ **Distribution of Camera/Phone Probability:**
| <font style="color:rgb(0, 0, 0);">camera_or_phone_prob</font> | <font style="color:rgb(0, 0, 0);">cnt</font> |
| --- | --- |
| <font style="color:rgb(0, 0, 0);">0.9</font> | <font style="color:rgb(0, 0, 0);">200</font> |
| <font style="color:rgb(0, 0, 0);">0.85</font> | <font style="color:rgb(0, 0, 0);">161</font> |
| <font style="color:rgb(0, 0, 0);">0.8</font> | <font style="color:rgb(0, 0, 0);">47879</font> |
| <font style="color:rgb(0, 0, 0);">0.7</font> | <font style="color:rgb(0, 0, 0);">51629</font> |
| <font style="color:rgb(0, 0, 0);">0.6</font> | <font style="color:rgb(0, 0, 0);">131</font> |
## Data Collection and Annotation Process
We adopted an innovative hybrid annotation process, combining large-scale crowdsourced data, human pre-annotation, and advanced AI models to build this high-quality dataset. The entire process can be divided into three key steps:
1. **Data Collection and Human Pre-annotation:**
a. The dataset images originated from the **Booster** campaign, a collaboration between **Codatta** and **Binance**. Through this event, we obtained **1.2 million** food pictures contributed by nearly **50,000 real users**.
b. After a rigorous cleaning process, we filtered out blurry, low-quality, and non-compliant images, retaining **1 million** high-quality images.
c. Subsequently, a professional human annotation team, comprised of users from the Booster campaign, performed the first round of pre-annotation. This included **region, food name, category, brand, and portion size**, laying a solid foundation for subsequent work.
2. **Multi-model Automated Annotation:**
a. We utilized advanced multimodal models—**GPT-4o** and **Qwen-max-latest**—to perform a deeper level of automated annotation on the pre-annotated images.
b. This step generated more detailed information for each image, including **food name, category, ingredients, cooking method, and calories**.
3. **Human Secondary Evaluation and Quality Control:**
a. To ensure the accuracy of the automated annotations, users from the **Booster campaign** again conducted a **comprehensive secondary evaluation and quality control** of the results from the GPT-4o and Qwen-max-latest models.
b. These users, acting as annotators, reviewed the model outputs one by one, performing detailed comparisons and corrections to ensure the accuracy of all key fields (e.g., ingredients, calories). This step served as the final line of defense for guaranteeing the high quality of the dataset.
This process not only significantly improves efficiency but also, through multiple rounds of human intervention and verification, ensures the dataset's precision and depth, making it suitable for complex tasks like high-accuracy nutritional analysis.
## Usage
This food image dataset is designed to support a wide range of computer vision applications and research:
+ **Food Recognition and Classification**: Training and evaluating deep learning models capable of identifying various food types, even at a granular dish level.
+ **Nutritional Estimation**: Aiding in the estimation of food's nutritional content and dietary analysis by combining image recognition results.
+ **Recipe Recommendation Systems**: Developing smart recipe recommendation systems based on images, for example, suggesting recipes based on photos of user-provided ingredients.
+ **Health Management and Monitoring**: Applications in smart wearables or mobile health apps to help users record and analyze their eating habits.
+ **Restaurant Automation**: Providing visual recognition capabilities for smart restaurants and food delivery robots.
+ **Computer Vision Research**: Offering new challenges and benchmarks for research in areas such as image recognition, object detection, and fine-grained classification.
## License and Open-Source Details
The full version of this dataset contains **1 million** images. Currently, we are open-sourcing a subset of **100,000** data entries to facilitate community research and development.
This dataset is licensed under the **OpenRAIL-M** license and is available for **non-commercial use**. For any commercial use, a separate license must be obtained. For questions regarding licensing, please contact us at **hello@codatta.io**.
## 概述

本项目旨在推出并开源一款专为计算机视觉(Computer Vision)任务设计的综合性食品图像数据集,尤其适用于食品识别、分类及营养分析场景。我们期望该数据集能为研究人员与开发者提供可靠的资源,以推动食品人工智能(Food AI)领域的发展。通过在Hugging Face平台发布,我们希望促进社区协作,加速智能食谱推荐、膳食管理以及健康监测系统等应用的创新。
- **技术报告** - [MM-Food-100K:一款包含10万样本、可溯源的多模态(Multimodal)食品智能数据集](https://huggingface.co/papers/2508.10429)
## 研究动机
记录日常饮食是达成健康目标的关键,但传统的饮食日记往往繁琐乏味。尽管新兴的人工智能应用可通过拍摄照片快速记录膳食,但其准确率仍存在显著不足。现有的AI模型在处理多样化的全球食品时表现欠佳;例如,亚洲菜肴的热量估算错误率可高达76%。即便先进模型也往往无法准确估算分量与营养成分。
| 数据集名称与链接 | 数据规模与标签 | 核心聚焦方向 | 关键特征与局限 | 食品类型(包装与否) |
| --- | --- | --- | --- | --- |
| Food 101 [HuggingFace](https://huggingface.co/datasets/ethz/food101) | 7.58万张图像,101个类别 | 全球食品分类 | 仅包含图像,无营养或分量数据。品类多样但覆盖维度较浅。 | 非预包装 |
| indian_food_images [HuggingFace](https://huggingface.co/datasets/rajistics/indian_food_images) | 5330张图像,20个类别 | 印度食品分类 | 聚焦小众品类,数据集规模较小,仅包含图像。 | 非预包装 |
| chinese_food_caption [HuggingFace](https://huggingface.co/datasets/zmao/chinese_food_caption) | 720张图像,附带文本描述 | 中文食品描述 | 数据集规模极小,未进行分类,以文本为主,无营养或分量数据。 | 非预包装 |
| Food Ingredients and Recipes Dataset with Images [Kaggle](https://www.kaggle.com/datasets/pes12017000148/food-ingredients-and-recipe-dataset-with-images?resource=download) | 1.36万张图像,包含原料与食谱信息 | 食品原料与制备说明 | 从食谱平台爬取所得,聚焦于食品组分,而非直接的营养值或分量。 | 非预包装 |
| Food500Cap [HuggingFace](https://huggingface.co/datasets/advancedcv/Food500Cap) | 1.99万张图像,包含分类与文本描述 | 食品分类与描述 | 与中文食品描述数据集类似但规模更大,无营养或分量数据。 | 非预包装 |
| openfoodfacts_package_weights [HuggingFace](https://huggingface.co/datasets/FoodIntake/openfoodfacts_package_weights) | 45.7万条数据,包含分类、品牌、分量、语言信息 | 来自Open Food Facts的预包装食品数据 | 唯一包含分量数据的数据集,但仅适用于预包装食品。数据为众包(crowdsourced)所得,质量参差不齐。 | 预包装 |
| FoodSeg103 [HuggingFace](https://huggingface.co/datasets/EduardoPacheco/FoodSeg103) | 4980张图像,包含食品分类 | 食品分割(单张图像内多食品识别) | 聚焦于单张图像内的多物品识别,规模较小,无营养或分量数据。 | 非预包装 |
我们对Hugging Face与Kaggle平台上的主流食品数据集进行了详细梳理,发现以下局限:
+ **食品多样性不足**:现有数据集在数量、品类与地理覆盖范围上均不够丰富,与真实应用场景差异显著。
+ **标注信息单一**:标注过于简单,仅聚焦于食品名称分类,未包含分量、营养成分等关键细节。
+ **图像质量脱离实际**:图像往往经过精心筛选,与应用场景中用户随手拍摄的真实照片相去甚远。
这暴露了一个核心问题:我们缺乏更贴合真实应用场景的全面、高质量食品数据集。现有大多数数据集规模较小,通常仅提供图像到食品名称的简单映射,极少提供实际分量与热量等关键信息,导致AI模型难以对复杂的真实膳食实现精准识别。
随着人们愈发关注健康饮食与个性化营养,对能够准确识别与分析食品的AI模型的需求日益增长。尽管现有食品数据集已为该领域的研究奠定了基础,但在多样性、标注粒度与数据规模上仍有提升空间。我们的研发动机在于构建一款规模更大、更具代表性且标注精细的食品数据集,以克服现有资源的局限。
## 数据集内容

(*混合人机标注的食品图像示例:绿色单元格为人工标注,红色单元格为AI预测,展示了菜品详情、原料、烹饪方式与营养信息。*)
本数据集包含高质量食品图像与详细元数据,旨在支持精细化食品分析。与仅提供图像分类标签的传统数据集不同,我们的资源提供多层次结构化信息,可支持更复杂的AI应用。每条数据记录包含图像链接与对应的JSON格式元数据,包含以下关键字段:
+ `image_url`:图像文件的链接。
+ `dish_name`:食品的主类别或菜品名称,例如“吐司煎蛋”。
+ `food_type`:描述食品的来源或场景,例如“自制食品”“餐厅食品”等。
+ `ingredients`:食品的原料列表,例如`["eggs", "bread", "olive oil"]`,为原料识别提供基础。
+ `portion_size`:各主要原料的估算重量,例如`["eggs:100g", "bread:50g"]`,这对精准的营养估算至关重要。
+ `nutritional_profile`:以JSON格式呈现的详细营养信息,包括`calories_kcal`(热量,单位千卡)、`protein_g`(蛋白质,单位克)、`fat_g`(脂肪,单位克)与`carbohydrate_g`(碳水化合物,单位克)。
+ `cooking_method`:食品的烹饪方式,例如“煎制”或“炒制”,这对理解食品制备流程至关重要。
+ `camera_or_phone_prob`与`online_download_prob`:表示图像来源的概率值(用户实拍照片与网络下载照片的概率),有助于评估数据真实性。
+ `food_prob`:表示图像包含食品的概率值,确保数据的有效性。
这种结合图像与原料、分量、营养、烹饪方式等深度信息的多模态数据结构,使其成为训练下一代AI营养分析模型与健康管理应用的核心资源。
## 核心统计数据
本数据集的初步统计数据展现了其规模与多样性:
+ **图像总数**:10万张食品图像。
+ **食品类型分布**:
| 食品类型(food_type) | 样本量(cnt) |
| --- | --- |
| 自制食品 | 46555 |
| 餐厅食品 | 35461 |
| 生鲜果蔬 | 9357 |
| 预包装食品 | 8354 |
| 其他 | 273 |
+ **拍摄/下载概率分布**:
| 拍摄/下载概率(camera_or_phone_prob) | 样本量(cnt) |
| --- | --- |
| 0.9 | 200 |
| 0.85 | 161 |
| 0.8 | 47879 |
| 0.7 | 51629 |
| 0.6 | 131 |
## 数据采集与标注流程
我们采用了创新的混合标注流程,结合大规模众包数据、人工预标注与先进AI模型来构建这款高质量数据集。整个流程可分为三个关键步骤:
1. **数据采集与人工预标注**
a. 本数据集的图像源自**Booster**活动,这是**Codatta**与**Binance**的合作项目。通过该活动,我们收集了近5万名真实用户贡献的120万张食品照片。
b. 经过严格的清洗流程,我们过滤掉模糊、低质量与不合规的图像,保留了100万张高质量图像。
c. 随后,由来自Booster活动的用户组成的专业人工标注团队完成了首轮预标注,包括区域标注、食品名称、分类、品牌与分量,为后续工作奠定了坚实基础。
2. **多模型自动标注**
a. 我们利用先进的多模态模型——**GPT-4o**与**Qwen-max-latest**,对预标注的图像进行更深层次的自动标注。
b. 该步骤为每张图像生成了更详细的信息,包括食品名称、分类、原料、烹饪方式与热量。
3. **人工二次评估与质量控制**
a. 为确保自动标注的准确性,Booster活动的用户再次对GPT-4o与Qwen-max-latest模型的输出结果进行了全面的二次评估与质量控制。
b. 这些用户作为标注者,逐一审核模型输出,进行详细比对与修正,以确保所有关键字段(如原料、热量)的准确性。该步骤是保障数据集高质量的最后一道防线。
该流程不仅显著提升了效率,还通过多轮人工干预与验证,确保了数据集的精度与深度,使其适用于高精度营养分析等复杂任务。
## 应用场景
本食品图像数据集旨在支持广泛的计算机视觉应用与研究:
+ **食品识别与分类**:训练与评估能够识别各类食品(甚至精细到具体菜品)的深度学习模型。
+ **营养估算**:结合图像识别结果,辅助估算食品的营养成分并进行膳食分析。
+ **食谱推荐系统**:开发基于图像的智能食谱推荐系统,例如根据用户上传的原料照片推荐食谱。
+ **健康管理与监测**:应用于智能可穿戴设备或移动健康应用,帮助用户记录并分析饮食习惯。
+ **餐厅自动化**:为智能餐厅与送餐机器人提供视觉识别能力。
+ **计算机视觉研究**:为图像识别、目标检测与细粒度分类等领域的研究提供新的挑战与基准。
## 开源许可与详情
本数据集的完整版本包含100万张图像。目前,我们开源了10万条数据的子集,以助力社区的研究与开发。
本数据集采用**OpenRAIL-M**许可协议,仅可用于非商业用途。如需商业使用,需另行获取许可。有关许可的任何疑问,请联系**hello@codatta.io**。
提供机构:
maas
创建时间:
2025-08-19
搜集汇总
数据集介绍
背景与挑战
背景概述
MM-Food-100K是一个包含10万张高质量食品图像的数据集,每张图像都配有详细的元数据,如食材、分量大小、营养成分和烹饪方法等。该数据集旨在支持食品识别、分类和营养分析等计算机视觉任务,并通过创新的混合标注方法确保了数据的高质量和准确性。
以上内容由遇见数据集搜集并总结生成


