OpenO1-SFT
收藏Hugging Face2024-11-21 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/O1-OPEN/OpenO1-SFT
下载链接
链接失效反馈官方服务:
资源简介:
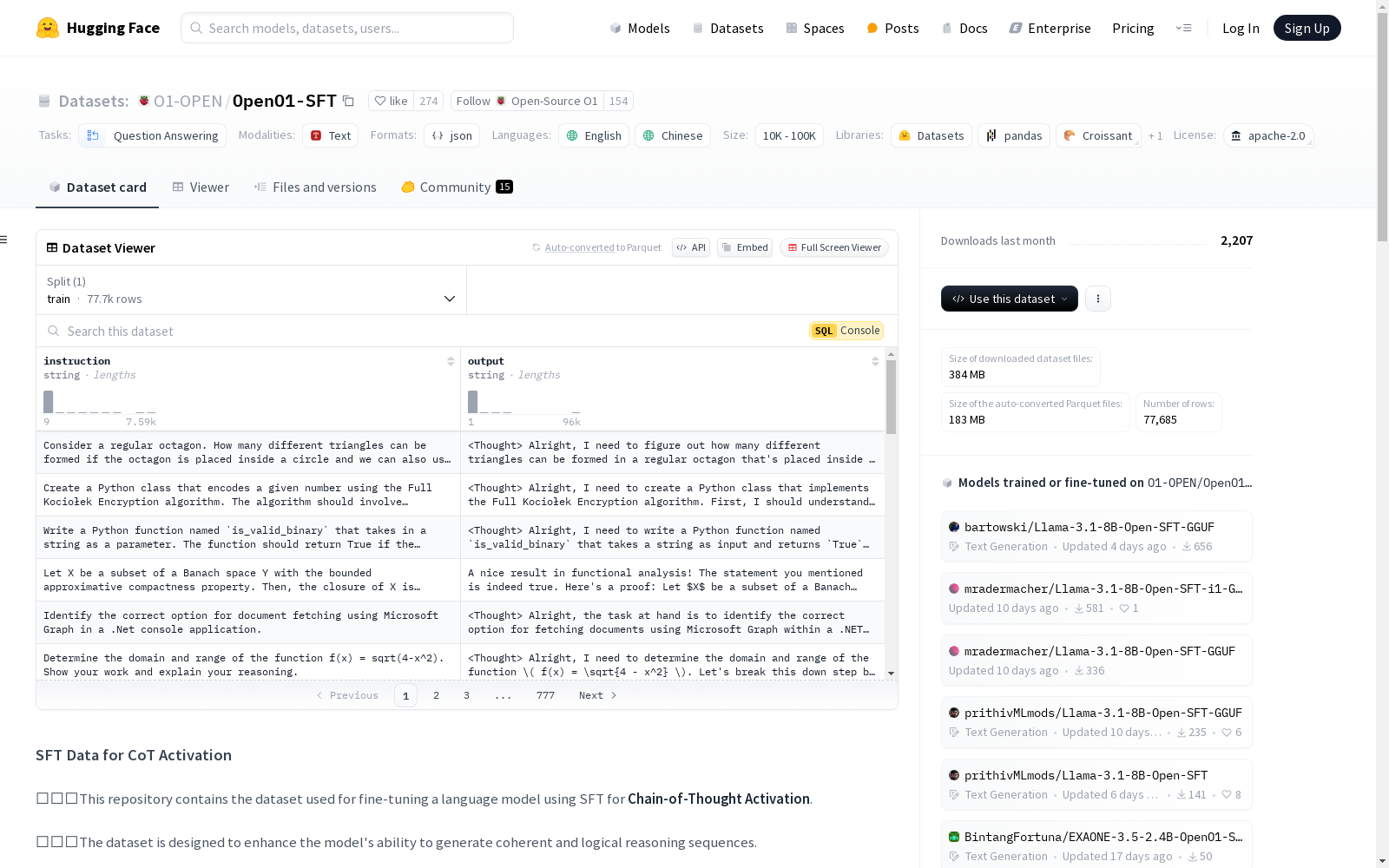
该数据集用于使用SFT对语言模型进行微调,以激活思维链。数据集旨在增强模型生成连贯和逻辑推理序列的能力。它包含77,685条记录,涵盖中文和英文,响应字段使用<Thought> </Thought>和<Output> </Output>分隔符来区分思考过程和最终答案。通过使用此数据集,模型可以学习生成详细和结构化的推理步骤,从而在复杂推理任务中表现更好。
This dataset is designed for fine-tuning language models via Supervised Fine-Tuning (SFT) to activate chain-of-thought reasoning. It aims to enhance the model's capability to generate coherent and logically consistent reasoning sequences. It contains 77,685 records covering both Chinese and English, and the response field uses the delimiters <Thought> </Thought> and <Output> </Output> to distinguish between the thinking process and the final answer. By utilizing this dataset, models can learn to generate detailed and structured reasoning steps, thereby achieving better performance on complex reasoning tasks.
创建时间:
2024-11-21
原始信息汇总
OpenO1-SFT 数据集概述
数据集信息
- 许可证: Apache 2.0
- 任务类别: 问答
- 语言: 中文, 英文
- 数据量: 10K < n < 100K
数据集描述
该数据集用于通过SFT(Supervised Fine-Tuning)激活语言模型的**思维链(Chain-of-Thought Activation)**能力。数据集旨在增强模型生成连贯和逻辑推理序列的能力。通过使用该数据集,模型可以学习生成详细和结构化的推理步骤,从而提高其在复杂推理任务中的表现。
数据集统计
- 总记录数: 77,685
- 语言: 包含中文和英文数据
- 输出格式: 响应字段使用
<Thought> </Thought>和<Output> </Output>分隔符来区分思考过程和最终答案。
性能表现
以下表格展示了在Qwen-2.5-7B-Instruct模型上进行SFT前后的结果对比:
自一致性
| Benchmark | GSM8K | GSM8K | MATH | MATH | MMLU | MMLU | Hellaswag | Hellaswag | ARC-C | ARC-C | BBH | BBH |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen |
| Bo1 | 91.21 | 84.31 | 69.74 | 51.40 | 71.51 | 70.95 | 67.81 | 60.96 | 90.44 | 87.71 | 54.08 | 64.78 |
| Bo2 | 91.21 | 84.31 | 69.74 | 51.40 | 71.51 | 70.95 | 67.81 | 60.96 | 90.44 | 87.71 | 54.08 | 64.78 |
| Bo4 | 91.74 | 88.10 | 71.78 | 57.00 | 71.57 | 73.03 | 68.59 | 63.43 | 90.53 | 88.40 | 55.06 | 68.22 |
| Bo8 | 91.74 | 88.78 | 72.84 | 60.04 | 71.59 | 73.96 | 68.75 | 65.24 | 90.53 | 88.91 | 55.39 | 69.90 |
| Bo16 | 92.12 | 88.93 | 73.78 | 61.72 | 71.56 | 74.03 | 68.78 | 65.24 | 90.53 | 89.33 | 55.43 | 71.23 |
| Bo32 | 92.34 | 89.31 | 74.14 | 62.42 | 71.62 | 74.56 | 68.83 | 65.19 | 90.61 | 89.51 | 55.69 | 71.61 |
| Bo64 | 92.57 | 89.69 | 74.44 | 63.08 | 71.63 | 74.70 | 68.91 | 65.28 | 90.61 | 89.68 | 55.68 | 71.91 |
Oracle pass@k
| Benchmark | GSM8K | GSM8K | MATH | MATH | MMLU | MMLU | Hellaswag | Hellaswag | ARC-C | ARC-C | BBH | BBH |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen | Qwen2.5-7B-instruct | OpenO1-Qwen |
| Bo1 | 91.21 | 84.31 | 69.74 | 51.40 | 71.51 | 70.95 | 67.81 | 60.96 | 90.44 | 87.71 | 54.08 | 64.78 |
| Bo2 | 93.10 | 89.61 | 74.40 | 61.26 | 71.98 | 78.94 | 69.61 | 72.06 | 90.61 | 92.41 | 58.30 | 74.33 |
| Bo4 | 94.84 | 92.49 | 78.34 | 68.46 | 72.41 | 84.31 | 71.26 | 80.28 | 90.78 | 95.05 | 61.01 | 80.29 |
| Bo8 | 95.68 | 94.16 | 81.86 | 73.78 | 72.75 | 88.33 | 72.23 | 85.84 | 90.96 | 96.59 | 63.67 | 83.85 |
| Bo16 | 95.83 | 95.22 | 84.12 | 78.58 | 73.02 | 91.16 | 72.92 | 89.64 | 90.96 | 97.27 | 65.32 | 85.74 |
| Bo32 | 96.44 | 96.13 | 85.72 | 82.48 | 73.19 | 92.98 | 73.46 | 92.47 | 90.96 | 97.78 | 66.79 | 87.01 |
| Bo64 | 96.82 | 96.36 | 87.02 | 85.76 | 73.34 | 94.32 | 73.85 | 94.46 | 90.96 | 98.21 | 67.80 | 88.09 |
搜集汇总
数据集介绍
构建方式
OpenO1-SFT数据集的构建旨在通过监督微调(SFT)技术激活语言模型的链式思维(Chain-of-Thought)能力。该数据集包含77,685条记录,涵盖中英双语,专门设计用于增强模型生成连贯且逻辑严密的推理序列的能力。数据集的构建过程中,特别注重了推理步骤的详细性和结构化,通过使用<Thought>和<Output>标签分隔思维过程和最终答案,确保模型能够学习到复杂的推理任务。
特点
OpenO1-SFT数据集的特点在于其专注于提升语言模型的链式思维能力,使其能够在复杂推理任务中表现出色。数据集不仅包含大量中英双语数据,还通过特定的输出格式(<Thought>和<Output>标签)明确区分思维过程和最终答案,从而帮助模型更好地理解和生成推理步骤。此外,该数据集在多个基准测试中展现了显著的性能提升,尤其是在GSM8K、MATH、MMLU等任务上,验证了其在增强模型推理能力方面的有效性。
使用方法
OpenO1-SFT数据集的使用方法主要围绕监督微调(SFT)技术展开。研究人员可以通过加载该数据集,对预训练的语言模型进行微调,以激活其链式思维能力。在微调过程中,模型将学习如何生成详细的推理步骤,并通过<Thought>和<Output>标签明确区分思维过程和最终答案。该数据集适用于多种复杂推理任务,如数学问题求解、常识推理等,能够显著提升模型在这些任务上的表现。
背景与挑战
背景概述
OpenO1-SFT数据集旨在通过监督微调(SFT)技术激活语言模型的链式思维(Chain-of-Thought, CoT)能力,以提升模型在复杂推理任务中的表现。该数据集由77,685条记录组成,涵盖中英双语,采用<Thought>和<Output>标签分隔推理过程和最终答案。其核心研究问题在于如何通过结构化数据训练,使模型能够生成连贯且逻辑严密的推理序列。该数据集在多个基准测试中展示了显著的性能提升,尤其是在数学推理和常识推理任务中,为自然语言处理领域的推理能力研究提供了重要支持。
当前挑战
OpenO1-SFT数据集在构建和应用过程中面临多重挑战。首先,如何确保数据集中推理步骤的逻辑性和连贯性,尤其是在多语言环境下,需要精细的标注和验证机制。其次,模型在复杂推理任务中的泛化能力仍然有限,尽管数据集在特定任务上表现优异,但在更广泛的场景中可能存在性能波动。此外,数据集的构建依赖于高质量的标注数据,而获取和标注此类数据需要大量的人力和时间成本。最后,如何平衡模型的推理深度与计算效率,也是该数据集在实际应用中需要解决的关键问题。
常用场景
经典使用场景
OpenO1-SFT数据集在自然语言处理领域中被广泛应用于语言模型的微调,特别是在激活链式思维(Chain-of-Thought Activation)方面。该数据集通过提供详细的推理步骤,帮助模型在复杂推理任务中生成连贯且逻辑性强的回答。其经典使用场景包括数学问题求解、常识推理以及多任务语言理解等领域,显著提升了模型在这些任务中的表现。
实际应用
在实际应用中,OpenO1-SFT数据集被广泛用于智能问答系统、教育辅助工具以及自动化客服等领域。通过微调语言模型,这些系统能够生成更加准确和逻辑性强的回答,提升了用户体验和系统效率。例如,在教育领域,该数据集可以帮助开发智能辅导系统,为学生提供详细的解题步骤和推理过程,从而提高学习效果。
衍生相关工作
OpenO1-SFT数据集的推出催生了一系列相关研究工作,特别是在链式思维激活和语言模型微调领域。许多研究基于该数据集开发了新的模型训练方法,进一步提升了模型在复杂推理任务中的表现。此外,该数据集还激发了多语言推理任务的研究,推动了跨语言自然语言处理技术的发展。这些衍生工作为学术界和工业界提供了宝贵的资源和参考。
以上内容由遇见数据集搜集并总结生成


