RACA-PROJECT-MANIFEST
收藏Hugging Face2026-05-11 更新2026-05-12 收录
下载链接:
https://huggingface.co/datasets/depinwang/RACA-PROJECT-MANIFEST
下载链接
链接失效反馈官方服务:
资源简介:
RACA-PROJECT-MANIFEST是Hugging Face上depinwang组织维护的一个中央注册数据集,作为组织内所有数据集的清单或目录,用于跟踪和管理资源。它记录了5个被跟踪的数据集,并包含最后更新时间戳等元数据,用户可通过datasets库加载以编程方式获取组织内数据集的总数信息。该数据集主要服务于数据集管理和发现场景,而非直接用于模型训练或其他机器学习任务。
RACA-PROJECT-MANIFEST is a central registry dataset maintained by the depinwang organization on Hugging Face, serving as a manifest or catalog for all datasets within the organization to track and manage resources. It records 5 tracked datasets and includes metadata such as last update timestamps, allowing users to load it via the datasets library to programmatically obtain the total number of datasets in the organization. This dataset is primarily intended for dataset management and discovery scenarios, rather than direct use in model training or other machine learning tasks.
创建时间:
2026-05-02
原始信息汇总
数据集概述:RACA-PROJECT-MANIFEST
基本信息
- 数据集名称:RACA-PROJECT-MANIFEST
- 许可证:MIT
- 所属组织:depinwang
- 最后更新时间:2026-05-11T15:04:10.866471+00:00
数据集内容
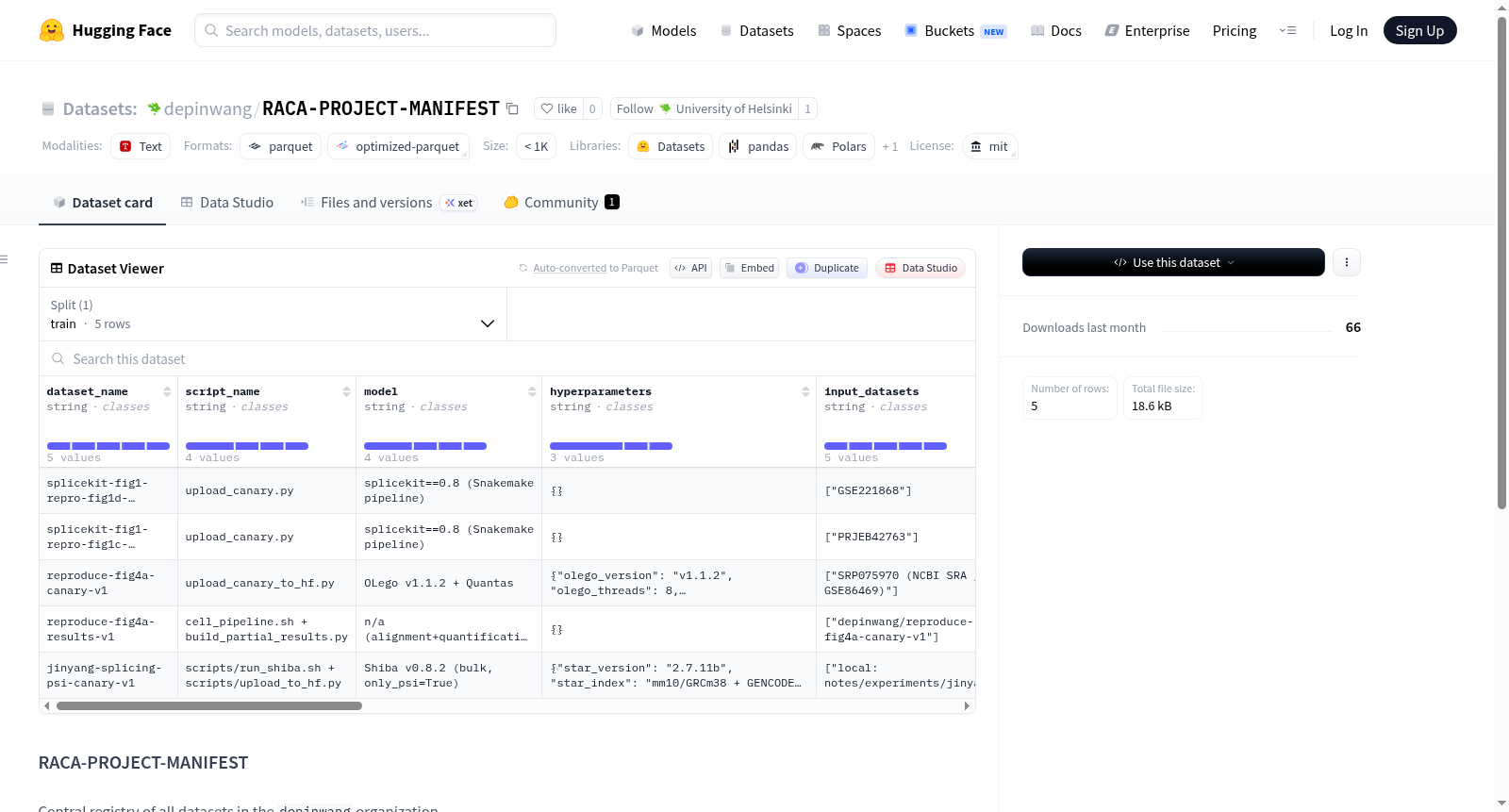
- 功能:作为
depinwang组织下所有数据集的中央注册表。 - 跟踪数据集数量:总计 5 个数据集。
使用方式
- 加载数据集:可通过 Hugging Face
datasets库加载。 - 示例代码: python from datasets import load_dataset manifest = load_dataset("depinwang/RACA-PROJECT-MANIFEST", split="train") print(f"Tracking {len(manifest)} datasets")
搜集汇总
数据集介绍
构建方式
RACA-PROJECT-MANIFEST数据集作为depinwang组织下的核心数据集注册表,承担着汇总与索引该组织所有数据集的枢纽角色。其构建方式旨在实现统一管理与高效查询,通过集中记录五个数据集的元信息,形成一个轻量级、可扩展的中央注册清单。数据集以标准化的Hugging Face数据集格式存储,每条记录对应一个子数据集的标识与属性,并持续更新以反映最新的注册状态。
特点
该数据集最显著的特点在于其作为组织数据资产目录的元数据集身份,而非承载具体业务数据的常规数据集。它提供了对depinwang旗下所有数据集的全局视角与快速访问入口,支持按需加载与动态追踪。凭借极简的结构与明确的版本时间戳,RACA-PROJECT-MANIFEST确保了数据治理的透明度与可追溯性,为跨数据集协作与发现提供了高效的基础设施。
使用方法
使用者可通过Hugging Face的datasets库便捷地加载该注册清单,以编程方式获取depinwang组织内所有数据集的概览。加载示范代码使用'load_dataset'函数指定数据集名称与划分,返回的'manifest'对象可直接用于遍历或统计清单中收录的数据集数量。这一接口设计降低了发现与引用组织内部数据资产的门槛,适合作为数据目录查询的前置步骤或自动化工作流的配置依据。
背景与挑战
背景概述
随着人工智能与去中心化技术的融合日益深入,数据集作为驱动模型性能的关键资源,其标准化管理与跨项目协作的重要性愈发凸显。RACA-PROJECT-MANIFEST由depinwang组织于2026年创建,旨在构建一个统一的数据集注册表,用以追踪和管理该组织旗下的全部数据集资源。截至最新更新,该注册表已涵盖5个数据集,通过提供一个中央化的索引清单,有效解决了多源数据分散、版本混乱及重复引用等瓶颈问题。作为去中心化研究基础设施的基石,该清单提升了数据资产的可见性与可复现性,为相关领域的研究与工程实践提供了结构化的数据管理范式。
当前挑战
该清单所面临的挑战首先体现在领域层面:当前去中心化人工智能项目普遍存在数据集发现困难、元数据标准缺失以及跨平台同步低效等问题,严重制约了模型训练与成果复现的效率。RACA-PROJECT-MANIFEST试图通过集中注册来解决这些痛点,但构建过程中也遭遇了关键挑战,包括如何维护5个动态更新数据集的元数据一致性,如何设计可扩展的索引架构以适应未来数据集数量的激增,以及如何确保注册表信息的实时性与准确性,避免迟滞或冲突对下游依赖造成连锁影响。这些挑战考验着轻量化清单方案的稳健性与长期可持续维护能力。
常用场景
经典使用场景
RACA-PROJECT-MANIFEST作为depinwang组织下所有数据集的中央注册表,其经典使用场景在于为研究人员和开发者提供一个统一的数据集发现与索引平台。通过该清单,用户能够快速获取组织内全部可用数据集的元信息,包括数据集数量、更新状态等关键属性。这极大地简化了多数据集联合实验中的资源管理流程,尤其适用于需要频繁切换或组合不同数据源的复合型研究任务,如多模态学习、跨域迁移学习等。借助HuggingFace的datasets库,一行代码即可加载清单,实现数据集的动态查询与调用,显著提升了科研工作流的效率与可重复性。
衍生相关工作
基于RACA-PROJECT-MANIFEST的理念,社区可以衍生出多种相关工作,如自动化数据溯源系统、跨组织数据联邦目录以及数据集生命周期管理工具。类比于PyPI之于Python包或Docker Hub之于容器镜像,此类集中式清单机制为构建标准化的AI数据供应链奠定了基础。有研究指出,类似的数据集索引方法能够显著改善机器学习实验的复现性,并催生了诸如数据集引用规范、版本语义化等标准化实践。未来,这一范式可进一步扩展至元数据图谱构建,支持基于语义搜索的数据推荐,从而推动从数据孤岛到互联数据生态的转型。
数据集最近研究
最新研究方向
RACA-PROJECT-MANIFEST作为去中心化基础设施网络(DePIN)领域内数据集中央注册表,其最新研究方向聚焦于构建统一的数据集发现与版本管理机制,以应对分布式机器学习中数据碎片化与协作效率低下的挑战。该清单追踪5个数据集,其元数据标准化实践为多源数据融合与跨项目复现提供了基础支撑,尤其在DePIN生态热点事件——如去中心化算力网络与隐私计算协作的兴起中,此类注册表工具成为消除数据孤岛、提升模型训练可复现性的关键基础设施。通过简化数据集索引流程,该清单推动了开源社区从数据积累向知识图谱高效构建的范式转变,为后续可验证数据溯源与联邦学习场景中的资源编排埋下伏笔。
以上内容由遇见数据集搜集并总结生成


