bambara-mt-dataset
收藏Hugging Face2025-06-23 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/MALIBA-AI/bambara-mt-dataset
下载链接
链接失效反馈官方服务:
资源简介:
巴姆巴拉机器翻译数据集是一个全面的平行文本集合,旨在推动巴姆巴拉语的自然语言处理(NLP)发展,特别是针对低资源语言的机器翻译任务。该数据集整合了多个来源,创建了已知最大的巴姆巴拉机器翻译数据集,以支持翻译任务和增强语言可访问性的研究。
创建时间:
2025-06-20
搜集汇总
数据集介绍
构建方式
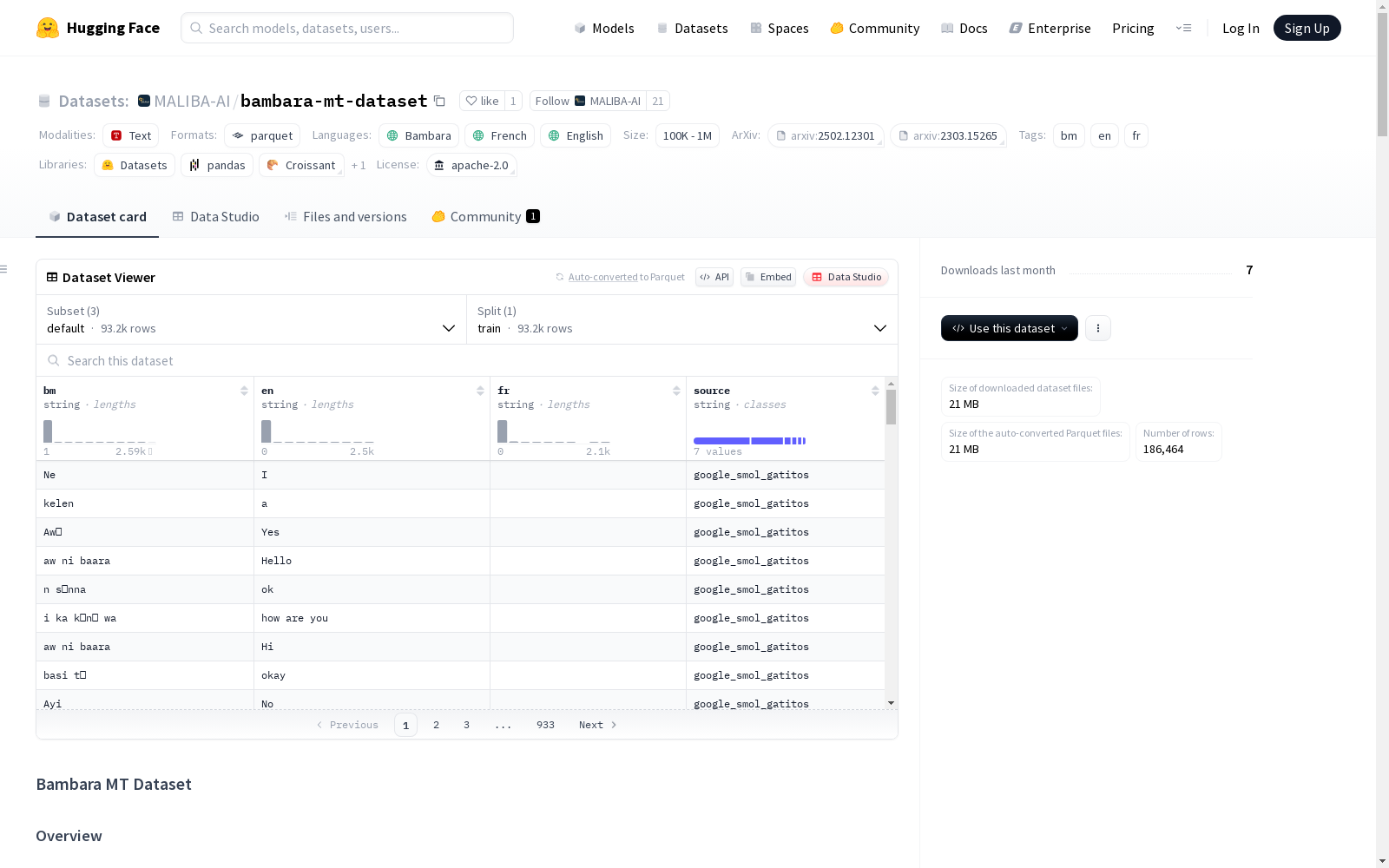
Bambara MT数据集作为低资源语言处理领域的重要资源,其构建过程体现了多源数据整合的严谨性。数据集通过整合来自google/smol、bayelemabaga、EGAFE教育书籍和MAFAND-MT等六个主要来源的平行语料,采用差异化的预处理流程:对于文学文本如《La Guerre des Griots》,提取制表符分隔的双语对并去除未翻译段落;教育类资料则通过Excel表格转换实现多语言映射;新闻领域数据则保留原有分割并统一语言编码。为确保数据质量,构建过程中特别处理了各源数据特有的结构特征,如SMOL数据中文档级与句子级翻译的标准化,最终通过去重合并形成包含班巴拉语-法语和班巴拉语-英语的双向平行语料库。
特点
该数据集最显著的特征在于其覆盖领域的多样性和语言对的完整性。作为目前最大规模的班巴拉语机器翻译数据集,它包含93,232个平行句对,同时提供法语和英语两种目标语言选项。数据来源横跨新闻、文学、教育等多个领域,其中班巴拉语-法语语料达79,528句对,班巴拉语-英语语料含13,704句对。每个条目均标注原始来源,便于研究者追溯数据质量。特别值得注意的是数据集保留了专业翻译的SMOL语料和民间翻译的bayelemabaga语料之间的风格差异,为研究翻译一致性提供了天然实验素材。
使用方法
该数据集的使用需结合其多许可证特性进行合规部署。通过HuggingFace数据集库可快速加载默认配置或指定语言对,加载后的数据采用标准字典结构存储,包含'source'字段用于区分不同来源的语料。研究者可根据需要自行划分训练集与测试集,建议优先采用MAFAND-MT的新闻领域数据作为测试基准以保持领域一致性。对于商业应用场景,需特别注意排除采用CC-BY-4.0-NC许可证的MAFAND-MT数据,而学术研究则可充分利用所有语料开展低资源语言表示学习、多语言模型微调等实验。
背景与挑战
背景概述
Bambara MT数据集由MALIBA-AI团队于2025年发布,旨在解决非洲低资源语言班巴拉语(Bambara)在机器翻译领域的数据稀缺问题。作为马里地区的主要语言之一,班巴拉语在自然语言处理研究中长期面临语料匮乏的困境。该数据集整合了来自Google SMOL、bayelemabaga、EGAFE教育书籍和MAFAND-MT等多个来源的平行文本,构建了目前规模最大的班巴拉语-法语-英语三语对照语料库,涵盖新闻、文学、宗教等多领域文本。其创新性体现在通过融合不同领域和来源的数据,为低资源语言机器翻译模型训练提供了重要基础资源,对促进非洲语言技术公平发展具有显著意义。
当前挑战
该数据集面临的核心挑战主要体现在两个方面:领域应用方面,低资源语言的机器翻译存在数据稀疏性难题,班巴拉语复杂的形态结构和方言变体进一步增加了模型捕捉语言特征的难度;数据构建方面,多源数据的质量参差不齐导致对齐误差,如bayelemabaga源数据标注的错位问题。不同来源的许可协议冲突(如CC-BY-SA-4.0与CC-BY-4.0-NC)限制了数据的商业应用潜力。此外,原始数据中存在的格式异构性(如Excel表格、文本文件、拼接文档)以及专业领域术语(如宗教文献)的准确翻译,都给数据清洗和标准化带来了显著挑战。
常用场景
经典使用场景
在自然语言处理领域,低资源语言的机器翻译一直面临数据稀缺的挑战。Bambara MT数据集通过整合Bambara与法语、英语的平行语料,为这一西非语言构建了迄今为止规模最大的翻译资源库。研究者可利用其多语言对齐特性,开展跨语言迁移学习、低资源神经机器翻译模型优化等核心实验,特别是在处理形态丰富的非洲语言时展现出独特价值。
衍生相关工作
基于该数据集衍生的经典研究包括MALIBA-AI团队开发的BambaraBERT预训练模型,以及Masakhane项目中的多语言翻译系统。在ACL 2023会议上,Adelani等人利用该数据验证了非洲语言翻译中数据增强技术的有效性,而Google SMOL项目则将其作为评估115种低资源语言翻译性能的关键基准之一。
数据集最近研究
最新研究方向
近年来,随着全球自然语言处理领域对低资源语言的日益关注,班巴拉语机器翻译数据集(Bambara MT Dataset)成为研究热点。该数据集整合了班巴拉语与法语、英语的平行文本,为这一西非主要语言的机器翻译模型训练提供了宝贵资源。前沿研究主要聚焦于如何利用跨语言迁移学习技术,将高资源语言模型的参数有效迁移至班巴拉语任务。特别是在预训练模型架构优化方面,学者们探索了基于mBART和NLLB等多语言框架的微调策略,以解决数据稀疏性带来的挑战。同时,该数据集也推动了针对非洲语言特有的形态复杂性和口语化特征的算法创新,为构建更具包容性的多语言NLP生态系统提供了重要支撑。
以上内容由遇见数据集搜集并总结生成


