---
license: cc-by-nc-sa-4.0
task_categories:
- visual-question-answering
- text-generation
language:
- en
size_categories:
- 1K<n<10K
configs:
- config_name: day
data_files:
- split: train
path: "day-train/*"
- split: validation
path: "day-validation/*"
- config_name: night
data_files:
- split: train
path: "night-train/*"
- split: validation
path: "night-validation/*"
---
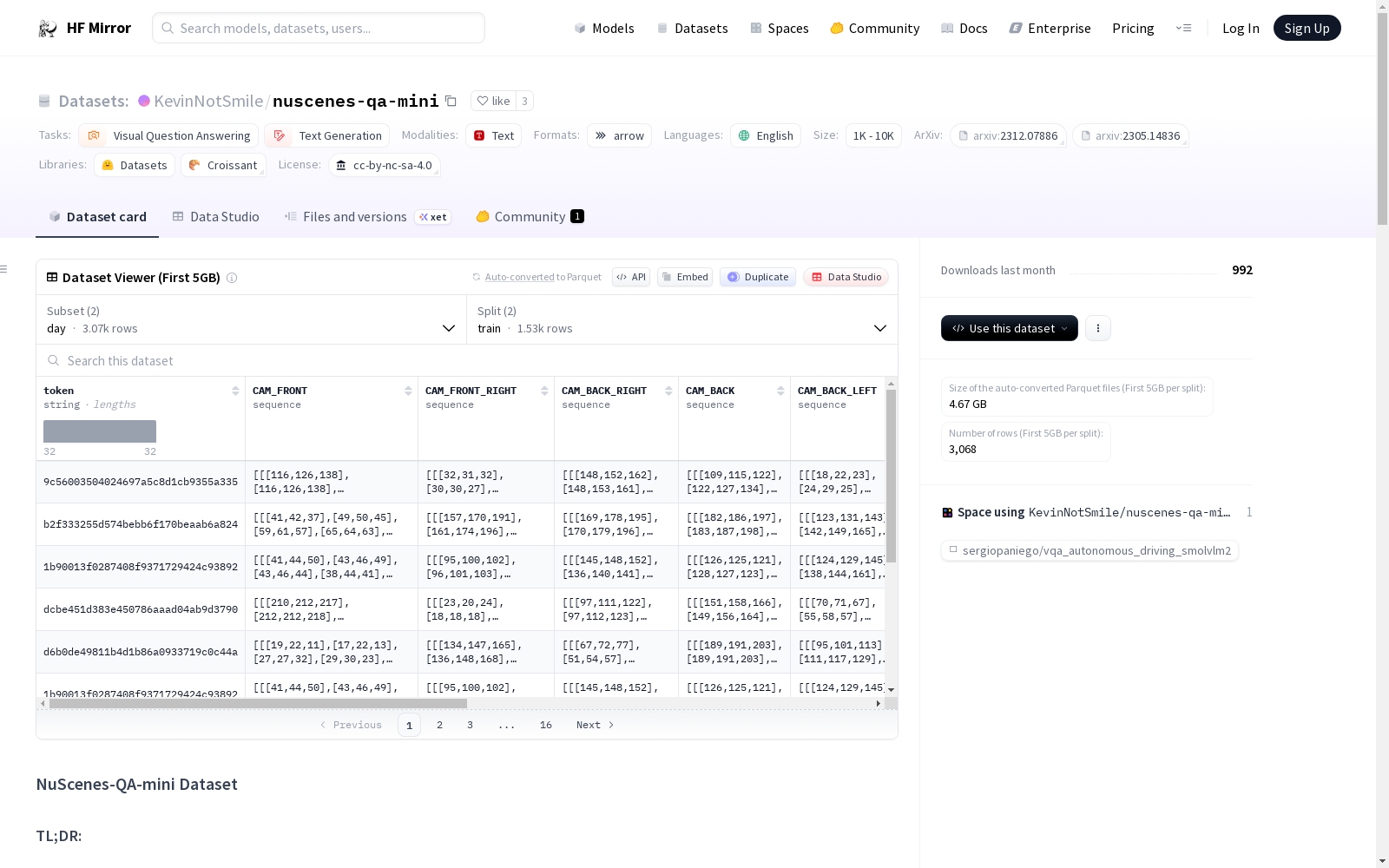
# NuScenes-QA-mini Dataset
## TL;DR:
This dataset is used for multimodal question-answering tasks in autonomous driving scenarios. We created this dataset based on [nuScenes-QA dataset](https://github.com/qiantianwen/NuScenes-QA) for evaluation in our paper [Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI](https://arxiv.org/abs/2312.07886). The samples are divided into day and night scenes.
|scene|# train samples|# validation samples|
|---|---|---|
|day|2,229|2,229|
|night|659|659|
|Each sample contains|
|---|
|original token id in nuscenes database|
|RGB images from 6 views (front, front left, front right, back, back left, back right)|
|5D LiDAR point cloud (distance, intensity, X, Y, and Z axes)|
|question-answer pairs|
## Detailed Description
This dataset is built on the [nuScenes](https://www.nuscenes.org/) mini-split, where we obtain the QA pairs from the original [nuScenes-QA dataset](https://github.com/qiantianwen/NuScenes-QA). The data in the nuScenes-QA dataset is collected from driving scenes in cities of Boston and Singapore with diverse locations, time, and weather conditions.
<img src="nuqa_example.PNG" alt="fig1" width="600"/>
Each data sample contains **6-view RGB camera captures, a 5D LiDAR point cloud, and a corresponding text QA pair**. Each LiDAR point cloud includes 5 dimensions of data about distance, intensity, X, Y, and Z axes. In this dataset, the questions are generally difficult, and may require multiple hops of reasoning over the RGB and LiDAR data. For example, to answer the sample question in the above figure, the ML model needs to first identify in which direction the “construction vehicle” appears, and then counts the number of “parked trucks” in that direction. In our evaluations, we further cast the question-answering (QA) as an open-ended text generation task. This is more challenging than the evaluation setup in the original nuScenes-QA [paper](https://arxiv.org/abs/2305.14836), where an answer set is predefined and the QA task is a classification task over this predefined answer set.
<img src="image_darken.PNG" alt="fig2" width="600"/>
In most RGB images in the nuScenes dataset, as shown in the above figure - Left, the lighting conditions in night scenes are still abundant (e.g., with street lights), and we hence further reduce the brightness of RGB captures in night scenes by 80% and apply Gaussian blur with a radius of 7, as shown in the above figure - Right. By applying such preprocessing to the RGB views in night scenes, we obtain the training and validation splits of night scenes with 659 samples for each split. On the other hand, the RGB views in daytime scenes remain as the origin. The day split contains 2,229 for training and 2,229 for validation respectively.
## How to Use
```py
from datasets import load_dataset
# load train split in day scene
day_train = load_dataset("KevinNotSmile/nuscenes-qa-mini", "day", split="train")
```
## Citation
If you find our dataset useful, please consider citing
```
@inproceedings{caesar2020nuscenes,
title={nuscenes: A multimodal dataset for autonomous driving},
author={Caesar, Holger and Bankiti, Varun and Lang, Alex H and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={11621--11631},
year={2020}
}
@article{qian2023nuscenes,
title={NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario},
author={Qian, Tianwen and Chen, Jingjing and Zhuo, Linhai and Jiao, Yang and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2305.14836},
year={2023}
}
@article{huang2023modality,
title={Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI},
author={Huang, Kai and Yang, Boyuan and Gao, Wei},
journal={arXiv preprint arXiv:2312.07886},
year={2023}
}
```
License
===================================================================================================
[![CC BY-NC-SA 4.0][cc-by-nc-sa-shield]][cc-by-nc-sa]
Being aligned with original nuScenes' license, this work is licensed under a
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
[cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg
license: CC BY-NC-SA 4.0
task_categories:
- 视觉问答(visual-question-answering)
- 文本生成(text-generation)
language:
- 英语(en)
size_categories:
- 1000 < 样本数 < 10000
configs:
- config_name: day
data_files:
- split: train
path: "day-train/*"
- split: validation
path: "day-validation/*"
- config_name: night
data_files:
- split: train
path: "night-train/*"
- split: validation
path: "night-validation/*"
# NuScenes-QA-mini 数据集
## 核心摘要:
本数据集用于自动驾驶场景下的多模态问答任务。我们基于[nuScenes-QA数据集(nuScenes-QA dataset)]构建该数据集,用于我们的论文《Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal Large Language Models for Embodied AI》(arXiv:2312.07886)中的评估工作。数据集样本按日间和夜间场景划分。
|场景|训练样本数|验证样本数|
|---|---|---|
|日间|2229|2229|
|夜间|659|659|
|每个样本包含|
|---|
|nuScenes数据库中的原始Token(Token)ID|
|6个视角的RGB图像(前视、左前视、右前视、后视、左后视、右后视)|
|5D激光雷达(LiDAR)点云(包含距离、强度、X、Y、Z轴共5维数据)|
|问答对|
## 详细描述
本数据集基于[nuScenes迷你拆分集(nuScenes mini-split)]构建,我们从原始[nuScenes-QA数据集(nuScenes-QA dataset)]中获取问答对。nuScenes-QA数据集的数据采集自美国波士顿与新加坡城市中的驾驶场景,涵盖多样的地点、时间与天气条件。
<img src="nuqa_example.PNG" alt="fig1" width="600"/>
每个数据样本包含**6视角RGB相机采集图像、5D激光雷达点云与对应文本问答对**。每个激光雷达点云包含距离、强度、X、Y、Z轴共5维数据。本数据集的问题通常具备一定难度,需对RGB图像与激光雷达数据进行多步推理。例如,要解答上图中的示例问题,机器学习模型需先识别“工程车辆”出现的方向,随后统计该方向内“停放的卡车”的数量。在本研究的评估中,我们将问答任务进一步建模为开放式文本生成任务,这比原始nuScenes-QA论文(arXiv:2305.14836)中的评估设定更具挑战性——原始设定预定义了答案集合,问答任务为基于该集合的分类任务。
<img src="image_darken.PNG" alt="fig2" width="600"/>
如上图左侧所示,nuScenes数据集中的多数RGB图像中,夜间场景仍具备充足光照(例如借助路灯),因此我们进一步将夜间场景的RGB图像亮度降低80%,并施加半径为7的高斯模糊,如上图右侧所示。通过对夜间场景的RGB视角图像应用此类预处理,我们得到了夜间场景的训练与验证拆分集,每个拆分集均包含659个样本。而日间场景的RGB视角图像保持原始状态,日间拆分集的训练集与验证集分别包含2229个样本。
## 使用方法
py
from datasets import load_dataset
# 加载日间场景的训练拆分集
day_train = load_dataset("KevinNotSmile/nuscenes-qa-mini", "day", split="train")
## 引用
若您认为本数据集对您的研究有所帮助,请引用以下文献:
@inproceedings{caesar2020nuscenes,
title={nuscenes: A multimodal dataset for autonomous driving},
author={Caesar, Holger and Bankiti, Varun and Lang, Alex H and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={11621--11631},
year={2020}
}
@article{qian2023nuscenes,
title={NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario},
author={Qian, Tianwen and Chen, Jingjing and Zhuo, Linhai and Jiao, Yang and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2305.14836},
year={2023}
}
@article{huang2023modality,
title={Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI},
author={Huang, Kai and Yang, Boyuan and Gao, Wei},
journal={arXiv preprint arXiv:2312.07886},
year={2023}
}
## 许可协议
[![CC BY-NC-SA 4.0][cc-by-nc-sa-shield]][cc-by-nc-sa]
本数据集遵循与原始nuScenes一致的许可协议,采用[知识共享署名-非商业性使用-相同方式共享4.0国际许可协议(CC BY-NC-SA 4.0)](http://creativecommons.org/licenses/by-nc-sa/4.0/)。
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
[cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg