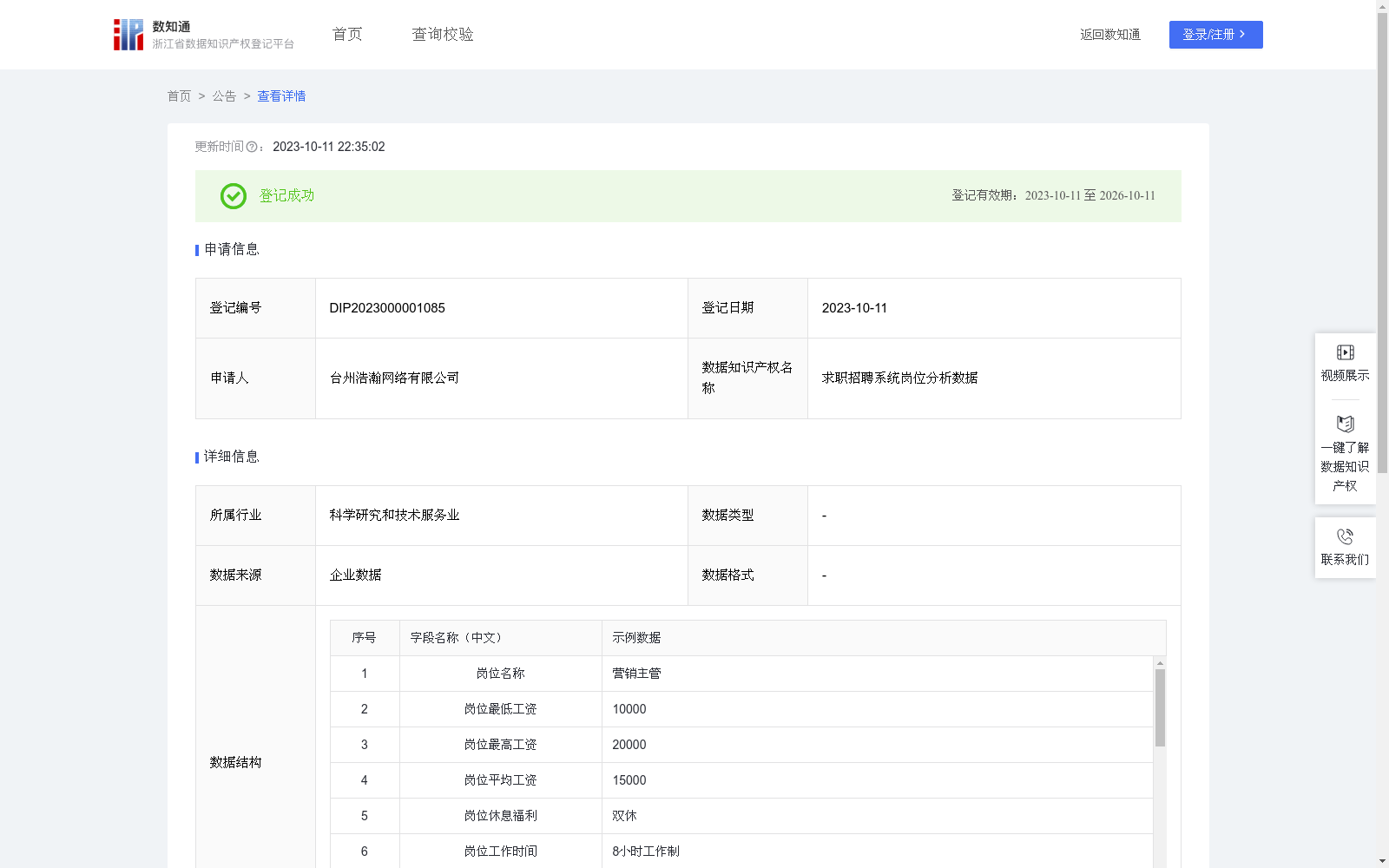
求职招聘系统岗位分析数据
收藏浙江省数据知识产权登记平台2023-10-11 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/4658
下载链接
链接失效反馈官方服务:
资源简介:
通过对地区和岗位类别进行分析,总结出岗位行业分析数据。当企业发布岗位,通过参考岗位行业竞争力分析数据,指导企业发布更有竞争力的岗位信息,招聘到更优秀的求职者。通过公司招聘平台使用BeautifulSoup库解析HTML文档,通过标签、类名、ID等属性来查找特定的元素,将其存储在数据库中。对数据进行清洗和预处理,去重、标准化等,对岗位福利进行分类,重新编码福利ID。计算岗位平均工资,平均工资=(岗位最低工资+最高工资)/2,地区平均工资为本地区该岗位平均工资的平均值,根据公司内部层次评分标准,工资评分:此岗位平均工资在大于该地区此岗位平均工资:工资评分=30*此岗位平均工资/该地区此岗位平均工资;低于该地区此岗位平均工资最低值:0;有无休息福利:双休:20,单双体:15,其他:10;有工作时间福利:8小时:15,两班、三班:10,计件:8,其他:5;有吃饭福利:10,无:0;有住宿福:10,无:0;岗位福利:福利个数(最高15)。对各项指标分值的累加计算该岗位的评价总分,对总分进行IFS函数的判断,岗位评价等级=IFS(总分>=80, "高",总分>=50, "中",总分<50, "低"),阈值为在所有招聘岗位中,将评价分数从高到低进行排序,取前20%的最低分作为“高”阈值,前60%的最低分为“中”阈值。将分析结果通过图表的形式呈现。
This dataset summarizes job position industry analysis data through regional and job category analysis. When enterprises post job openings, they can reference the job industry competitiveness analysis data to guide the release of more competitive job information and recruit more outstanding job seekers. Job posting data is collected via the company's recruitment platform: the BeautifulSoup library is used to parse HTML documents, locate specific elements via tags, class names, IDs and other attributes, and store the parsed data in a database. Subsequently, data cleaning and preprocessing are performed, including deduplication, standardization, classification of job benefits, and re-encoding of benefit IDs. The average job salary is calculated as (job minimum salary + job maximum salary)/2; the regional average salary refers to the mean value of the average salaries of the same job in the corresponding region. According to the company's internal hierarchical scoring criteria, the salary score is calculated as follows: if the job's average salary is higher than the regional average salary of the same job, salary score = 30 * (job average salary / regional average salary of the same job); if the job's average salary is lower than the minimum regional average salary of the same job, salary score = 0. For rest benefits: 20 points for double weekends, 15 points for alternating single and double weekends, and 10 points for other rest arrangements; for working hour benefits: 15 points for 8-hour work shifts, 10 points for two or three shifts, 8 points for piecework, and 5 points for other arrangements; for meal benefits: 10 points if provided, 0 points otherwise; for accommodation benefits: 10 points if provided, 0 points otherwise. The job benefit score is determined by the number of benefits (maximum 15 points). The total evaluation score of the job post is obtained by summing the scores of all indicators. The job post evaluation level is determined via the IFS function: IFS(total score >=80, "High", total score >=50, "Medium", total score <50, "Low"). The thresholds are set based on all recruitment posts: sort the evaluation scores in descending order, take the lowest score of the top 20% as the "High" threshold, and the lowest score of the top 60% as the "Medium" threshold. Finally, the analysis results are presented in the form of charts.
提供机构:
台州浩瀚网络有限公司
创建时间:
2023-09-22
搜集汇总
数据集介绍
特点
该数据集包含2706条求职招聘岗位数据,每周更新,涵盖岗位名称、工资、福利等多个字段,并通过评分系统对岗位进行评价,适用于企业发布岗位时参考行业竞争力分析数据。
以上内容由遇见数据集搜集并总结生成


