求职招聘系统岗位简历匹配数据
收藏浙江省数据知识产权登记平台2023-10-28 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/7390
下载链接
链接失效反馈官方服务:
资源简介:
通过企业岗位和求职者求职意向的分析,尽享相互匹配推荐,缩短用户搜索行为路径,直接根据需求推荐合适的简历。通过预设的K‑means算法模型确定出每个数据点与聚类中心的距离,该数据点与聚类中心越相似,则该数据点对应的简历与聚类中心对应的岗位类型的契合程度越高。然后根据契合度高低对待推荐简历进行推荐,可以有效提高简历推荐的成功率。数据采集:从预先存储的简历数据库中,选出若干份简历。
数据处理:提取简历中的预设类别的信息,包括:学历、工作年限、技能、期望薪资等,将预设类别的信息进行标准化处理,形成简历训练数据集。对于文本数据,采用LabelEncoder将预设类别的信息中的文本数据处理为数字信息。对于工作年限、期望薪资等数据,采用min-max标准化(Min-Max Normalization)对此类预设类别的信息进行归一化处理,将数据缩放到0-1之间。
数据分析:采用K-means算法模型分析,先假设已经通过聚类将数据分成了K个簇,对簇中的每个向量,计算其轮廓系数。当轮廓系数取值范围为(-1, 1)时,轮廓系数越接近于1,则聚类效果越好,越接近-1,聚类效果越差,从而确定K的最佳值。从数据集中随机选择K个数据点作为质心。计算每个数据点与这K个质心之间的距离,将其划分给与其距离最近的质心,初步将数据集分为K类。在分好的K个类别中,计算每个类别所属的数据点的中心点作为新的K个质心。直至收敛,生成与聚类中心对应的簇及数据点对应的契合度。距离聚类中心越近的数据点,契合度越高,根据契合度高低对待推荐简历进行推荐。
By analyzing corporate job postings and job seekers' job intentions, this system enables mutual matching and recommendation, shortens users' search behavior paths, and directly recommends suitable resumes based on requirements.
A preset K-means algorithm model is used to calculate the distance between each data point and the cluster centers. The more similar a data point is to a cluster center, the higher the degree of matching between the resume corresponding to this data point and the job type corresponding to the cluster center. Recommendation of resumes to be recommended based on the matching degree can effectively improve the success rate of resume recommendation.
Data Collection: Select several resumes from the pre-stored resume database.
Data Processing: Extract predefined category information from resumes, including educational background, working experience, skills, expected salary, etc., and standardize the predefined category information to form a resume training dataset. For text data, LabelEncoder is used to convert the text data in the predefined category information into digital values. For data such as working experience and expected salary, Min-Max Normalization is applied to normalize such predefined category information, scaling the data to the range of 0 to 1.
Data Analysis: The K-means algorithm model is adopted for analysis. First, assume that the dataset has been divided into K clusters via clustering, and calculate the silhouette coefficient for each vector within the cluster. The value range of the silhouette coefficient is (-1, 1): the closer the coefficient is to 1, the better the clustering effect; the closer it is to -1, the worse the clustering effect, so the optimal value of K can be determined. Firstly, K data points are randomly selected from the dataset as initial centroids. Then, calculate the distance between each data point and these K centroids, and assign each data point to the nearest centroid to initially divide the dataset into K categories. Next, calculate the centroid of the data points in each of the divided K categories as the new centroids. Repeat the above steps until convergence, generating clusters corresponding to the cluster centers and the matching degree corresponding to each data point. The closer a data point is to the cluster center, the higher its matching degree. Finally, recommend the resumes to be recommended based on their matching degrees.
提供机构:
台州浩瀚网络有限公司
创建时间:
2023-09-27
搜集汇总
数据集介绍
特点
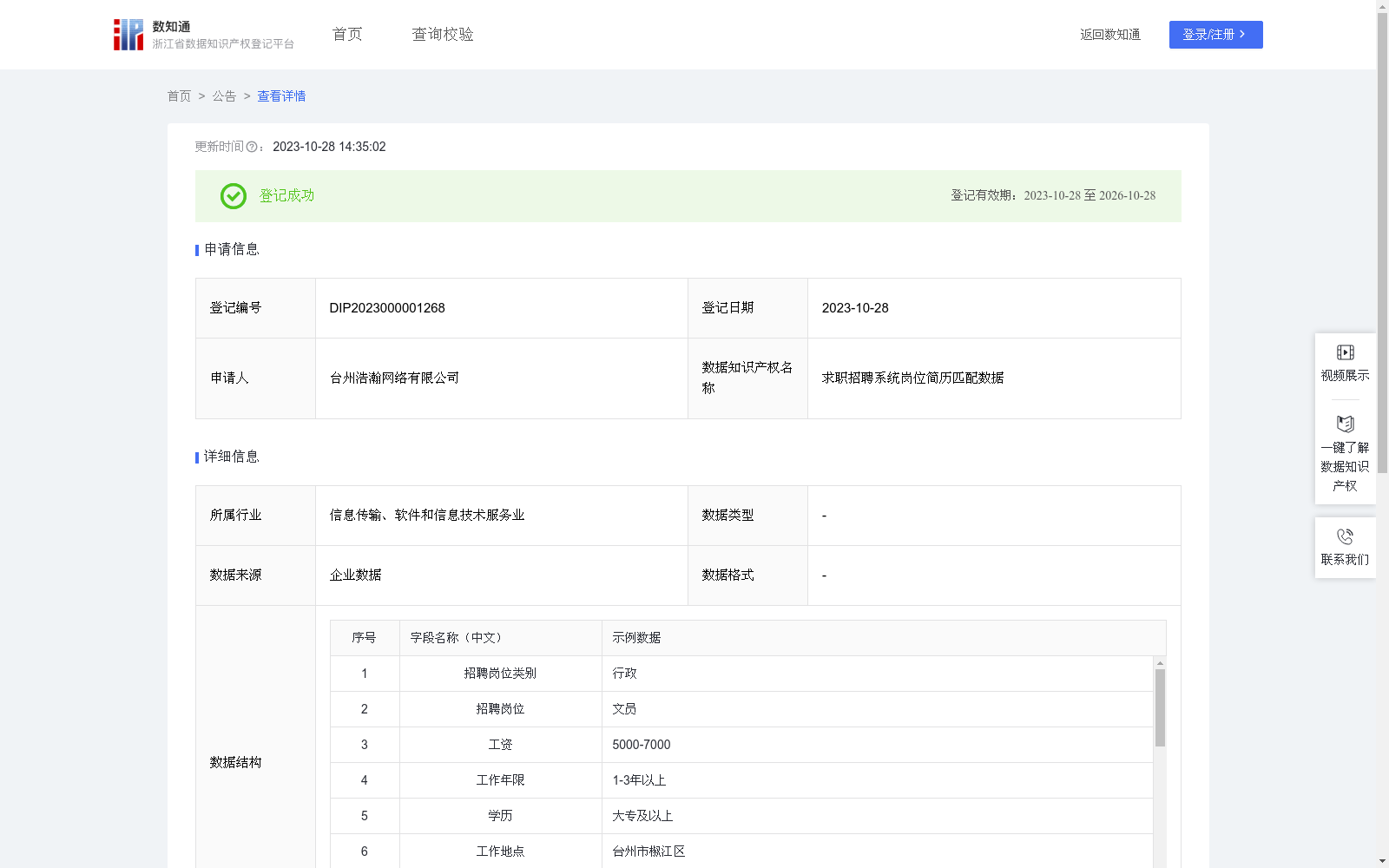
该数据集包含2607条求职招聘系统岗位简历匹配数据,每日更新,主要用于通过K-means算法模型分析企业岗位和求职者求职意向的契合度,实现高效简历推荐。数据涵盖招聘岗位类别、工资、工作年限、学历、技能要求等关键字段,适用于信息传输、软件和信息技术服务业。
以上内容由遇见数据集搜集并总结生成


