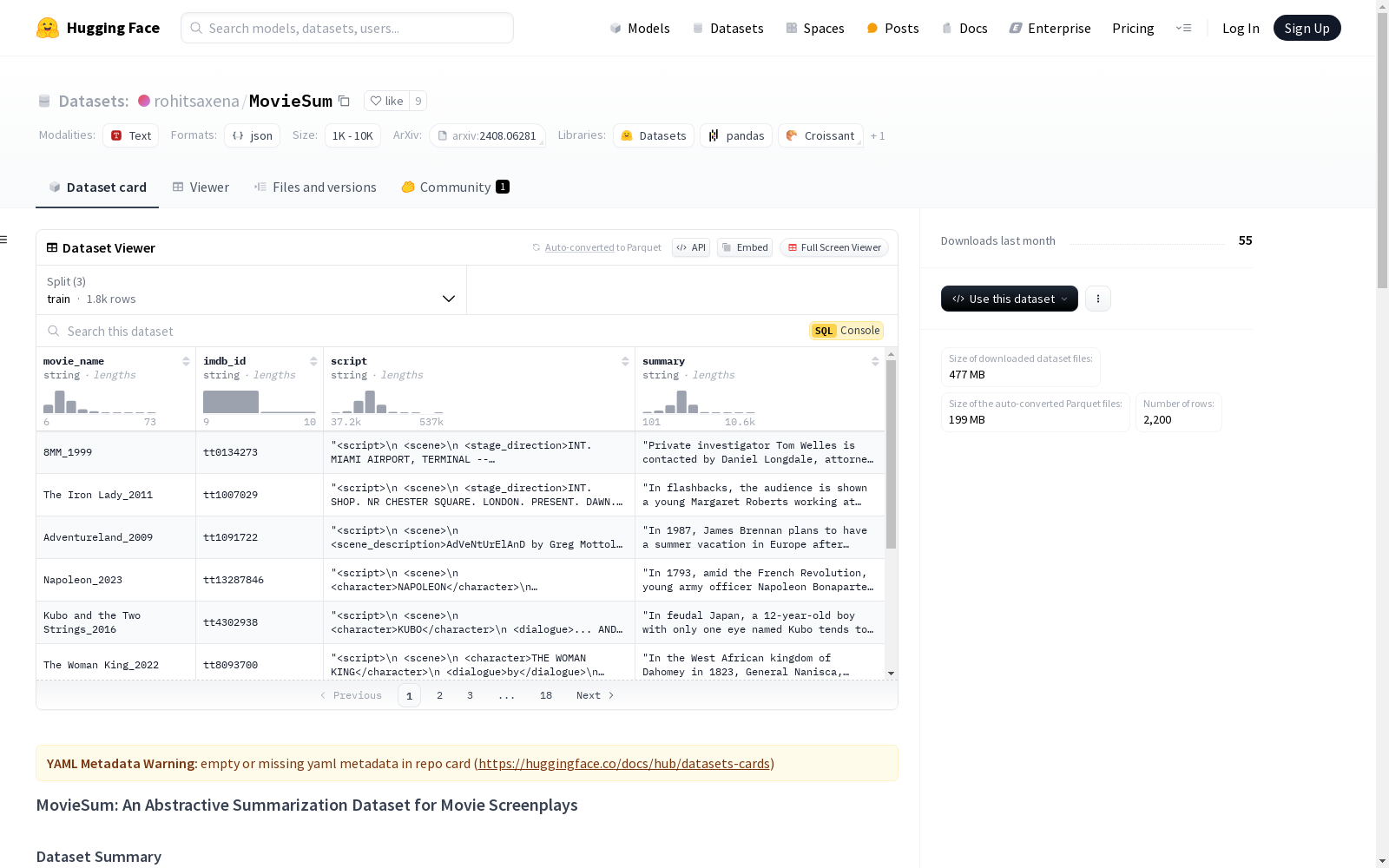
MovieSum
收藏MovieSum: An Abstractive Summarization Dataset for Movie Screenplays
数据集概述
MovieSum 包含 2,200 部电影剧本及其对应的维基百科摘要。这是一个长篇摘要任务,电影剧本的平均长度约为 34,000 字。我们手动格式化了电影剧本,以表示其结构元素。我们还提供了每个电影的 IMDB ID,以便于收集额外的元数据。
数据集统计
| 总电影剧本数 | 2,200 |
| 平均剧本长度 | 34,275 |
| 平均摘要长度 | 793 |
每个电影剧本以 XML 格式提供,具有以下 DOM 结构:
xml <script> <scene> <stage_direction>..</stage_direction> <scene_description>...</scene_description> <character>..</character> <dialogue>..</dialogue> ... </scene> <scene> ... </scene> <script>
数据集结构
数据集分为三个部分:
- 训练集:1800 部电影剧本、摘要和 IMDB ID。
- 验证集:200 部电影剧本、摘要和 IMDB ID。
- 测试集:200 部电影剧本、摘要和 IMDB ID。
许可证
Creative Commons Attribution Non Commercial 4.0
引用
plaintext
@inproceedings{saxena-keller-2024-moviesum,
title = "MovieSum: An Abstractive Summarization Dataset for Movie Screenplays",
author = "Saxena, Rohit and
Keller, Frank",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
month = AUG,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
}
@misc{saxena2024moviesumabstractivesummarizationdataset, title={MovieSum: An Abstractive Summarization Dataset for Movie Screenplays}, author={Rohit Saxena and Frank Keller}, year={2024}, eprint={2408.06281}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2408.06281}, }