google/boolq
收藏Hugging Face2024-01-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/google/boolq
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc-by-sa-3.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- natural-language-inference
paperswithcode_id: boolq
pretty_name: BoolQ
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: bool
- name: passage
dtype: string
splits:
- name: train
num_bytes: 5829584
num_examples: 9427
- name: validation
num_bytes: 1998182
num_examples: 3270
download_size: 4942776
dataset_size: 7827766
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for Boolq
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Repository:** https://github.com/google-research-datasets/boolean-questions
- **Paper:** https://arxiv.org/abs/1905.10044
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 8.77 MB
- **Size of the generated dataset:** 7.83 MB
- **Total amount of disk used:** 16.59 MB
### Dataset Summary
BoolQ is a question answering dataset for yes/no questions containing 15942 examples. These questions are naturally
occurring ---they are generated in unprompted and unconstrained settings.
Each example is a triplet of (question, passage, answer), with the title of the page as optional additional context.
The text-pair classification setup is similar to existing natural language inference tasks.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 8.77 MB
- **Size of the generated dataset:** 7.83 MB
- **Total amount of disk used:** 16.59 MB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"answer": false,
"passage": "\"All biomass goes through at least some of these steps: it needs to be grown, collected, dried, fermented, distilled, and burned...",
"question": "does ethanol take more energy make that produces"
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `question`: a `string` feature.
- `answer`: a `bool` feature.
- `passage`: a `string` feature.
### Data Splits
| name |train|validation|
|-------|----:|---------:|
|default| 9427| 3270|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
BoolQ is released under the [Creative Commons Share-Alike 3.0](https://creativecommons.org/licenses/by-sa/3.0/) license.
### Citation Information
```
@inproceedings{clark2019boolq,
title = {BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions},
author = {Clark, Christopher and Lee, Kenton and Chang, Ming-Wei, and Kwiatkowski, Tom and Collins, Michael, and Toutanova, Kristina},
booktitle = {NAACL},
year = {2019},
}
```
### Contributions
Thanks to [@lewtun](https://github.com/lewtun), [@lhoestq](https://github.com/lhoestq), [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@albertvillanova](https://github.com/albertvillanova) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 现有公开文本复用
language:
- 英语(en)
license:
- 知识共享署名-相同方式共享3.0协议(cc-by-sa-3.0)
multilinguality:
- 单语言
size_categories:
- 10000 < n < 100000
source_datasets:
- 原创数据集
task_categories:
- 文本分类
task_ids:
- 自然语言推理(Natural Language Inference)
paperswithcode_id: boolq
pretty_name: BoolQ
dataset_info:
features:
- name: 问题(question)
dtype: 字符串
- name: 答案(answer)
dtype: 布尔值
- name: 段落(passage)
dtype: 字符串
splits:
- name: 训练集(train)
num_bytes: 5829584
num_examples: 9427
- name: 验证集(validation)
num_bytes: 1998182
num_examples: 3270
download_size: 4942776
dataset_size: 7827766
configs:
- config_name: 默认配置(default)
data_files:
- split: 训练集(train)
path: data/train-*
- split: 验证集(validation)
path: data/validation-*
# BoolQ数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与基准榜单](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏见讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页:** [更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **代码仓库:** https://github.com/google-research-datasets/boolean-questions
- **论文:** https://arxiv.org/abs/1905.10044
- **联系方式:** [更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集文件大小:** 8.77 MB
- **生成后数据集大小:** 7.83 MB
- **总磁盘占用空间:** 16.59 MB
### 数据集摘要
BoolQ是一款面向是非类问题的问答数据集,共计包含15942条样本。此类问题均为自然生成,即在无提示、无约束的场景下自发产生。
每条样本均为(问题、段落、答案)三元组,可附加页面标题作为可选上下文。该数据集采用文本对分类的任务设定,与现有自然语言推理任务范式高度相似。
### 支持任务与基准榜单
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### 默认配置
- **下载数据集文件大小:** 8.77 MB
- **生成后数据集大小:** 7.83 MB
- **总磁盘占用空间:** 16.59 MB
一条验证集样本示例如下:
该示例过长已被截断:
{
"answer": false,
"passage": ""All biomass goes through at least some of these steps: it needs to be grown, collected, dried, fermented, distilled, and burned...",
"question": "does ethanol take more energy make that produces"
}
### 数据字段
所有数据划分的字段定义保持一致。
#### 默认配置
- `question`:字符串类型特征字段,存储问题文本
- `answer`:布尔类型特征字段,存储是非类答案
- `passage`:字符串类型特征字段,存储参考段落文本
### 数据划分
| 划分名称 | 训练集样本数 | 验证集样本数 |
|-------|----:|---------:|
| 默认配置 | 9427 | 3270 |
## 数据集构建
### 构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化处理
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言文本创作者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注信息
#### 标注流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注人员构成
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息说明
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏见讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可证信息
BoolQ采用知识共享署名-相同方式共享3.0(Creative Commons Share-Alike 3.0)协议发布。
### 引用信息
@inproceedings{clark2019boolq,
title = {BoolQ: 探索自然是非类问题的出人意料难度},
author = {Clark, Christopher and Lee, Kenton and Chang, Ming-Wei, and Kwiatkowski, Tom and Collins, Michael, and Toutanova, Kristina},
booktitle = {北美计算语言学协会会议(NAACL)},
year = {2019},
}
### 贡献致谢
感谢[@lewtun](https://github.com/lewtun)、[@lhoestq](https://github.com/lhoestq)、[@thomwolf](https://github.com/thomwolf)、[@patrickvonplaten](https://github.com/patrickvonplaten)、[@albertvillanova](https://github.com/albertvillanova) 为本数据集的收录提供支持。
提供机构:
google
原始信息汇总
数据集概述
数据集名称: BoolQ
数据集描述: BoolQ是一个包含15,942个例子的问答数据集,专门用于处理yes/no类型的问题。这些问题是在无提示和不受限制的环境中自然产生的。每个例子包含三个部分:问题(question)、段落(passage)和答案(answer)。
语言: 英语(en)
许可证: 知识共享署名-相同方式共享3.0(cc-by-sa-3.0)
多语言性: 单语种
大小分类: 10K<n<100K
源数据集: 原始数据
任务类别: 文本分类
任务ID: 自然语言推理
数据集特征:
- 问题(question): 数据类型为字符串(string)
- 答案(answer): 数据类型为布尔值(bool)
- 段落(passage): 数据类型为字符串(string)
数据分割:
- 训练集(train): 9,427个例子,数据大小为5,829,584字节
- 验证集(validation): 3,270个例子,数据大小为1,998,182字节
下载大小: 4,942,776字节
数据集大小: 7,827,766字节
配置信息:
- 默认配置(default): 数据文件路径包括训练集和验证集,分别位于
data/train-*和data/validation-*。
许可证信息: BoolQ数据集根据Creative Commons Share-Alike 3.0许可证发布。
引用信息:
@inproceedings{clark2019boolq, title = {BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions}, author = {Clark, Christopher and Lee, Kenton and Chang, Ming-Wei, and Kwiatkowski, Tom and Collins, Michael, and Toutanova, Kristina}, booktitle = {NAACL}, year = {2019}, }
贡献者: 感谢@lewtun, @lhoestq, @thomwolf, @patrickvonplaten, @albertvillanova添加此数据集。
搜集汇总
数据集介绍
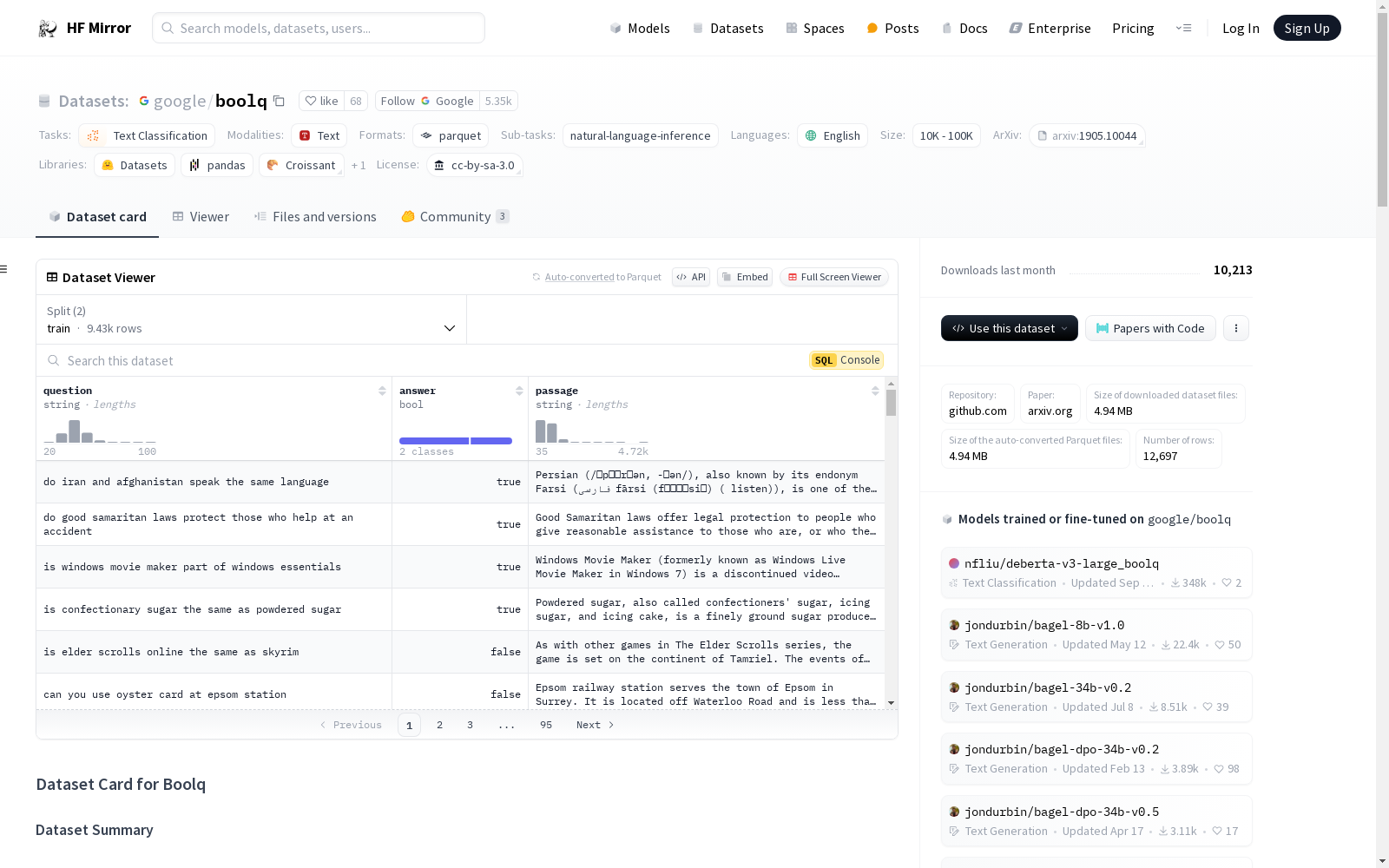
构建方式
BoolQ数据集的构建基于自然发生的yes/no问题,这些问题在不受限制的环境中生成。数据集包含15942个样本,每个样本由一个问题、一个相关段落以及一个布尔答案组成。数据集的构建方式是通过众包方式收集,确保了问题的多样性和自然性。段落通常来自网页内容,提供了丰富的上下文信息,使得问题与答案之间的关联更加紧密。
特点
BoolQ数据集的主要特点在于其问题的自然性和多样性,这些问题并非人为设计,而是从实际应用场景中提取。数据集的结构简洁明了,包含问题、段落和布尔答案三个核心字段,便于模型进行文本分类和自然语言推理任务。此外,数据集的规模适中,包含9427个训练样本和3270个验证样本,适合多种机器学习模型的训练与评估。
使用方法
BoolQ数据集适用于自然语言推理和文本分类任务,尤其适合处理yes/no类型的问题。使用该数据集时,用户可以通过加载数据集的训练和验证集进行模型训练与评估。数据集的结构设计使得模型可以直接从问题和段落中提取特征,预测布尔答案。此外,数据集的许可证为CC-BY-SA-3.0,允许用户在遵守相关条款的前提下自由使用和分享数据。
背景与挑战
背景概述
BoolQ数据集由Google Research团队于2019年创建,旨在探索自然语言推理任务中的自然生成性问题。该数据集包含15,942个自然生成的yes/no问题,每个问题与一段文本相关联,并附有相应的答案。BoolQ的核心研究问题是如何在自然语言推理任务中处理和理解这些自然生成的问题,其目标是为自然语言处理领域提供一个具有挑战性的基准。该数据集的发布对自然语言推理和问答系统的发展产生了重要影响,尤其是在处理非结构化文本和复杂推理任务方面。
当前挑战
BoolQ数据集的主要挑战在于其自然生成的问题具有高度的多样性和复杂性,这使得模型在处理时需要具备较强的推理能力。此外,数据集的构建过程中,如何确保问题的自然性和答案的准确性也是一个重要挑战。由于这些问题是在无约束的环境中生成的,因此可能存在语义模糊或上下文依赖性强的情况,这对模型的理解和推理能力提出了更高的要求。同时,数据集的标注过程依赖于众包,如何确保标注的一致性和质量也是一个需要解决的问题。
常用场景
经典使用场景
BoolQ数据集在自然语言处理领域中,主要用于训练和评估模型在处理自然语言推理任务中的表现。其经典使用场景包括构建和测试问答系统,特别是针对是/否问题的回答能力。通过提供自然生成的问答对,BoolQ帮助模型学习如何从给定的文本段落中提取信息,并准确判断问题的答案。
解决学术问题
BoolQ数据集解决了自然语言推理中的一个关键问题,即如何有效地处理和回答是/否问题。该数据集通过提供大量的自然生成问答对,帮助研究者开发和验证模型在处理这类问题时的准确性和鲁棒性。这对于提升问答系统的实际应用效果具有重要意义,同时也推动了自然语言处理技术的发展。
衍生相关工作
基于BoolQ数据集,研究者们开发了多种自然语言处理模型,并在多个学术会议上发表了相关研究成果。例如,Clark等人(2019)在NAACL会议上提出了BoolQ数据集,并展示了其在自然语言推理任务中的应用。此外,许多后续研究也利用BoolQ数据集进行模型优化和性能评估,进一步推动了问答系统领域的发展。
以上内容由遇见数据集搜集并总结生成


