VisualPuzzles
收藏魔搭社区2025-12-05 更新2025-12-06 收录
下载链接:
https://modelscope.cn/datasets/neulab/VisualPuzzles
下载链接
链接失效反馈官方服务:
资源简介:
# VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
[🏠 Homepage](https://neulab.github.io/VisualPuzzles/) | [📊 VisualPuzzles](https://huggingface.co/datasets/neulab/VisualPuzzles) | [💻 Github](https://github.com/neulab/VisualPuzzles) | [📄 Arxiv](https://arxiv.org/abs/2504.10342) | [📕 PDF](https://arxiv.org/pdf/2504.10342) | [🖥️ Zeno Model Output](https://hub.zenoml.com/project/2e727b03-a677-451a-b714-f2c07ad2b49f/VisualPuzzles)
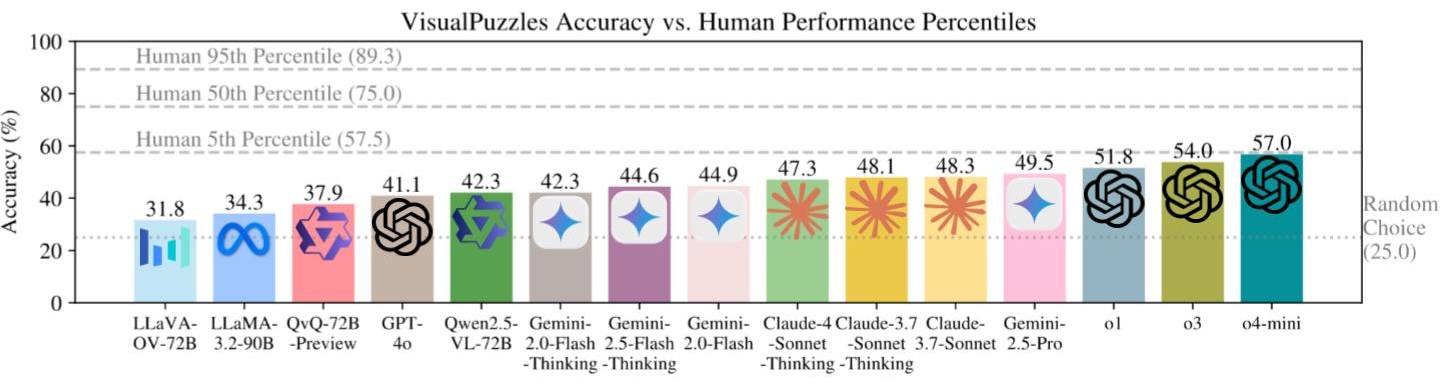
## Overview
**VisualPuzzles** is a multimodal benchmark specifically designed to evaluate **reasoning abilities** in large models while deliberately minimizing reliance on domain-specific knowledge.
Key features:
- 1168 diverse puzzles
- 5 reasoning categories: Algorithmic, Analogical, Deductive, Inductive, Spatial
- Difficulty labels: Easy, Medium, Hard
- Less knowledge-intensive than existing benchmarks (e.g., MMMU)
- More reasoning-complex than existing benchmarks (e.g., MMMU)
## Key Findings
- All models perform worse than humans; most can't surpass even 5th-percentile human performance.
- Strong performance on knowledge-heavy benchmarks does not transfer well.
- Larger models and structured "thinking modes" don't guarantee better results.
- Scaling model size does not ensure stronger reasoning
## Usage
To load this dataset via Hugging Face’s `datasets` library:
```python
from datasets import load_dataset
dataset = load_dataset("neulab/VisualPuzzles")
data = dataset["test"]
sample = data[0]
print("ID:", sample["id"])
print("Category:", sample["category"])
print("Question:", sample["question"])
print("Options:", sample["options"])
print("Answer:", sample["answer"])
```
## Citation
If you use or reference this dataset in your work, please cite:
```bibtex
@article{song2025visualpuzzles,
title = {VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge},
author = {Song, Yueqi and Ou, Tianyue and Kong, Yibo and Li, Zecheng and Neubig, Graham and Yue, Xiang},
year = {2025},
journal = {arXiv preprint arXiv:2504.10342},
url = {https://arxiv.org/abs/2504.10342}
}
```
# VisualPuzzles:将多模态推理评估与领域知识解耦
[🏠 项目主页](https://neulab.github.io/VisualPuzzles/) | [📊 数据集页面](https://huggingface.co/datasets/neulab/VisualPuzzles) | [💻 GitHub 仓库](https://github.com/neulab/VisualPuzzles) | [📄 Arxiv 论文页](https://arxiv.org/abs/2504.10342) | [📕 论文PDF](https://arxiv.org/pdf/2504.10342) | [🖥️ Zeno 模型输出平台](https://hub.zenoml.com/project/2e727b03-a677-451a-b714-f2c07ad2b49f/VisualPuzzles)

## 概述
**VisualPuzzles**是专为评估大语言模型(Large Language Model,LLM)的推理能力而打造的多模态基准测试集,其设计初衷是刻意降低对领域特定知识的依赖。
## 核心特性
- 共包含1168个多样化谜题
- 覆盖5类推理任务:算法推理、类比推理、演绎推理、归纳推理、空间推理
- 设有三级难度标签:简单、中等、困难
- 相较于现有基准测试集(如MMMU),对领域知识的依赖程度更低
- 相较于现有基准测试集(如MMMU),推理复杂度更高
## 核心发现
- 所有模型的表现均劣于人类;多数模型甚至无法达到人类表现的第5百分位水平。
- 在知识密集型基准测试中表现优异的模型,其能力难以向本基准迁移。
- 更大的模型规模与结构化“思考模式”并不能保证获得更优的推理结果。
- 单纯扩大模型参数量并不能确保更强的推理能力。
## 使用方法
通过Hugging Face的`datasets`库加载该数据集的代码如下:
python
from datasets import load_dataset
dataset = load_dataset("neulab/VisualPuzzles")
data = dataset["test"]
sample = data[0]
print("ID:", sample["id"])
print("Category:", sample["category"])
print("Question:", sample["question"])
print("Options:", sample["options"])
print("Answer:", sample["answer"])
## 引用声明
若您在研究工作中使用或引用本数据集,请引用如下文献:
bibtex
@article{song2025visualpuzzles,
title = {VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge},
author = {Song, Yueqi and Ou, Tianyue and Kong, Yibo and Li, Zecheng and Neubig, Graham and Yue, Xiang},
year = {2025},
journal = {arXiv preprint arXiv:2504.10342},
url = {https://arxiv.org/abs/2504.10342}
}
提供机构:
maas
创建时间:
2025-10-10


