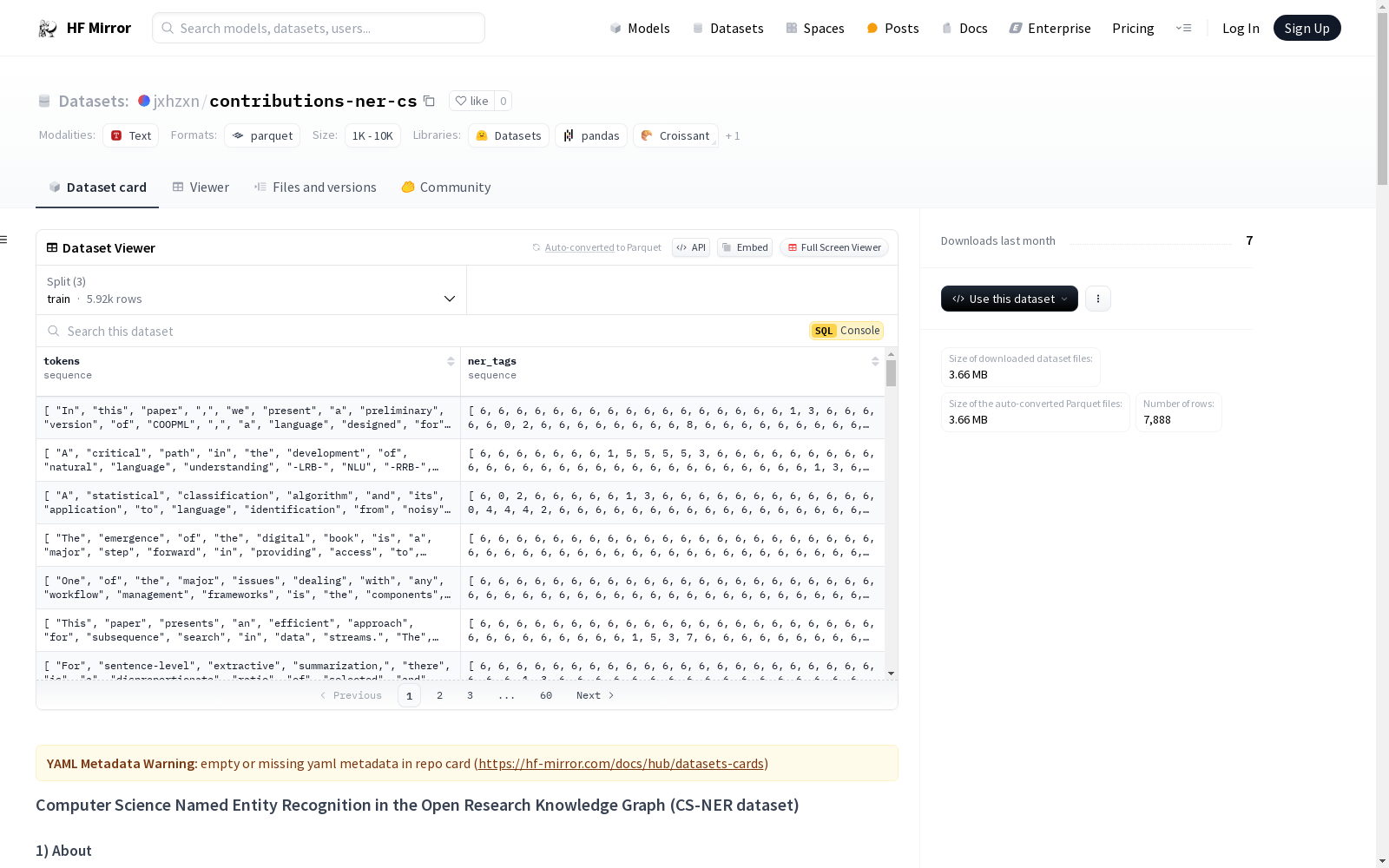
jxhzxn/contributions-ner-cs
收藏Hugging Face2023-03-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jxhzxn/contributions-ner-cs
下载链接
链接失效反馈官方服务:
资源简介:
# Computer Science Named Entity Recognition in the Open Research Knowledge Graph (CS-NER dataset)
### 1) About
This work proposes a standardized CS-NER task by defining a set of seven _contribution-centric_ scholarly
entities for CS NER viz., _research problem_ , _solution_ , _resource_ , _language_ ,
_tool_ , _method_ , and _dataset_ .
The main contributions are:
1) Merges annotations for contribution-centric named entities from related work as the following datasets:
- The dataset proposed in [Analyzing the Dynamics of Research by Extracting Key Aspects of Scientific Papers](https://aclanthology.org/I11-1001/) (Gupta & Manning, IJCNLP 2011) is the source for [ftd](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/ftd), annotated for both titles and abstracts for the following select entities mapped to our standardized types _focus_ -> _solution_ ; _domain_ -> _research problem_ ; and _technique_ -> _method_
- The dataset proposed in [Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction](https://aclanthology.org/D18-1360/) (Luan et al., EMNLP 2018) is the source for [scierc](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/scierc), annotated for abstracts for the following select entities with mappings _task_ -> _research problem_
- The dataset proposed in [SemEval-2021 Task 11: NLPContributionGraph - Structuring Scholarly NLP Contributions for a Research Knowledge Graph](https://aclanthology.org/2021.semeval-1.44/) (D’Souza et al., SemEval 2021) is the source for [ncg](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/ncg), annotated for both titles and abstracts for _research problem_
- https://paperswithcode.com/ as the [pwc](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/pwc) annotated for both titles and abstracts for _task_ -> _research problem_ and _method_ entities.
2) Additionally, supplies a new annotated dataset for the titles in the ACL anthology in the [acl repository](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/acl)
where titles are annotated with all seven entities.
### 2) Dataset Statistics for [full dataset](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/full%20dataset)
Please note the numbers below reflect the total annotated entities. They do not reflect the unique set of annotated entities.
#### Titles
`train.data`
| NER | Count |
| --- | --- |
| solution | 18,924 |
| research problem | 15,646 |
| method | 8,854 |
| resource | 7,346 |
| tool | 1,718 |
| language | 1,141 |
| dataset | 882 |
`dev.data`
| NER | Count |
| --- | --- |
| solution | 1,072 |
| research problem | 989 |
| method | 574 |
| resource | 439 |
| tool | 93 |
| language | 50 |
| dataset | 39 |
`test.data`
| NER | Count |
| --- | --- |
| solution | 8,316 |
| research problem | 4,070 |
| resource | 3,226 |
| method | 2,768 |
| tool | 743 |
| language | 499 |
| dataset | 228 |
#### Abstracts
`train-abs.data`
| NER | Count |
| --- | --- |
| method | 10,992 |
| research problem | 7,485 |
`dev-abs.data`
| NER | Count |
| --- | --- |
| method | 719 |
| research problem | 603 |
`test-abs.data`
| NER | Count |
| --- | --- |
| method | 2,723 |
| research problem | 2,100 |
The remaining repositories have specialized README files with the respective dataset statistics.
### 3) Citation
Accepted for publication in [ICADL 2022](https://icadl.net/icadl2022/) proceedings.
`Citation information forthcoming`
Preprint
```
@article{d2022computer,
title={Computer Science Named Entity Recognition in the Open Research Knowledge Graph},
author={D'Souza, Jennifer and Auer, S{\"o}ren},
journal={arXiv preprint arXiv:2203.14579},
year={2022}
}
```
### 4) Additional resources
#### CS NER Software trained on the dataset in this repository
Codebase: https://gitlab.com/TIBHannover/orkg/nlp/orkg-nlp-experiments/-/tree/master/orkg_cs_ner
Service URL - REST API: https://orkg.org/nlp/api/docs#/annotation/annotates_paper_annotation_csner_post
Service URL - PyPi: https://orkg-nlp-pypi.readthedocs.io/en/latest/services/services.html#cs-ner-computer-science-named-entity-recognition
# 开放研究知识图谱中的计算机科学命名实体识别(Computer Science Named Entity Recognition,简称CS-NER)数据集
### 1) 数据集概况
本工作提出了一项标准化的CS-NER任务,为计算机科学命名实体识别(CS NER)定义了7类**以贡献为中心(contribution-centric)**的学术实体,即:研究问题(research problem)、解决方案(solution)、资源(resource)、语言(language)、工具(tool)、方法(method)以及数据集(dataset)。
本工作的主要贡献如下:
1)整合了现有相关工作中针对以贡献为中心的命名实体的标注数据集,具体包括:
- 论文[Analyzing the Dynamics of Research by Extracting Key Aspects of Scientific Papers](https://aclanthology.org/I11-1001/)(Gupta与Manning,IJCNLP 2011)是[ftd数据集](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/ftd)的数据源,该数据集针对论文标题与摘要进行标注,其选定实体与本工作的标准化类型映射关系为:_focus_ → _solution_;_domain_ → _research problem_;_technique_ → _method_。
- 论文[Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction](https://aclanthology.org/D18-1360/)(Luan等,EMNLP 2018)是[scierc数据集](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/scierc)的数据源,该数据集针对论文摘要进行标注,实体映射关系为:_task_ → _research problem_。
- 论文[SemEval-2021 Task 11: NLPContributionGraph - Structuring Scholarly NLP Contributions for a Research Knowledge Graph](https://aclanthology.org/2021.semeval-1.44/)(D’Souza等,SemEval 2021)是[ncg数据集](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/ncg)的数据源,该数据集针对论文标题与摘要进行标注,标注实体为研究问题(research problem)。
- 网站https://paperswithcode.com/ 作为[pwc数据集](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/pwc)的数据源,针对论文标题与摘要进行标注,实体映射关系为:_task_ → _research problem_ 以及方法(method)实体。
2)此外,本工作还为ACL论文集的标题构建了全新的标注数据集,存储于[acl仓库](https://github.com/jd-coderepos/contributions-ner-cs/tree/main/acl),该数据集的标题覆盖全部7类实体的标注。
### 2) 完整数据集统计信息
请注意:下述数值为标注实体的总数量,而非唯一标注实体的数量。
#### 标题数据
`train.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 解决方案(solution) | 18,924 |
| 研究问题(research problem) | 15,646 |
| 方法(method) | 8,854 |
| 资源(resource) | 7,346 |
| 工具(tool) | 1,718 |
| 语言(language) | 1,141 |
| 数据集(dataset) | 882 |
`dev.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 解决方案(solution) | 1,072 |
| 研究问题(research problem) | 989 |
| 方法(method) | 574 |
| 资源(resource) | 439 |
| 工具(tool) | 93 |
| 语言(language) | 50 |
| 数据集(dataset) | 39 |
`test.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 解决方案(solution) | 8,316 |
| 研究问题(research problem) | 4,070 |
| 资源(resource) | 3,226 |
| 方法(method) | 2,768 |
| 工具(tool) | 743 |
| 语言(language) | 499 |
| 数据集(dataset) | 228 |
#### 摘要数据
`train-abs.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 方法(method) | 10,992 |
| 研究问题(research problem) | 7,485 |
`dev-abs.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 方法(method) | 719 |
| 研究问题(research problem) | 603 |
`test-abs.data`
| 命名实体类型 | 数量 |
| --- | --- |
| 方法(method) | 2,723 |
| 研究问题(research problem) | 2,100 |
其余仓库均附带专属README文件,包含对应数据集的详细统计信息。
### 3) 引用信息
本工作已被接收并将发表于[ICADL 2022](https://icadl.net/icadl2022/)会议论文集。
`引用信息待公布`
预印本
@article{d2022computer,
title={Computer Science Named Entity Recognition in the Open Research Knowledge Graph},
author={D'Souza, Jennifer and Auer, Sören},
journal={arXiv preprint arXiv:2203.14579},
year={2022}
}
### 4) 附加资源
#### 基于本仓库数据集训练的CS-NER软件
代码仓库:https://gitlab.com/TIBHannover/orkg/nlp/orkg-nlp-experiments/-/tree/master/orkg_cs_ner
服务URL - REST API:https://orkg.org/nlp/api/docs#/annotation/annotates_paper_annotation_csner_post
服务URL - PyPi:https://orkg-nlp-pypi.readthedocs.io/en/latest/services/services.html#cs-ner-computer-science-named-entity-recognition
提供机构:
jxhzxn
原始信息汇总
数据集概述
数据集名称
CS-NER数据集(Computer Science Named Entity Recognition in the Open Research Knowledge Graph)
数据集目的
定义并标准化计算机科学领域内的七种贡献中心学术实体,用于命名实体识别任务。
实体类型
- 研究问题
- 解决方案
- 资源
- 语言
- 工具
- 方法
- 数据集
数据集组成
- 源数据集:
- 新增数据集:
- acl:来自ACL anthology,标注了标题中的所有七种实体。
数据集统计
- 标题部分:
train.data:NER Count solution 18,924 research problem 15,646 method 8,854 resource 7,346 tool 1,718 language 1,141 dataset 882 dev.data:NER Count solution 1,072 research problem 989 method 574 resource 439 tool 93 language 50 dataset 39 test.data:NER Count solution 8,316 research problem 4,070 resource 3,226 method 2,768 tool 743 language 499 dataset 228
- 摘要部分:
train-abs.data:NER Count method 10,992 research problem 7,485 dev-abs.data:NER Count method 719 research problem 603 test-abs.data:NER Count method 2,723 research problem 2,100
引用信息
-
预印本:
@article{d2022computer, title={Computer Science Named Entity Recognition in the Open Research Knowledge Graph}, author={DSouza, Jennifer and Auer, S{"o}ren}, journal={arXiv preprint arXiv:2203.14579}, year={2022} }
附加资源
- CS NER软件:基于本数据集训练,提供代码库和服务URL。
搜集汇总
数据集介绍
构建方式
该数据集通过整合多个相关研究中的贡献型命名实体标注数据,构建了一个标准化的计算机科学命名实体识别任务数据集。具体而言,数据集融合了来自不同来源的标注数据,包括Gupta & Manning(2011)、Luan et al.(2018)、D’Souza et al.(2021)以及Papers with Code的数据集,并进行了实体类型的映射与标准化。此外,还新增了对ACL Anthology标题的标注,涵盖了七种核心实体类型。
特点
该数据集的显著特点在于其专注于计算机科学领域的贡献型命名实体识别,定义了七种核心实体类型,包括研究问题、解决方案、资源、语言、工具、方法和数据集。数据集的构建不仅整合了多个来源的标注数据,还通过标准化实体类型,确保了数据的一致性和可比性。此外,数据集提供了丰富的训练、验证和测试数据,涵盖了标题和摘要的标注,为模型训练和评估提供了全面的支持。
使用方法
该数据集可用于训练和评估计算机科学领域的命名实体识别模型。用户可以通过提供的训练、验证和测试数据集进行模型训练和性能评估。此外,数据集还提供了相关的软件工具和API,支持用户在实际应用中进行计算机科学命名实体的自动标注。通过使用该数据集,研究人员和开发者可以构建更加精准的计算机科学知识图谱,提升相关领域的研究效率和质量。
背景与挑战
背景概述
在计算机科学领域,命名实体识别(NER)是构建知识图谱的关键步骤之一。jxhzxn/contributions-ner-cs数据集由Jennifer D'Souza和Sören Auer等研究人员于2022年提出,旨在标准化计算机科学领域的贡献中心命名实体识别任务。该数据集定义了七种核心实体类型,包括研究问题、解决方案、资源、语言、工具、方法和数据集,并通过整合多个相关数据集的标注信息,形成了统一的标注体系。这一数据集的创建不仅为计算机科学领域的研究提供了标准化的标注资源,还为构建开放研究知识图谱(Open Research Knowledge Graph)提供了重要支持。
当前挑战
该数据集在构建过程中面临多项挑战。首先,整合来自不同来源的标注数据,确保实体类型的标准化映射,是一项复杂且耗时的任务。其次,由于不同数据集的标注标准和粒度存在差异,如何统一这些标注以确保数据集的一致性和可用性,是构建过程中的一大难题。此外,数据集的规模和多样性也对模型的训练和评估提出了更高的要求,尤其是在处理长文本和复杂实体关系时,模型的性能和泛化能力面临严峻考验。
常用场景
经典使用场景
jxhzxn/contributions-ner-cs数据集在计算机科学领域中,主要用于命名实体识别(NER)任务,特别是针对学术论文中的贡献相关实体进行标注和识别。该数据集定义了七种核心实体类型,包括研究问题、解决方案、资源、语言、工具、方法和数据集,旨在帮助研究人员从学术论文中提取关键信息,构建知识图谱。通过标注论文的标题和摘要,该数据集为计算机科学领域的NER任务提供了丰富的训练和测试数据。
解决学术问题
该数据集解决了计算机科学领域中命名实体识别的关键问题,特别是在学术论文中提取和标准化贡献相关实体的需求。通过定义和标注七种核心实体类型,该数据集为构建开放研究知识图谱(Open Research Knowledge Graph)提供了基础数据支持,有助于自动化地从大量学术文献中提取结构化信息,进而促进知识图谱的构建和学术研究的智能化分析。
衍生相关工作
基于jxhzxn/contributions-ner-cs数据集,许多相关工作得以展开,特别是在计算机科学领域的命名实体识别和知识图谱构建方面。例如,有研究者利用该数据集开发了专门的NER模型,用于从学术论文中提取关键实体信息。此外,该数据集还激发了多任务学习方法的研究,旨在同时识别实体、关系和共指,进一步推动了科学知识图谱的构建和应用。
以上内容由遇见数据集搜集并总结生成


