NeoRL
收藏arXiv2021-02-08 更新2024-06-21 收录
下载链接:
http://polixir.ai/research/neorl
下载链接
链接失效反馈官方服务:
资源简介:
NeoRL是一个接近真实世界环境的离线强化学习基准数据集,由南京大学国家软件新技术重点实验室和Polixir Technologies共同创建。该数据集包含来自多个领域的数据,如机器人控制、工业控制、金融交易和城市管理,数据量最大可达9999条。NeoRL旨在通过提供受控大小的数据集和额外的测试数据集来验证策略,解决现有离线RL基准与真实世界应用之间的现实差距。数据集的应用领域广泛,旨在解决离线RL在实际系统部署中的安全、成本和伦理问题。
NeoRL is an offline reinforcement learning benchmark dataset that closely approximates real-world environments, co-created by the State Key Laboratory for Novel Software Technology at Nanjing University and Polixir Technologies. This dataset contains data from multiple domains including robot control, industrial control, financial trading and urban management, with a maximum of 9999 samples. NeoRL aims to verify policies by providing datasets with controlled scales and additional test datasets, so as to narrow the reality gap between existing offline RL benchmarks and real-world applications. The dataset has broad application scenarios, and is designed to address the safety, cost and ethical issues of offline RL during real-world system deployment.
提供机构:
中国南京大学国家软件新技术重点实验室
创建时间:
2021-02-01
搜集汇总
数据集介绍
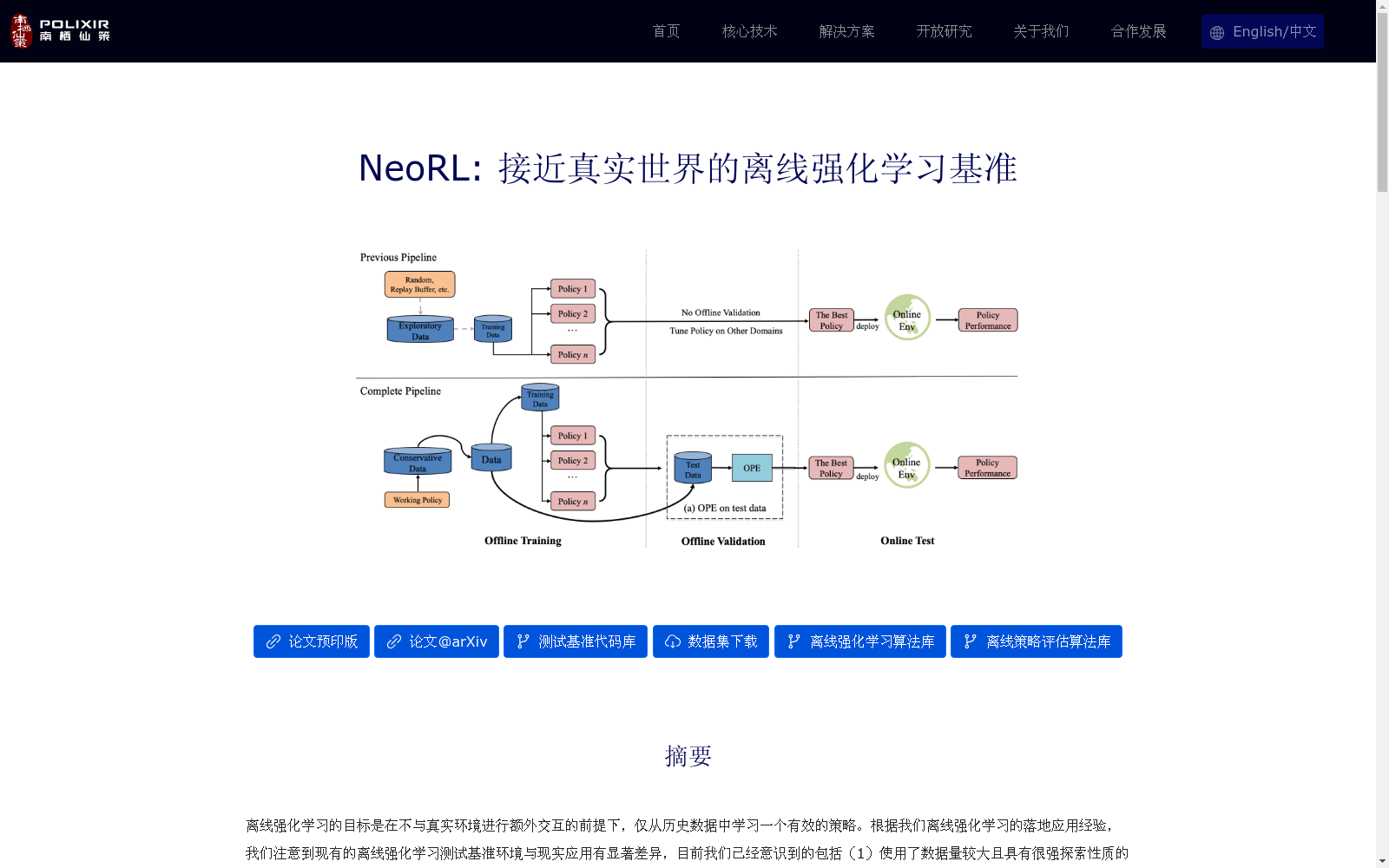
构建方式
NeoRL 数据集的构建方式旨在模拟真实世界的离线强化学习环境。为了缩小现实差距,NeoRL 包含了来自不同领域的小型数据集,并提供了额外的测试数据集以供策略验证。数据集涵盖了机器人、工业控制、金融交易和城市管理等领域,并包含了不同数量和质量的数据,以模拟真实世界中的数据收集情况。此外,NeoRL 还模拟了多级策略,以模拟真实世界中专家和次优策略的差距。
特点
NeoRL 数据集的特点在于其接近真实世界的性质。首先,NeoRL 考虑了保守动作、有限数据、随机动态和离线策略评估等因素,这些都是真实世界决策场景中普遍存在的挑战。其次,NeoRL 提供了多级策略和灵活的数据规模,以模拟真实世界中由领域专家产生的次优策略。此外,NeoRL 还提供了统一的接口,方便研究人员使用和自定义奖励函数。最后,NeoRL 还提供了与确定性策略的比较,以评估离线强化学习算法的有效性。
使用方法
NeoRL 数据集的使用方法包括以下几个方面:首先,研究人员可以使用 NeoRL 提供的统一接口访问数据集,并进行自定义奖励函数。其次,研究人员可以使用 NeoRL 提供的在线和离线评估方法来选择最佳策略和超参数。此外,研究人员还可以使用 NeoRL 提供的额外测试数据集来设计离线评估方法,以评估训练过程中的模型选择和超参数选择。最后,研究人员还可以使用 NeoRL 提供的代码实现和结果分析来参考和改进现有的离线强化学习算法。
背景与挑战
背景概述
强化学习(RL)在计算机视觉和自然语言处理等领域取得了巨大成功,但在真实世界应用中面临着挑战。NeoRL是一个近真实世界离线强化学习基准,旨在解决真实世界中数据收集成本高、数据量有限、环境高度随机等问题。NeoRL包含了来自机器人、工业控制、金融交易和城市管理等多个领域的任务,数据集规模可控,并提供了额外的测试数据集用于策略验证。NeoRL的提出为离线强化学习算法的研究和应用提供了新的思路,有助于推动强化学习在真实世界中的应用。
当前挑战
NeoRL面临的挑战包括:1)数据集构建过程中,如何模拟真实世界中的保守行为、有限数据和高度随机环境;2)离线策略评估方法的选择和改进,以更准确地评估策略的性能;3)模型学习方法的改进,以提高策略在真实世界中的泛化能力。
常用场景
经典使用场景
NeoRL 数据集作为离线强化学习 (RL) 的近真实世界基准,旨在解决离线 RL 算法在现实世界应用中的挑战。该数据集包含来自机器人、工业控制、金融交易和城市管理等多个领域的受控规模数据集,并提供了额外的测试数据集用于策略验证。通过评估现有的离线 RL 算法在 NeoRL 上的表现,该数据集强调了对策略性能的评估应与行为策略的确定性版本进行比较,而非数据集奖励。NeoRL 数据集的构建考虑了保守动作、有限数据、随机动态和离线策略评估等现实世界决策场景中的常见问题,为离线 RL 算法的研究和评估提供了更贴近实际应用的基准。
实际应用
NeoRL 数据集的实际应用场景广泛,包括但不限于机器人控制、工业控制系统优化、金融交易策略设计以及城市管理决策优化等。例如,在机器人控制领域,NeoRL 可以用于训练机器人执行复杂任务,如物体抓取、路径规划等。在工业控制系统优化中,NeoRL 可以用于优化生产流程,提高生产效率。在金融交易策略设计中,NeoRL 可以用于开发更有效的交易策略,提高投资回报。在城市管理决策优化中,NeoRL 可以用于优化交通流量控制、能源消耗管理等。NeoRL 数据集为这些实际应用场景提供了可靠的数据支持,有助于推动相关领域的技术进步。
衍生相关工作
NeoRL 数据集的提出衍生了许多相关的经典工作。首先,它促进了离线 RL 算法的改进和优化,推动了离线 RL 算法在现实世界中的应用。其次,NeoRL 数据集的构建为离线 RL 算法的评估和比较提供了更可靠的基准,有助于推动离线 RL 算法的研究和发展。此外,NeoRL 数据集的提出还推动了离线策略评估方法的研究和发展,为离线 RL 算法的部署提供了更可靠的评估方法。最后,NeoRL 数据集的构建还促进了数据集构建方法的研究和发展,为其他领域的离线学习任务提供了参考和借鉴。NeoRL 数据集的衍生工作为离线 RL 算法的研究和应用提供了重要的支持,有助于推动相关领域的技术进步。
以上内容由遇见数据集搜集并总结生成


