Celeb-DF++
收藏Celeb-DF++: 大规模挑战性视频深度伪造基准数据集
数据集概述
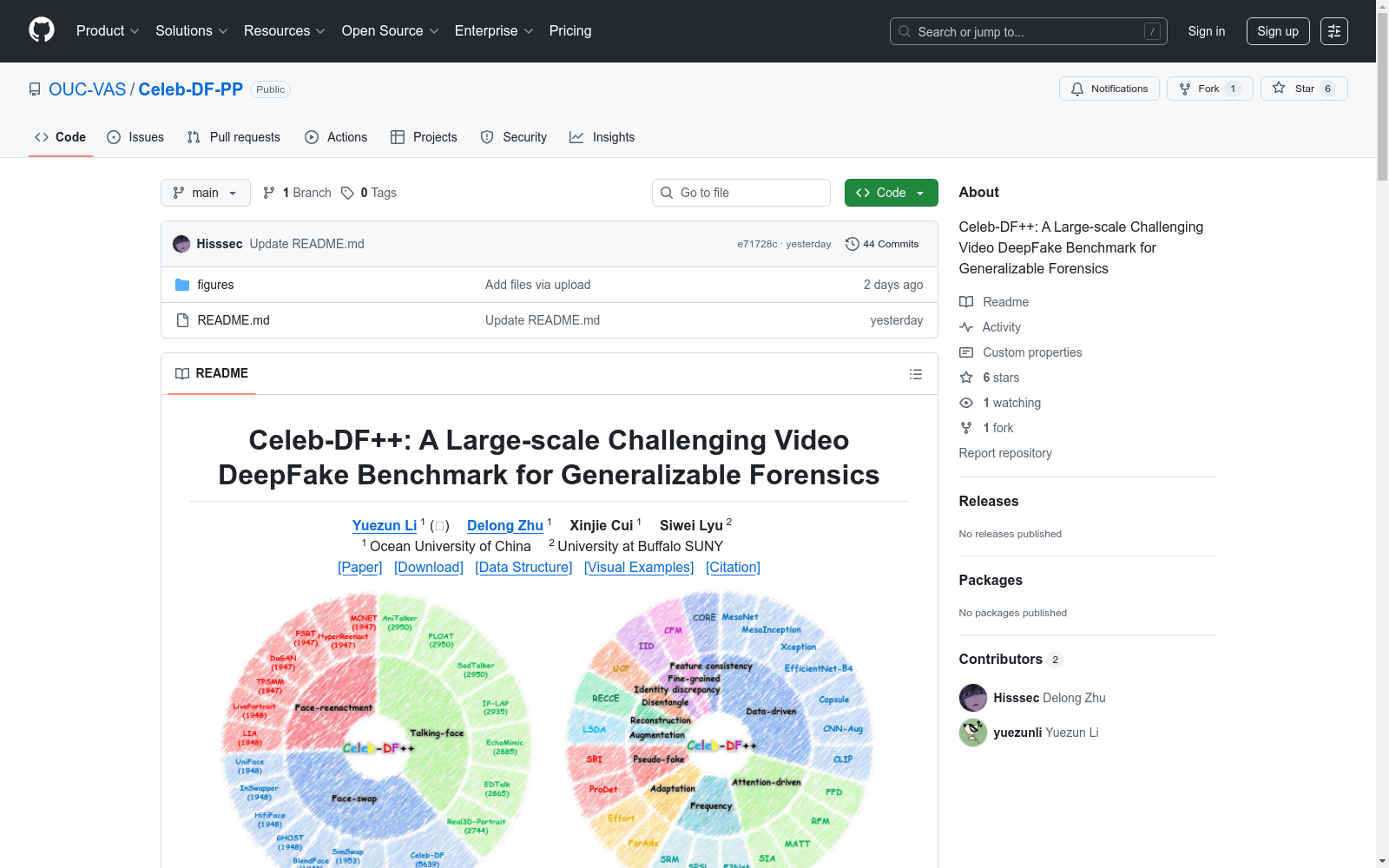
Celeb-DF++是一个针对深度伪造检测的大规模挑战性视频基准数据集,专注于解决通用取证的实际挑战,即使用单一模型检测多种未见过的深度伪造类型。
关键特性
- 多样性:包含22种不同的深度伪造方法,涵盖三种常见场景:
- 人脸替换(Face-swap, FS)
- 人脸重演(Face-reenactment, FR)
- 说话人脸(Talking-face, TF)
- 评估协议:
- 通用伪造评估(GF-eval)
- 跨质量通用伪造评估(GFQ-eval)
- 跨数据集通用伪造评估(GFD-eval)
- 最新评估:包含24种近期检测器的全面评估(其中5种为2024年后发布)。
数据集结构
Celeb-DF++ ├── Celeb-real ├── YouTube-real ├── Celeb-synthesis │ ├── FaceSwap │ │ ├── Celeb-DF │ │ ├── BlendFace │ │ ├── GHOST │ │ ├── HifiFace │ │ ├── InSwapper │ │ ├── MobileFaceSwap │ │ ├── SimSwap │ │ └── UniFace │ ├── FaceReenact │ │ ├── DaGAN │ │ ├── FSRT │ │ ├── HyperReenact │ │ ├── LIA │ │ ├── LivePortrait │ │ ├── MCNET │ │ └── TPSMM │ └── TalkingFace │ ├── AniTalker │ ├── EchoMimic │ ├── EDTalk │ ├── FLOAT │ ├── IP_LAP │ ├── Real3DPortrait │ └── SadTalker └── List_of_testing_videos.txt
训练与测试划分
- 真实测试视频:178个(沿用Celeb-DF的划分)。
- 深度伪造测试视频:
- 人脸替换场景:每种方法200个视频。
- 人脸重演场景:每种方法200个视频。
- 说话人脸场景:每种方法300个视频。
- 详细划分:见
List_of_testing_videos.txt。
下载与使用
- 下载申请:需填写表单。
- 联系方式:liyuezun@ouc.edu.cn。
引用
bibtex @article{li2025celebpp, title={Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics}, author={Li, Yuezun and Zhu, Delong and Cui, Xinjie and Lyu, Siwei}, journal={arXiv preprint arXiv:2507.18015}, year={2025} }
@inproceedings{li2020celeb, title={Celeb-DF: A Large-scale Challenging Dataset for Deepfake Forensics}, author={Li, Yuezun and Yang, Xin and Sun, Pu and Qi, Honggang and Lyu, Siwei}, booktitle={IEEE Conference on Computer Vision and Pattern Recognition}, year={2020} }
隐私声明
数据集按使用条款发布,作者及所属机构不对使用后果负责。
致谢
感谢DeepfakeBench、ForensicsAdapter、Effort、ProDet等开源研究的贡献。