AnyInsertion_V1
收藏Hugging Face2025-05-09 更新2025-05-10 收录
下载链接:
https://huggingface.co/datasets/WensongSong/AnyInsertion_V1
下载链接
链接失效反馈官方服务:
资源简介:
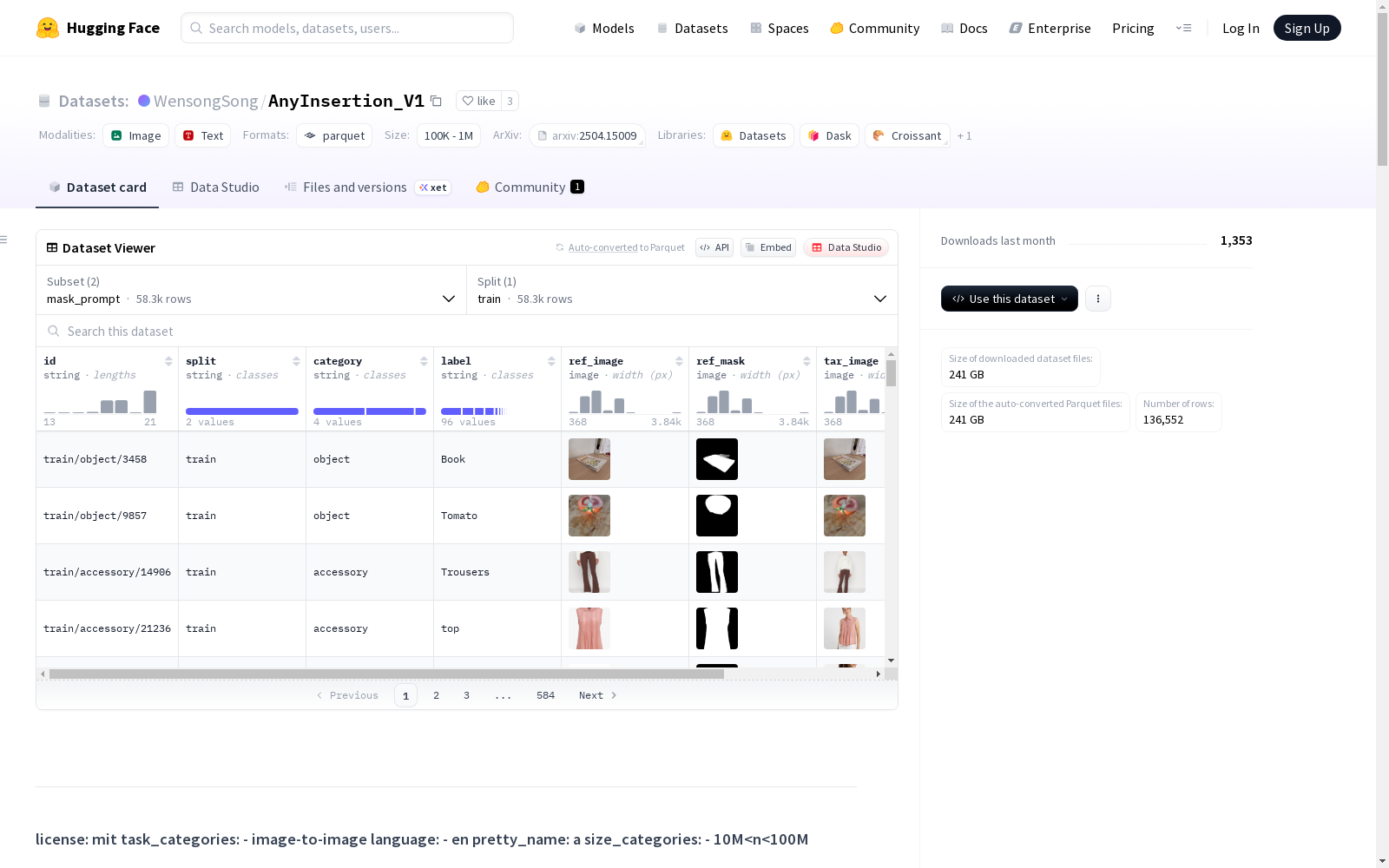
AnyInsertion数据集是我们在论文中提出的数据集,用于图像中的元素插入任务。该数据集包括训练集和测试集,训练集包含两种prompt类型:mask-prompt和text-prompt。mask-prompt包含58,188对图像,text-prompt包含78,197对图像。测试集包含158对数据,其中120对是mask-prompt,38对是text-prompt。数据集覆盖了多种类别,包括人物、日用品、服装、家具等。
创建时间:
2025-05-08
搜集汇总
数据集介绍
构建方式
在计算机视觉与图像生成领域,AnyInsertion_V1数据集通过精心设计的流程构建而成。该数据集包含两种提示类型:掩码提示与文本提示,分别涵盖58318和78234个训练样本。构建过程中,研究人员从多样化场景中采集参考图像与目标图像,并辅以精确的掩码标注,确保每个样本均包含参考元素、掩码区域及编辑后的目标图像。数据组织按照类别分层,涵盖人物、物品及配饰等常见视觉对象,为模型训练提供了丰富的上下文信息。
使用方法
在应用该数据集时,研究人员可通过加载指定的配置文件直接访问掩码提示或文本提示子集。对于掩码提示任务,模型需根据参考图像及其掩码生成目标图像;而文本提示任务则结合自然语言描述引导图像编辑过程。数据集支持常见的深度学习框架,用户可依据目录结构读取图像与掩码数据,并利用提供的标签信息构建训练流程。该设计便于集成到扩散模型等先进架构中,用于研究图像插入、内容替换等生成任务。
背景与挑战
背景概述
在计算机视觉领域,图像编辑技术正经历从传统像素操作到语义级生成的范式转变。AnyInsertion_V1数据集由浙江大学、哈佛大学及南洋理工大学的研究团队于2025年联合发布,旨在解决图像插入任务中的语义一致性与空间适配问题。该数据集通过提供13.6万组包含参考图像、掩码和目标图像的样本,构建了涵盖人物、服饰、家具等多类别的视觉元素插入基准,为扩散变换模型在上下文感知编辑任务中的发展奠定了数据基础。
当前挑战
图像插入任务需克服目标场景光照条件、透视角度与参考元素的几何匹配难题,同时需保持插入物体与背景环境的纹理连贯性。数据集构建过程中面临大规模高质量标注数据的采集瓶颈,特别是在处理复杂遮挡关系时,精确掩码标注需要大量人工校验。多模态提示的协同标注亦增加了数据一致性的维护难度,不同物体类别的形态多样性对数据覆盖广度提出了更高要求。
常用场景
经典使用场景
在计算机视觉领域,AnyInsertion_V1数据集主要应用于图像编辑与生成任务的研究。该数据集通过提供参考图像、掩码图像和目标图像的配对数据,为基于掩码提示和文本提示的图像插入技术奠定了数据基础。研究人员利用这些精心标注的数据对训练深度生成模型,探索在保持图像语义一致性的前提下实现精确的元素插入与替换。
解决学术问题
该数据集有效解决了图像编辑领域中元素插入的精确控制难题。传统方法往往难以在复杂背景下实现自然融合,而AnyInsertion_V1通过提供大规模标注数据,支持研究者开发能够理解空间关系和语义上下文的智能编辑系统。其意义在于推动了基于扩散变换器的图像编辑技术发展,为可控图像生成提供了新的研究范式。
实际应用
在实际应用层面,AnyInsertion_V1数据集支撑的技术已广泛应用于电子商务、虚拟试衣和创意设计等领域。电商平台可利用该技术实现商品的虚拟展示,用户能够直观看到家具摆放效果或服装搭配效果。设计行业则借助此类技术快速生成设计原型,大幅提升创意实现的效率与质量。
数据集最近研究
最新研究方向
在图像生成与编辑领域,AnyInsertion_V1数据集正推动基于扩散变换器的上下文编辑技术迈向新高度。该数据集通过掩码提示与文本提示的双重配置,为多模态图像插入任务提供了结构化基准,涵盖人物、服饰、家具等多样化对象类别。前沿研究聚焦于提升生成图像的语义一致性与空间合理性,探索如何将外部元素无缝融入目标场景。这一方向与当前内容创作自动化的热潮紧密相连,为电子商务、虚拟试衣等实际应用提供了技术支撑,显著推进了可控图像生成的实用化进程。
以上内容由遇见数据集搜集并总结生成


