RegMiner
收藏arXiv2022-07-05 更新2024-06-21 收录
下载链接:
https://regminer.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
RegMiner是由复旦大学开发的一个大型回归数据集,专注于从代码演化历史中自动收集可复现的回归错误。该数据集通过工具RegMiner在8周内从147个项目中收集了1035个回归错误,是目前已知最大的可复现回归数据集。数据集内容丰富,涵盖了多种软件工程和程序语言研究领域,如故障定位、软件测试和程序修复等。创建过程自动化,无需人工干预,确保了数据集的高精度和可接受召回率。应用领域广泛,旨在支持数据驱动的研究,为软件工程和程序语言社区提供了丰富的研究机会。
RegMiner is a large-scale regression dataset developed by Fudan University, which focuses on automatically collecting reproducible regression bugs from code evolution histories. Collected from 147 projects over 8 weeks using the RegMiner tool, this dataset contains 1035 regression bugs, making it the largest known reproducible regression dataset to date. With rich content, the dataset covers multiple research fields in software engineering and programming languages, such as fault localization, software testing, program repair, and more. Its creation process is fully automated without human intervention, ensuring high accuracy and acceptable recall rate of the dataset. It has a wide range of application scenarios, aiming to support data-driven research and provide abundant research opportunities for the software engineering and programming languages communities.
提供机构:
复旦大学中国
创建时间:
2021-09-25
搜集汇总
数据集介绍
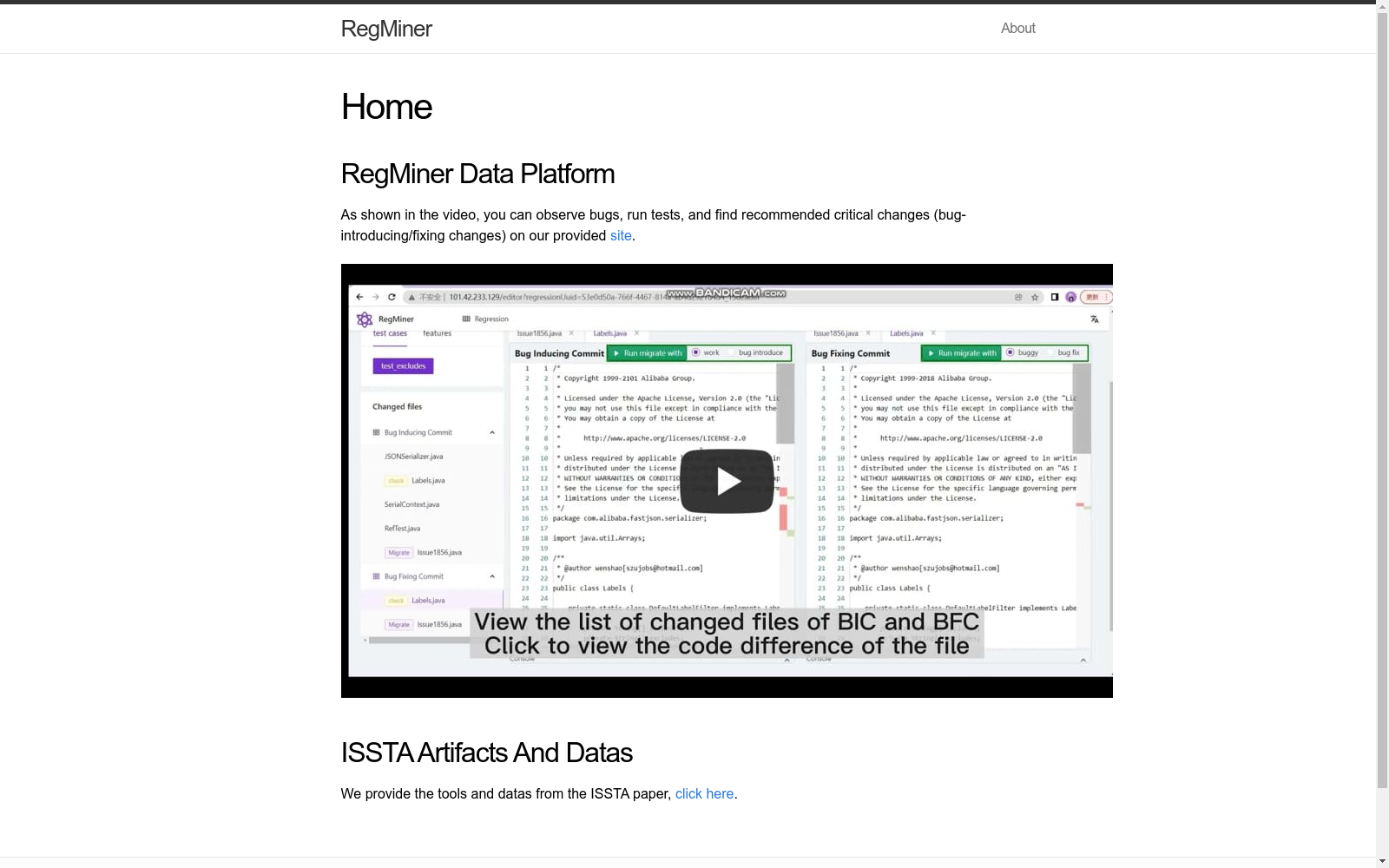
构建方式
在软件工程领域,回归缺陷数据集对于支持故障定位、软件测试和程序修复等研究至关重要。RegMiner数据集通过自动化方法从代码演化历史中挖掘可复现的回归缺陷,其构建过程首先从代码仓库中识别包含测试用例添加的缺陷修复提交,并通过确认测试在修复提交中通过、在修复前提交中失败来验证其作为缺陷修复的有效性。随后,系统利用一种新颖的度量方法量化每个缺陷修复提交成为回归修复提交的潜力,并基于阈值进行排序和筛选,以优先处理高潜力的提交。对于每个候选回归修复提交,工具会沿提交历史搜索回归引入提交,确保指定的测试用例能在回归修复提交和更早的工作提交中通过,而在回归引入提交和修复前提交中失败。整个过程通过精心设计的测试依赖迁移和验证工作量最小化技术,有效应对了历史代码版本兼容性、项目编译开销等挑战,实现了无需人工干预的大规模回归数据集自动化构建。
特点
RegMiner数据集的核心特点在于其规模、真实性和多样性。该数据集在八周内从147个项目中自动挖掘出1035个回归实例,据所知是当前最大的可复现Java回归数据集,显著超越了以往依赖人工构建的数据集在规模上的限制。其真实性通过高精度的挖掘算法得到保障,在封闭实验中达到了100%的精确度;同时,对挖掘结果的定量分析显示,大多数回归实例在回归修复提交和回归引入提交之间具有高特征覆盖相似性,均值达到0.85,表明所捕获的缺陷特征在历史演化中得到了保持。此外,数据集展现出丰富的多样性,涵盖了比经典数据集Defects4j更多的库主题和异常类型,为研究不同场景下的回归缺陷提供了更广泛的样本基础。
使用方法
RegMiner数据集为软件工程社区提供了研究回归分析的基础设施。研究人员可利用该数据集进行回归故障定位、回归测试以及回归解释等领域的实验评估。具体而言,数据集中每个回归实例均以四元组⟨rfc, ric, t, wc⟩形式提供,包含了回归修复提交、回归引入提交、回归测试用例以及更早的工作提交,确保了缺陷上下文和可复现环境的完整性。使用者可以通过数据集提供的访问接口获取每个回归实例的代码仓库版本、测试用例及运行环境,从而在其上运行或验证各种回归分析算法。该数据集支持持续增长,研究者可将其作为基准,系统性地比较不同回归分析技术的性能,或用于训练和评估数据驱动的软件工程模型。
背景与挑战
背景概述
在软件工程领域,回归缺陷数据集对于支持故障定位、软件测试及程序修复等研究具有基础性意义。RegMiner数据集由复旦大学、上海交通大学及新加坡国立大学的研究团队于2022年联合构建,旨在通过自动化方法从代码演化历史中挖掘可复现的回归缺陷,以解决传统人工构建数据集在规模、代表性及对数据驱动研究支持方面的局限。该数据集聚焦于回归缺陷,即导致已有功能失效的软件错误,通过捕获缺陷引入与修复的完整演化轨迹,为回归分析提供了更丰富的语义信息,显著推动了软件测试与调试领域的研究进展。
当前挑战
RegMiner数据集主要应对两大挑战:其一,在领域问题层面,回归缺陷分析需同时处理缺陷版本与历史正常版本,相较于常规缺陷分析更为复杂,要求数据集能精准反映功能失效与修复的演化过程;其二,在构建过程中,面临技术难题包括高效识别潜在的回归修复提交、跨历史版本迁移测试及其代码依赖、以及最小化回归验证过程中的编译与执行开销。这些挑战通过创新的回归潜力评估、测试依赖迁移及验证优化算法得以部分解决,但数据集的召回率与工程支持范围仍有提升空间。
常用场景
经典使用场景
在软件工程领域,回归缺陷分析长期面临高质量数据集匮乏的挑战。RegMiner数据集通过自动化挖掘代码演化历史中的可复现回归缺陷,为回归测试、缺陷定位及程序修复等研究提供了大规模基准。该数据集最经典的使用场景是作为回归缺陷分析的实验平台,研究者可基于其构建的1035个Java回归缺陷实例,系统评估各类回归定位算法(如Delta Debugging变体)在真实场景下的精确度与效率。数据集包含完整的版本演化链(回归引入提交、修复提交及测试用例),使得研究者能够精确复现缺陷演化过程,从而推动回归分析技术从理论验证走向工程实践。
实际应用
在工业实践中,RegMiner为软件质量保障提供了可扩展的自动化支持。开发团队可将其部署于内部代码仓库,持续挖掘项目特有的回归缺陷模式,用于构建定制化的回归测试套件。该工具能够识别易引入回归缺陷的代码模块与开发人员,辅助项目管理者进行风险评估与资源分配。同时,挖掘出的缺陷修复补丁可作为知识库,为自动化程序修复工具提供训练数据或补丁推荐参考。在持续集成流程中,RegMiner的测试迁移与验证优化技术可直接用于加速历史版本的回溯测试,降低大规模代码库的回归验证成本。
衍生相关工作
RegMiner数据集催生了多个方向的经典衍生研究。在回归定位领域,Wang等人提出的概率化Delta Debugging算法利用该数据集验证了其在真实回归场景下的优越性;Tan与Roychoudhury的Relifix回归修复工具亦基于类似数据构建修复模式。在数据集构建方法层面,RegMiner的测试迁移技术与验证优化策略被后续工作如BugBuilder继承并扩展,用于更精确的缺陷补丁提取。此外,该数据集支撑了多项回归解释研究,如Wang等人的对齐切片技术通过对比缺陷版本与历史版本的执行轨迹,实现了回归根源的语义化解释。这些工作共同推动了回归分析从孤立案例研究向系统化实证科学的演进。
以上内容由遇见数据集搜集并总结生成


