mehuldamani/neurips-story-test-v3
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/mehuldamani/neurips-story-test-v3
下载链接
链接失效反馈官方服务:
资源简介:
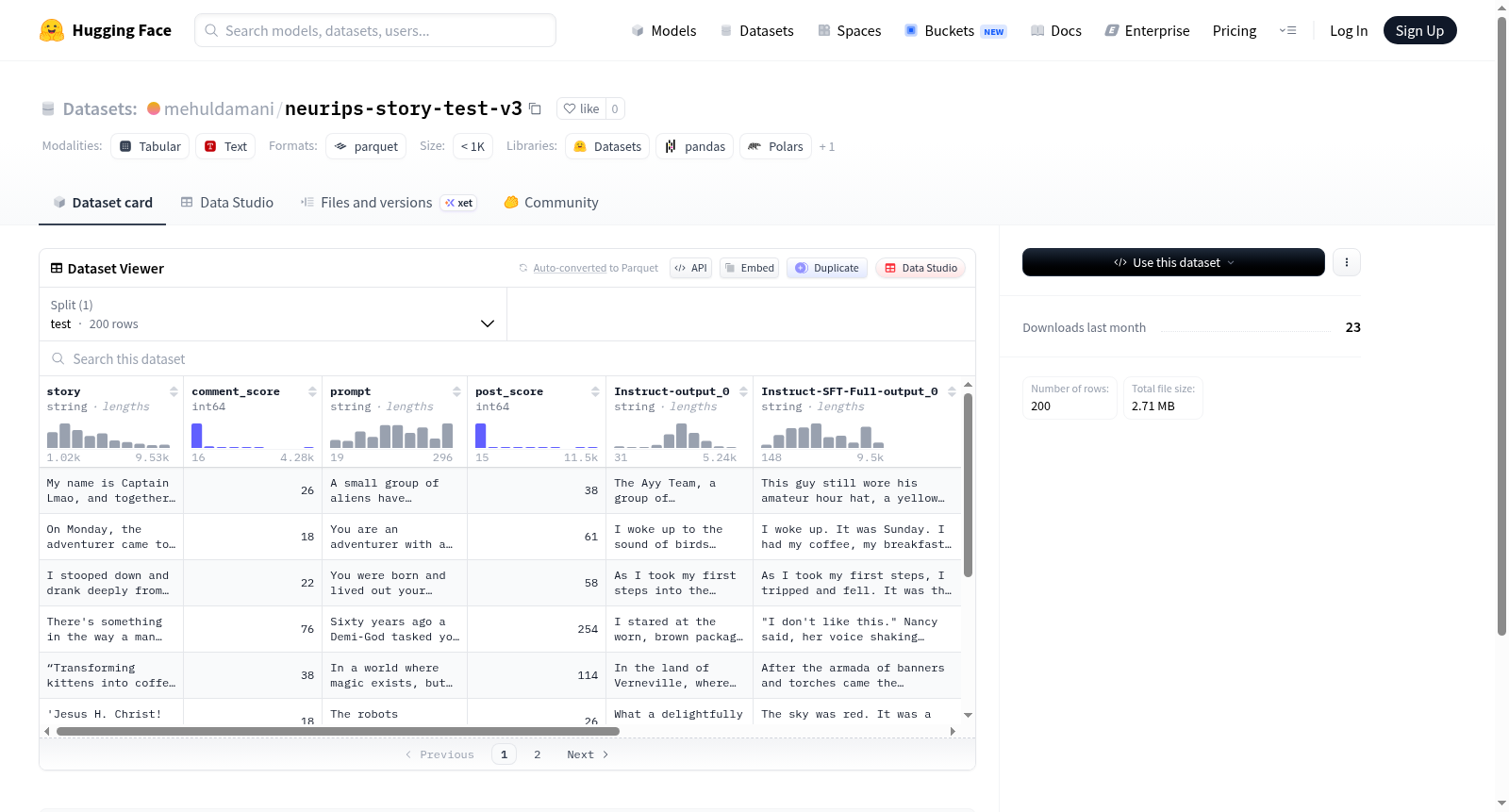
该数据集包含200个测试示例,每个示例具有故事文本、评论分数、提示词、帖子分数以及多个模型生成的输出(包括Instruct、SFT和RL变体),用于模型性能评估或内容生成比较。
This dataset includes 200 test examples, each featuring story text, comment scores, prompts, post scores, and multiple model-generated outputs (such as Instruct, SFT, and RL variants), intended for model performance evaluation or content generation comparison.
提供机构:
mehuldamani
搜集汇总
数据集介绍
构建方式
该数据集基于NeurIPS相关社区的故事生成任务构建,从用户提交的故事文本中采集了200条测试样本。每条样本包含原始故事、对应的提示词(prompt)、评论评分(comment_score)和帖子评分(post_score),同时纳入了多种指令微调与强化学习策略下的模型输出,包括Instruct-output、Instruct-SFT-Full、Instruct-SFT-Partial、RL-Full及RL-Partial等变体,旨在系统评估不同训练范式对故事生成质量的影响。
特点
数据集的核心特色在于其多维度比较能力,不仅提供了人类评分作为基准,还囊括了多种模型输出结果,便于研究者深入分析指令微调与强化学习在故事创作中的差异化表现。200条样本规模虽精简,但覆盖了提示词、故事内容及多模型输出,为小样本评估与案例分析提供了理想素材。此外,评分字段的引入使得定量分析成为可能,有助于揭示模型输出与人类审美偏好之间的关联。
使用方法
使用时,可直接加载测试集(test split),提取story、prompt及各类输出字段进行对比分析。研究者可计算模型输出与人类评分之间的相关性,或通过指令微调与强化学习变体之间的成对比较,探究不同训练策略对故事流畅性、创意性及情感共鸣的影响。该数据集尤适用于生成式模型的基准测试与消融实验,无需额外预处理即可快速上手。
背景与挑战
背景概述
在自然语言生成与故事创作领域,如何评估模型生成的叙事质量始终是一项核心挑战。神经故事测试集(NeurIPS Story Test v3)诞生于NeurIPS相关研究社区,由国际顶级机器学习会议NeurIPS的研究人员或机构构建,旨在系统性地评估语言模型在开放式故事生成任务上的表现。该数据集包含200个测试样本,每个样本涵盖原始故事、评论得分、提示文本、帖子得分,以及来自不同训练策略(如Instruct、SFT、RL)的模型输出,为对比研究提供了标准化基准。通过引入多维度的评估指标与多样化的模型输出,该数据集显著推动了故事生成领域中模型对齐能力与创意表达的量化研究,成为衡量指令微调与强化学习策略有效性的重要测试平台。
当前挑战
该数据集所解决的核心领域问题是故事生成模型中指令遵循、叙事连贯性与创意多样性之间的平衡。现有模型在输出时往往难以同时保证对用户提示的忠实度与情节的逻辑性,尤其在长篇开放式故事中,模型容易陷入内容重复或偏离主题的困境。在构建过程中,数据集面临的主要挑战包括:如何设计多样且具有代表性的提示以覆盖广泛的故事类型,如何确保不同模型输出之间的可比性并避免评估偏差,以及如何通过有限的200个测试样本获得统计上可靠的性能差异信号。这些挑战共同制约了故事生成模型的稳健评估与优化方向。
常用场景
经典使用场景
在自然语言处理与计算创造力交叉的学术前沿,'neurips-story-test-v3'数据集凭借其精心设计的200条富故事样本,成为评估自动化叙事系统效能的标杆。每条样本不仅包含原始故事与提示(prompt),还囊括了源自社区的评分(comment_score与post_score),使其在故事生成、连贯性评测及内容质量预测等经典任务中备受青睐。研究者常借助该数据集验证模型在开放式叙事场景下的表现,尤其聚焦于如何从条件提示出发,生成既具逻辑连贯性又富情感张力的故事文本。
实际应用
在产业实践中,该数据集承载的应用潜力贯穿内容创作与智能交互。例如,可将其用于训练面向用户的辅助写作工具,通过分析故事结构与评分关联,赋予模型实时优化情节走向的能力。在游戏与虚拟现实中,它支持动态剧情生成系统,能够基于玩家输入生成多样化叙事分支。此外,社区评分机制可被迁移至社交媒体平台,用于自动识别高关注度创意内容,从而赋能推荐算法以内容质量为导向的精细调控。
衍生相关工作
该数据集的发布催生了一系列影响深远的派生研究。经典工作包括基于对比学习的故事风格迁移模型,它利用Instruct与RL条件输出来解耦叙事要素;另有工作探索了评分预测与故事连贯性的联合学习,将用户偏好纳入生成式对抗网络的训练目标。此外,结合多模态感知的叙事评估框架也应运而生,这些研究共同沿袭了该数据集开创的评价范式,在更具挑战性的长文本生成与人机共创场景中持续拓展边界。
以上内容由遇见数据集搜集并总结生成


