silk-road/ChatHaruhi-54K-Role-Playing-Dialogue
收藏Hugging Face2023-12-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/silk-road/ChatHaruhi-54K-Role-Playing-Dialogue
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
task_categories:
- text-generation
- text2text-generation
language:
- en
- zh
size_categories:
- 10K<n<100K
pretty_name: conversa
---
# ChatHaruhi
# Reviving Anime Character in Reality via Large Language Model
[]()
[]()
github repo: https://github.com/LC1332/Chat-Haruhi-Suzumiya
**Chat-Haruhi-Suzumiya**is a language model that imitates the tone, personality and storylines of characters like Haruhi Suzumiya,
<details>
<summary> The project was developed by Cheng Li, Ziang Leng, Chenxi Yan, Xiaoyang Feng, HaoSheng Wang, Junyi Shen, Hao Wang, Weishi Mi, Aria Fei, Song Yan, Linkang Zhan, Yaokai Jia, Pingyu Wu, and Haozhen Sun,etc. </summary>
This is an open source project and the members were recruited from open source communities like DataWhale.
Lulu Li( [Cheng Li@SenseTime](https://github.com/LC1332) )initiated the whole project and designed and implemented most of the features.
Ziang Leng( [Ziang Leng@SenseTime](https://blairleng.github.io) )designed and implemented the training, data generation and backend architecture for ChatHaruhi 1.0.
Chenxi Yan( [Chenxi Yan@Chengdu University of Information Technology](https://github.com/todochenxi) )implemented and maintained the backend for ChatHaruhi 1.0.
Junyi Shen( [Junyi Shen@Zhejiang University](https://github.com/J1shen) )implemented the training code and participated in generating the training dataset.
Hao Wang( [Hao Wang](https://github.com/wanghao07456) )collected script data for a TV series and participated in data augmentation.
Weishi Mi( [Weishi MI@Tsinghua University](https://github.com/hhhwmws0117) )participated in data augmentation.
Aria Fei( [Aria Fei@BJUT](https://ariafyy.github.io/) )implemented the ASR feature for the script tool and participated in the Openness-Aware Personality paper project.
Xiaoyang Feng( [Xiaoyang Feng@Nanjing Agricultural University](https://github.com/fengyunzaidushi) )integrated the script recognition tool and participated in the Openness-Aware Personality paper project.
Yue Leng ( [Song Yan](https://github.com/zealot52099) )Collected data from The Big Bang Theory. Implemented script format conversion.
scixing(HaoSheng Wang)( [HaoSheng Wang](https://github.com/ssccinng) ) implemented voiceprint recognition in the script tool and tts-vits speech synthesis.
Linkang Zhan( [JunityZhan@Case Western Reserve University](https://github.com/JunityZhan) ) collected Genshin Impact's system prompts and story data.
Yaokai Jia( [Yaokai Jia](https://github.com/KaiJiaBrother) )implemented the Vue frontend and practiced GPU extraction of Bert in a psychology project.
Pingyu Wu( [Pingyu Wu@Juncai Shuyun](https://github.com/wpydcr) )helped deploy the first version of the training code.
Haozhen Sun( [Haozhen Sun@Tianjin University] )plot the character figures for ChatHaruhi.
</details>
## transfer into input-target format
If you want to convert this data into an input-output format
check the link here
https://huggingface.co/datasets/silk-road/ChatHaruhi-Expand-118K
### Citation
Please cite the repo if you use the data or code in this repo.
```
@misc{li2023chatharuhi,
title={ChatHaruhi: Reviving Anime Character in Reality via Large Language Model},
author={Cheng Li and Ziang Leng and Chenxi Yan and Junyi Shen and Hao Wang and Weishi MI and Yaying Fei and Xiaoyang Feng and Song Yan and HaoSheng Wang and Linkang Zhan and Yaokai Jia and Pingyu Wu and Haozhen Sun},
year={2023},
eprint={2308.09597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
---
许可证:CC-BY-4.0
任务类别:
- 文本生成
- 文本到文本生成
语言:
- 英语
- 中文
数据规模:10K<n<100K
可读名称:conversa
---
# ChatHaruhi
# 基于大语言模型(Large Language Model,LLM)复现动画角色的现实交互
[]()
[]()
项目仓库:https://github.com/LC1332/Chat-Haruhi-Suzumiya
**Chat-Haruhi-Suzumiya**是一款旨在复刻凉宫春日等动画角色语气、性格与剧情逻辑的语言模型。
<details>
<summary> 本项目由程立、冷子昂、严晨熙、冯晓阳、王浩昇、沈俊毅、王浩、米威仕、费雅颖、宋岩、詹麟康、贾垚凯、吴平宇、孙浩桢等共同开发。 </summary>
本项目为开源项目,核心成员均招募自DataWhale等开源社区。
李璐([程立@商汤科技](https://github.com/LC1332))发起本项目,并设计并实现了绝大多数核心功能。
冷子昂([Ziang Leng@商汤科技](https://blairleng.github.io))设计并实现了ChatHaruhi 1.0的训练流程、数据生成方案与后端架构。
严晨熙([严晨熙@成都信息工程大学](https://github.com/todochenxi))负责实现并维护ChatHaruhi 1.0的后端服务。
沈俊毅([沈俊毅@浙江大学](https://github.com/J1shen))实现了训练代码,并参与了训练数据集的构建工作。
王浩([Hao Wang](https://github.com/wanghao07456))收集了美剧剧本数据,并参与了数据增强工作。
米威仕([Weishi MI@清华大学](https://github.com/hhhwmws0117))参与了数据增强工作。
费雅颖([Aria Fei@北京工业大学](https://ariafyy.github.io/))实现了剧本工具的自动语音识别(Automatic Speech Recognition,ASR)功能,并参与了「开放性感知人格」相关论文项目。
冯晓阳([冯晓阳@南京农业大学](https://github.com/fengyunzaidushi))完成了剧本识别工具的集成工作,并参与了「开放性感知人格」相关论文项目。
宋岩([Song Yan](https://github.com/zealot52099))收集了《生活大爆炸》的剧本数据,并实现了剧本格式转换功能。
王浩昇(网名为scixing,[HaoSheng Wang](https://github.com/ssccinng))实现了剧本工具中的声纹识别功能与文本转语音(Text-to-Speech,TTS)-VITS语音合成功能。
詹麟康([JunityZhan@凯斯西储大学](https://github.com/JunityZhan))收集了《原神》的系统提示词与剧情数据。
贾垚凯([Yaokai Jia](https://github.com/KaiJiaBrother))实现了Vue前端界面,并在某心理学项目中实践了基于图形处理器(Graphics Processing Unit,GPU)的BERT模型(Bidirectional Encoder Representations from Transformers)抽取工作。
吴平宇([Pingyu Wu@俊才数云](https://github.com/wpydcr))协助部署了训练代码的首个版本。
孙浩桢([孙浩桢@天津大学])负责绘制ChatHaruhi的角色可视化图表。
</details>
## 转换为输入-输出格式
若需将本数据集转换为输入-目标格式,请参考以下链接:
https://huggingface.co/datasets/silk-road/ChatHaruhi-Expand-118K
## 引用声明
若您在研究中使用本项目的数据或代码,请引用本仓库:
@misc{li2023chatharuhi,
title={ChatHaruhi: Reviving Anime Character in Reality via Large Language Model},
author={Cheng Li and Ziang Leng and Chenxi Yan and Junyi Shen and Hao Wang and Weishi MI and Yaying Fei and Xiaoyang Feng and Song Yan and HaoSheng Wang and Linkang Zhan and Yaokai Jia and Pingyu Wu and Haozhen Sun},
year={2023},
eprint={2308.09597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
silk-road
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-4.0
- 任务类别:
- 文本生成
- 文本到文本生成
- 语言:
- 英语
- 中文
- 数据规模: 10K<n<100K
- 易读名称: conversa
项目详情
- 项目名称: ChatHaruhi
- 描述: 一个模仿Haruhi Suzumiya等角色语调、个性和故事情节的语言模型。
数据集转换
- 输入-输出格式转换: 如需将数据转换为输入-输出格式,请参考此链接。
引用
- 引用格式: @misc{li2023chatharuhi, title={ChatHaruhi: Reviving Anime Character in Reality via Large Language Model}, author={Cheng Li and Ziang Leng and Chenxi Yan and Junyi Shen and Hao Wang and Weishi MI and Yaying Fei and Xiaoyang Feng and Song Yan and HaoSheng Wang and Linkang Zhan and Yaokai Jia and Pingyu Wu and Haozhen Sun}, year={2023}, eprint={2308.09597}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
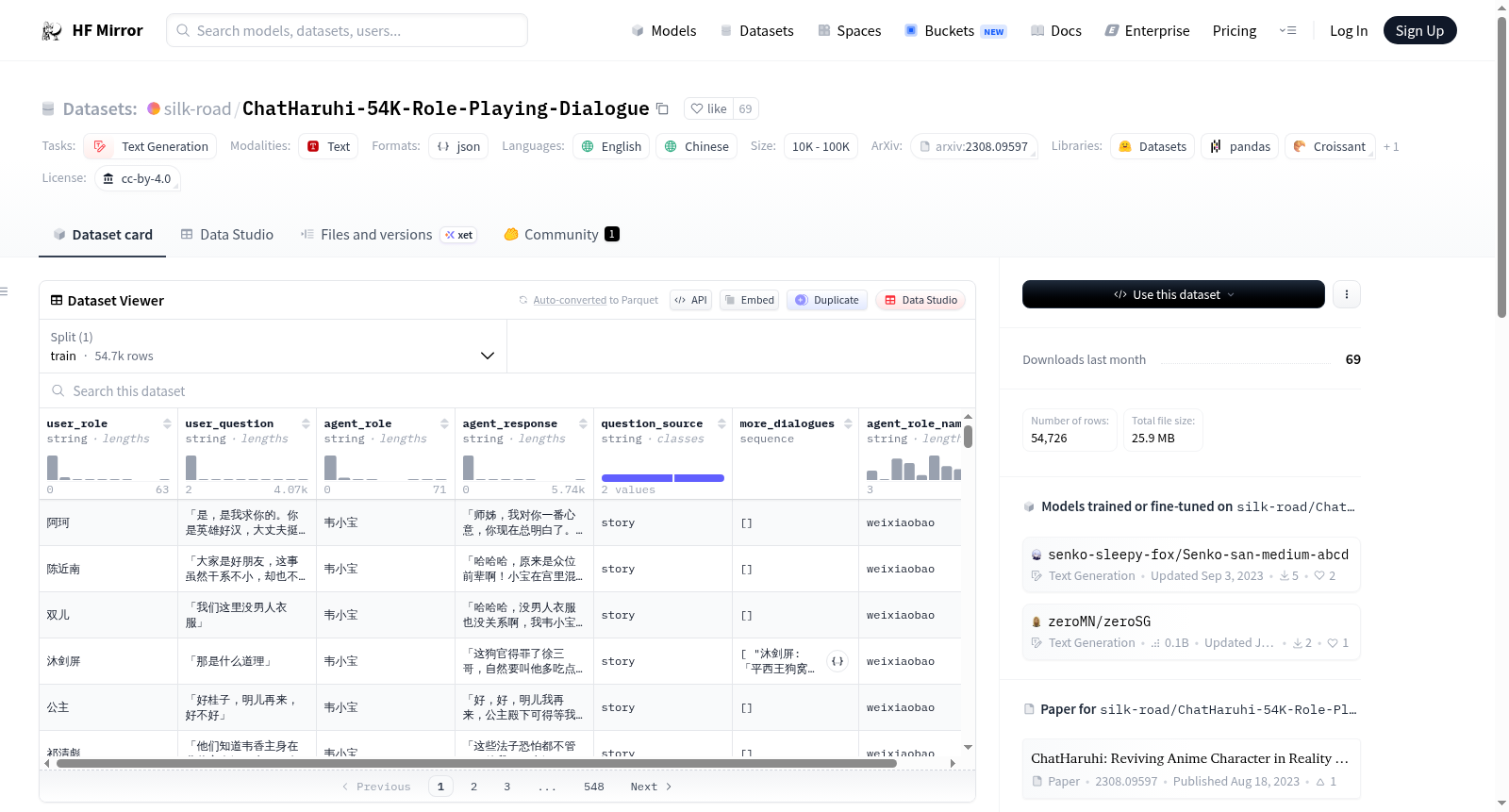
构建方式
在角色扮演对话生成领域,ChatHaruhi-54K-Role-Playing-Dialogue数据集的构建体现了多源数据融合与智能增强的策略。该数据集源自开源社区协作,通过收集经典动漫、电视剧及游戏剧本,如《凉宫春日的忧郁》和《生活大爆炸》等作品的原始对话文本。随后,研究团队运用自动化脚本工具进行格式转换与数据清洗,并采用基于大型语言模型的数据增强技术,生成符合角色性格与故事线的扩展对话,最终形成包含超过五万条双语对话对的规范化语料库。
使用方法
使用本数据集时,研究者可将其直接加载至兼容HuggingFace生态的机器学习框架中,用于训练或微调生成式语言模型。数据集已预处理为输入-目标对格式,适用于监督学习场景,如对话生成、角色一致性建模等任务。用户可通过官方提供的转换工具进一步调整数据格式,或结合其他扩展数据集以增强训练效果。在学术应用中,建议遵循CC-BY-4.0许可规范,并在成果中引用相关论文,以保障使用的合规性与学术严谨性。
背景与挑战
背景概述
在人工智能与自然语言处理领域,角色扮演对话生成作为一项前沿任务,旨在模拟特定角色的语言风格与个性特征,实现沉浸式人机交互。ChatHaruhi-54K-Role-Playing-Dialogue数据集于2023年由李鲁鲁、冷子昂等研究人员联合创建,其核心研究问题聚焦于通过大规模语言模型复活动漫角色,使其在对话中展现原有人设与故事背景。该数据集依托开源社区协作构建,推动了角色扮演对话系统的技术发展,为个性化对话生成与情感计算研究提供了重要数据支撑,对虚拟角色交互与娱乐应用领域产生了深远影响。
当前挑战
该数据集致力于解决角色扮演对话生成中的核心挑战,即如何精准捕捉并复现虚构角色的语言特质、情感表达与叙事连贯性,这要求模型在生成对话时兼顾角色一致性与语境适应性。在构建过程中,研究人员面临多重挑战:原始剧本数据的收集与清洗涉及多语言、多来源的异构文本,需进行高效的结构化转换;数据增强环节需确保生成内容在扩展规模的同时不偏离角色原设;此外,系统提示与故事数据的整合需平衡角色个性与对话多样性,以提升数据集的泛化能力与实用性。
常用场景
经典使用场景
在角色扮演对话生成领域,ChatHaruhi-54K数据集为模仿动漫角色如凉宫春日的语调、个性和故事线提供了丰富资源。该数据集通过大规模对话文本,支持语言模型在虚拟角色交互中实现高度拟人化表达,常用于构建沉浸式对话系统,使模型能够依据角色背景知识生成连贯且符合人物设定的回应。
解决学术问题
该数据集有效解决了角色一致性保持和个性化语言建模的学术挑战。通过提供结构化角色对话数据,它助力研究者探索如何在大语言模型中嵌入特定角色的知识库与行为模式,从而推动开放域对话系统在人格模拟方面的理论进展,并为跨媒体叙事生成提供了实证基础。
实际应用
在实际应用中,ChatHaruhi-54K数据集被广泛用于开发娱乐、教育及客户服务领域的智能对话代理。例如,在游戏或虚拟社区中,基于该数据集训练的模型能够赋予非玩家角色生动的人格特质,提升用户体验;同时,它也可用于创作辅助工具,帮助生成符合角色设定的剧本或故事内容。
数据集最近研究
最新研究方向
在角色扮演对话生成领域,ChatHaruhi-54K-Role-Playing-Dialogue数据集正推动前沿探索,聚焦于大型语言模型如何精准复现动漫角色的语调、个性与故事线。当前研究热点围绕多模态交互展开,结合语音识别与合成技术,实现角色对话的声纹模拟与情感表达,增强沉浸式体验。该数据集的影响在于为开放域人格建模提供了丰富语料,促进了人工智能在娱乐、教育等场景中的个性化应用,具有重要的学术与产业意义。
以上内容由遇见数据集搜集并总结生成


