dclm-baseline-1.0-parquet
收藏魔搭社区2026-01-10 更新2025-11-03 收录
下载链接:
https://modelscope.cn/datasets/mlfoundations/dclm-baseline-1.0-parquet
下载链接
链接失效反馈官方服务:
资源简介:
## DCLM-baseline
***Note: this is an identical copy of https://huggingface.co/datasets/mlfoundations/dclm-baseline-1.0, where all the files have been mapped to a parquet format.***
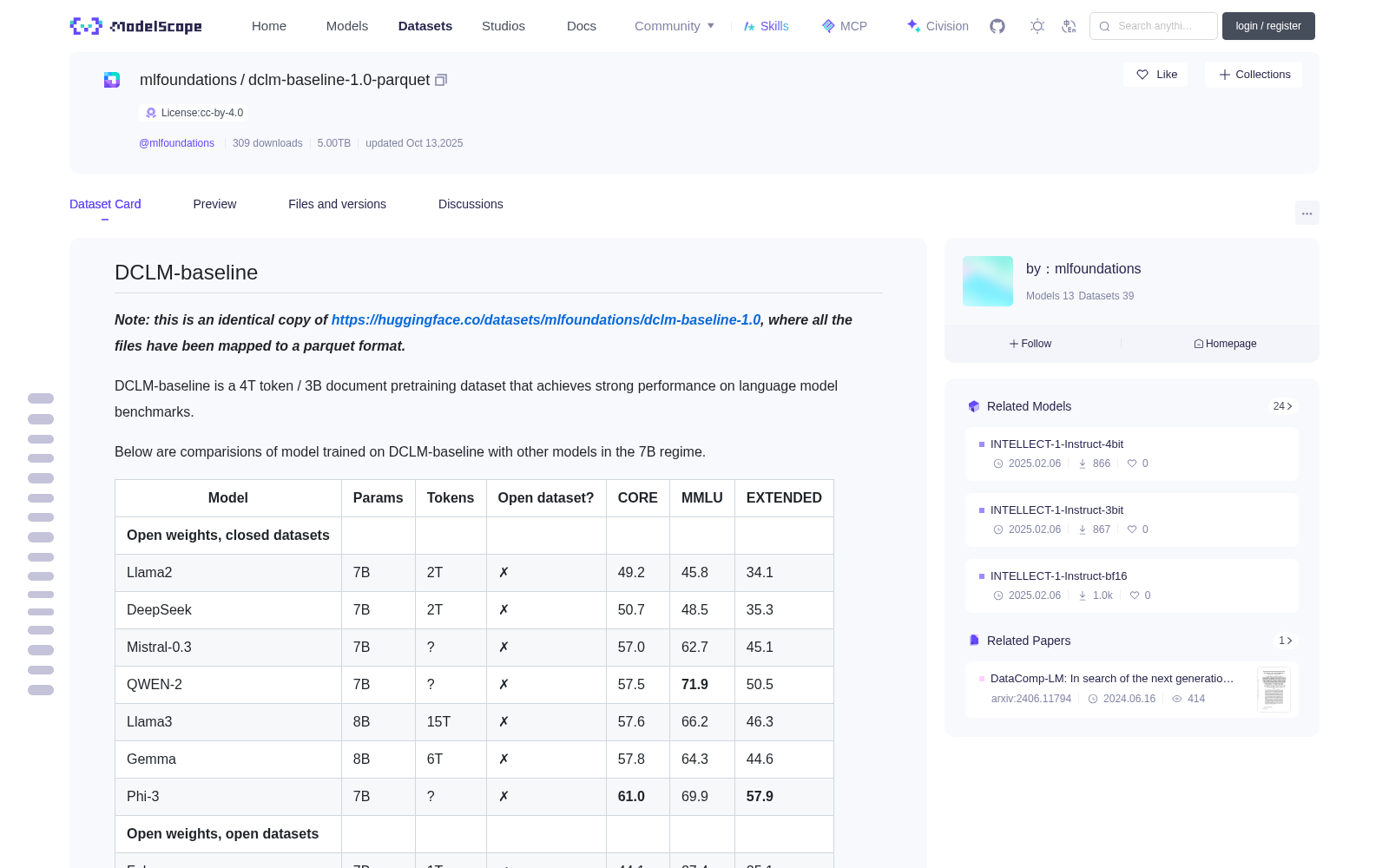
DCLM-baseline is a 4T token / 3B document pretraining dataset that achieves strong performance on language model benchmarks.
Below are comparisions of model trained on DCLM-baseline with other models in the 7B regime.
| Model | Params | Tokens | Open dataset? | CORE | MMLU | EXTENDED |
|---------------|--------|--------|---------------|----------|----------|----------|
| **Open weights, closed datasets** | | | | | | |
| Llama2 | 7B | 2T | ✗ | 49.2 | 45.8 | 34.1 |
| DeepSeek | 7B | 2T | ✗ | 50.7 | 48.5 | 35.3 |
| Mistral-0.3 | 7B | ? | ✗ | 57.0 | 62.7 | 45.1 |
| QWEN-2 | 7B | ? | ✗ | 57.5 | **71.9** | 50.5 |
| Llama3 | 8B | 15T | ✗ | 57.6 | 66.2 | 46.3 |
| Gemma | 8B | 6T | ✗ | 57.8 | 64.3 | 44.6 |
| Phi-3 | 7B | ? | ✗ | **61.0** | 69.9 | **57.9** |
| **Open weights, open datasets** | | | | | | |
| Falcon | 7B | 1T | ✓ | 44.1 | 27.4 | 25.1 |
| Amber | 7B | 1.2T | ✓ | 39.8 | 27.9 | 22.3 |
| Crystal | 7B | 1.2T | ✓ | 48.0 | 48.2 | 33.2 |
| OLMo-1.7 | 7B | 2.1T | ✓ | 47.0 | 54.0 | 34.2 |
| MAP-Neo | 7B | 4.5T | ✓ | **50.2** | **57.1** | **40.4** |
| **Models we trained** | | | | | | |
| FineWeb edu | 7B | 0.14T | ✓ | 38.7 | 26.3 | 22.1 |
| FineWeb edu | 7B | 0.28T | ✓ | 41.9 | 37.3 | 24.5 |
| **DCLM-BASELINE** | 7B | 0.14T | ✓ | 44.1 | 38.3 | 25.0 |
| **DCLM-BASELINE** | 7B | 0.28T | ✓ | 48.9 | 50.8 | 31.8 |
| **DCLM-BASELINE** | 7B | 2.6T | ✓ | **57.1** | **63.7** | **45.4** |
## Dataset Details
### Dataset Description
- **Curated by:** The DCLM Team
- **Language(s) (NLP):** English
- **License:** CC-by-4.0
### Dataset Sources
- **Repository:** https://datacomp.ai/dclm
- **Paper:**: https://arxiv.org/abs/2406.11794
- **Construction Code**: https://github.com/mlfoundations/dclm
## Uses
### Direct Use
DCLM-Baseline is intended to be used as a research baseline for the DCLM benchmark. It demonstrates the importance of data curation in training performant language models.
### Out-of-Scope Use
DCLM-Baseline is not intended for training production-ready models or for specific domains such as code and math. It may not perform as well as domain-specific datasets for these tasks. Due to these limitations, the dataset is intended for research use only.
DCLM-Baseline is a subset of the DCLM-Pool, which is a corpus of 240 trillion tokens derived from Common Crawl. The dataset is in plain text format.
## Dataset Creation
### Curation Rationale
DCLM-Baseline was created to demonstrate the effectiveness of the DCLM testbed in developing high-quality training sets for language models. It serves as a proof of concept for the data curation strategies enabled by DCLM and is designed to be a research baseline for the benchmark.
### Source Data
#### Data Collection and Processing
DCLM-Baseline was created by applying a series of cleaning, filtering, and deduplication steps to the raw Common Crawl data (DCLM-Pool). The key steps include:
1. Heuristic cleaning and filtering (reproduction of RefinedWeb)
2. Deduplication using a Bloom filter
3. Model-based filtering using a fastText classifier trained on instruction-formatted data (OpenHermes 2.5 and r/ExplainLikeImFive)
#### Who are the source data producers?
The source data is from Common Crawl, which is a repository of web crawl data.
### Personal and Sensitive Information
[More Information Needed]
## Bias, Risks, and Limitations
The dataset may contain biases present in the Common Crawl data. The dataset's performance on code and math tasks is limited compared to its performance on language understanding tasks. DCLM-Baseline is designed for research purposes only.
### Recommendations
Users should be aware of the potential biases and limitations of the dataset, especially when using it for specific domains like code and math. The dataset should only be used for research purposes in the context of the DCLM benchmark.
## Citation
```bibtex
@misc{li2024datacomplm,
title={DataComp-LM: In search of the next generation of training sets for language models},
author={Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Gadre and Hritik Bansal and Etash Guha and Sedrick Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan Bitton and Marianna Nezhurina and Amro Abbas and Cheng-Yu Hsieh and Dhruba Ghosh and Josh Gardner and Maciej Kilian and Hanlin Zhang and Rulin Shao and Sarah Pratt and Sunny Sanyal and Gabriel Ilharco and Giannis Daras and Kalyani Marathe and Aaron Gokaslan and Jieyu Zhang and Khyathi Chandu and Thao Nguyen and Igor Vasiljevic and Sham Kakade and Shuran Song and Sujay Sanghavi and Fartash Faghri and Sewoong Oh and Luke Zettlemoyer and Kyle Lo and Alaaeldin El-Nouby and Hadi Pouransari and Alexander Toshev and Stephanie Wang and Dirk Groeneveld and Luca Soldaini and Pang Wei Koh and Jenia Jitsev and Thomas Kollar and Alexandros G. Dimakis and Yair Carmon and Achal Dave and Ludwig Schmidt and Vaishaal Shankar},
year={2024},
eprint={2406.11794},
archivePrefix={arXiv},
primaryClass={id='cs.LG' full_name='Machine Learning' is_active=True alt_name=None in_archive='cs' is_general=False description='Papers on all aspects of machine learning research (supervised, unsupervised, reinforcement learning, bandit problems, and so on) including also robustness, explanation, fairness, and methodology. cs.LG is also an appropriate primary category for applications of machine learning methods.'}
```
## DCLM-baseline
***注:本数据集为https://huggingface.co/datasets/mlfoundations/dclm-baseline-1.0的完全复刻,所有文件均已转换为Parquet格式。***
DCLM-baseline是一个包含4万亿Token/30亿文档的预训练数据集,在语言模型基准测试中表现优异。
以下为基于DCLM-baseline训练的模型与7B量级其他模型的性能对比:
| 模型 | 参数规模 | 训练Token数 | 是否为开源数据集? | CORE基准 | MMLU基准 | EXTENDED基准 |
|--------------|----------|------------|------------------|--------------|--------------|--------------|
| **开源权重、闭源数据集** | | | | | | |
| Llama2 | 7B | 2T | × | 49.2 | 45.8 | 34.1 |
| DeepSeek | 7B | 2T | × | 50.7 | 48.5 | 35.3 |
| Mistral-0.3 | 7B | ? | × | 57.0 | 62.7 | 45.1 |
| QWEN-2 | 7B | ? | × | 57.5 | **71.9** | 50.5 |
| Llama3 | 8B | 15T | × | 57.6 | 66.2 | 46.3 |
| Gemma | 8B | 6T | × | 57.8 | 64.3 | 44.6 |
| Phi-3 | 7B | ? | × | **61.0** | 69.9 | **57.9** |
| **开源权重、开源数据集** | | | | | | |
| Falcon | 7B | 1T | √ | 44.1 | 27.4 | 25.1 |
| Amber | 7B | 1.2T | √ | 39.8 | 27.9 | 22.3 |
| Crystal | 7B | 1.2T | √ | 48.0 | 48.2 | 33.2 |
| OLMo-1.7 | 7B | 2.1T | √ | 47.0 | 54.0 | 34.2 |
| MAP-Neo | 7B | 4.5T | √ | **50.2** | **57.1** | **40.4** |
| **本团队训练的模型** | | | | | | |
| FineWeb edu | 7B | 0.14T | √ | 38.7 | 26.3 | 22.1 |
| FineWeb edu | 7B | 0.28T | √ | 41.9 | 37.3 | 24.5 |
| **DCLM-BASELINE** | 7B | 0.14T | √ | 44.1 | 38.3 | 25.0 |
| **DCLM-BASELINE** | 7B | 0.28T | √ | 48.9 | 50.8 | 31.8 |
| **DCLM-BASELINE** | 7B | 2.6T | √ | **57.1** | **63.7** | **45.4** |
## 数据集详情
### 数据集描述
- **整理方:** DCLM团队
- **自然语言语种:** 英语
- **授权协议:** CC-by-4.0
### 数据集来源
- **代码仓库:** https://datacomp.ai/dclm
- **相关论文:** https://arxiv.org/abs/2406.11794
- **构建代码:** https://github.com/mlfoundations/dclm
## 使用场景
### 直接使用场景
DCLM-Baseline旨在作为DCLM基准测试的研究基准数据集,用以展示数据整理在训练高性能语言模型中的重要性。
### 不适用场景
DCLM-Baseline不适用于训练可投入生产的模型,或针对代码、数学等特定领域的任务。在这类任务中,其性能可能不及领域专属数据集。受限于上述缺陷,本数据集仅可用于研究用途。
DCLM-Baseline是DCLM-Pool的子集,后者是一个源自Common Crawl(通用爬虫)、包含240万亿Token的语料库,本数据集采用纯文本格式。
## 数据集构建
### 整理逻辑
DCLM-Baseline的构建旨在验证DCLM开发平台在构建高质量语言模型训练集方面的有效性,作为DCLM所支持的数据整理策略的概念验证方案,并被设计为该基准测试的研究基准。
### 源数据
#### 数据收集与处理
DCLM-Baseline通过对原始Common Crawl(通用爬虫)数据(即DCLM-Pool)执行一系列清洗、过滤与去重步骤构建而成,关键步骤如下:
1. 启发式清洗与过滤(复刻RefinedWeb流程)
2. 基于布隆过滤器(Bloom filter)的去重操作
3. 基于模型的过滤:使用在指令格式数据(OpenHermes 2.5与r/ExplainLikeImFive)上训练的fastText分类器完成过滤
#### 源数据生产者
本数据集的源数据来自Common Crawl(通用爬虫),这是一个网页爬取数据仓库。
#### 个人与敏感信息
[需补充更多信息]
## 偏差、风险与局限性
本数据集可能包含Common Crawl(通用爬虫)数据中固有的偏差。相较于语言理解任务,其在代码与数学任务上的性能存在局限。DCLM-Baseline仅设计用于研究用途。
### 使用建议
用户应知晓本数据集潜在的偏差与局限性,尤其是在将其用于代码、数学等特定领域任务时。本数据集仅可在DCLM基准测试的框架下用于研究用途。
## 引用
bibtex
@misc{li2024datacomplm,
title={DataComp-LM: In search of the next generation of training sets for language models},
author={Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Gadre and Hritik Bansal and Etash Guha and Sedrick Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan Bitton and Marianna Nezhurina and Amro Abbas and Cheng-Yu Hsieh and Dhruba Ghosh and Josh Gardner and Maciej Kilian and Hanlin Zhang and Rulin Shao and Sarah Pratt and Sunny Sanyal and Gabriel Ilharco and Giannis Daras and Kalyani Marathe and Aaron Gokaslan and Jieyu Zhang and Khyathi Chandu and Thao Nguyen and Igor Vasiljevic and Sham Kakade and Shuran Song and Sujay Sanghavi and Fartash Faghri and Sewoong Oh and Luke Zettlemoyer and Kyle Lo and Alaaeldin El-Nouby and Hadi Pouransari and Alexander Toshev and Stephanie Wang and Dirk Groeneveld and Luca Soldaini and Pang Wei Koh and Jenia Jitsev and Thomas Kollar and Alexandros G. Dimakis and Yair Carmon and Achal Dave and Ludwig Schmidt and Vaishaal Shankar},
year={2024},
eprint={2406.11794},
archivePrefix={arXiv},
primaryClass={id='cs.LG' full_name='Machine Learning' is_active=True alt_name=None in_archive='cs' is_general=False description='Papers on all aspects of machine learning research (supervised, unsupervised, reinforcement learning, bandit problems, and so on) including also robustness, explanation, fairness, and methodology. cs.LG is also an appropriate primary category for applications of machine learning methods.'}
提供机构:
maas创建时间:
2025-10-02
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是DCLM-baseline的Parquet格式版本,包含4万亿token和30亿文档,专为语言模型预训练设计。它基于Common Crawl数据经过严格处理,适用于研究基准测试,并采用CC-by-4.0许可证。
以上内容由遇见数据集搜集并总结生成


