TextAtlas5M
收藏arXiv2025-02-12 更新2025-02-14 收录
下载链接:
https://textatlas5m.github.io
下载链接
链接失效反馈官方服务:
资源简介:
TextAtlas5M是一个大规模的文本条件图像生成数据集,由中南大学、北方工业大学、微软、新加坡国立大学等机构共同创建。该数据集包含500万张生成和收集的长文本图像,涵盖多种数据类型,旨在评估大规模生成模型在长文本图像生成方面的性能。数据集分为合成图像和真实图像两部分,并包含一个专门用于评估的长文本测试集TextAtlasEval,覆盖三个数据领域,为文本条件图像生成任务提供了全面的基准。
TextAtlas5M is a large-scale text-conditioned image generation dataset jointly created by institutions including Central South University, North China University of Technology, Microsoft, National University of Singapore, and others. This dataset contains 5 million generated and collected image-text pairs with lengthy descriptive texts, covering multiple data types, and is designed to evaluate the performance of large-scale generative models in long-text-conditioned image generation tasks. The dataset is split into two subsets: synthetic images and real images. It also includes a dedicated long-text test set named TextAtlasEval, which covers three data domains and provides a comprehensive benchmark for text-conditioned image generation tasks.
提供机构:
中南大学, 中国; 北方工业大学, 中国; 微软, 美国; 新加坡国立大学, 新加坡
创建时间:
2025-02-12
搜集汇总
数据集介绍
构建方式
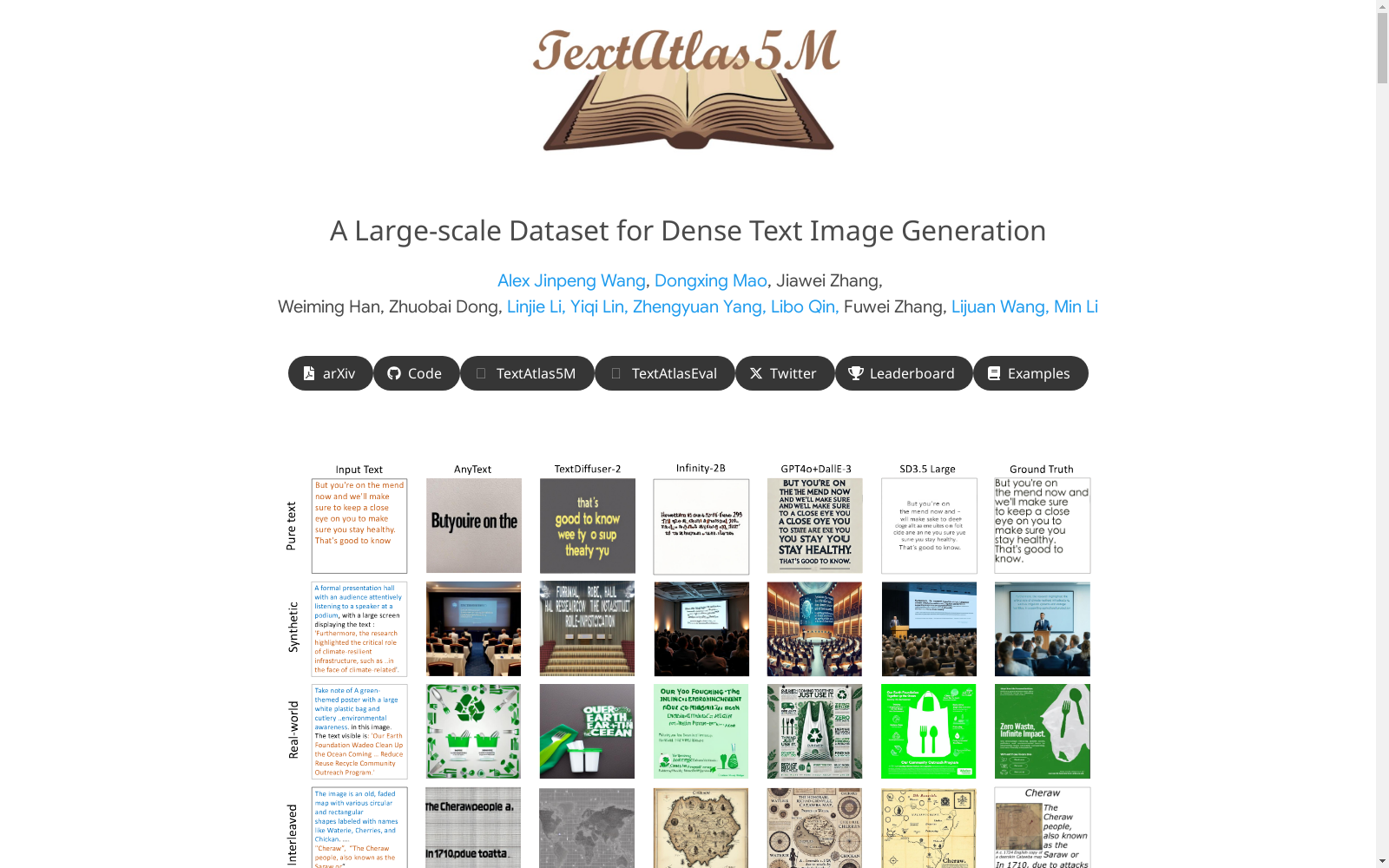
TextAtlas5M 数据集的构建旨在解决现有数据集在长文本渲染方面的不足。该数据集包含了从真实世界和合成数据中收集的 500 万张图像,这些图像均包含长文本。数据集分为三个级别:简单文本、混合数据和合成自然图像,涵盖了从简单文本到复杂文本的场景。为了确保数据质量,数据集还包含 3000 张由人工改进的测试图像,涵盖了 3 个数据领域,建立了文本生成领域最全面的基准之一。
使用方法
TextAtlas5M 数据集可用于训练和评估文本生成模型。数据集分为训练集和测试集,训练集包含 500 万张图像,可用于模型训练;测试集包含 3000 张由人工改进的图像,可用于模型评估。在评估模型时,可以使用 FID、CLIP 分数、OCR 准确率、F1 分数和字符错误率等指标来衡量模型在长文本渲染方面的性能。
背景与挑战
背景概述
近年来,文本条件图像生成领域取得了显著进展,能够处理越来越长和全面的文本提示。在日常生活中,密集和复杂的文本出现在广告、信息图表和标志等场景中,在这些场景中,文本和视觉的结合对于传达复杂信息至关重要。然而,尽管取得了这些进展,生成包含长文本的图像仍然是一个持续的挑战,这主要是因为现有数据集通常专注于更短和更简单的文本。为了解决这个问题,我们引入了TextAtlas5M,这是一个专门设计用于评估文本条件图像生成中长文本渲染的新数据集。我们的数据集包括500万个长文本生成和收集的图像,涵盖多种数据类型,能够对大规模生成模型在长文本图像生成方面的能力进行全面的评估。我们还精心策划了3000个人工改进的测试集TextAtlasEval,涵盖3个数据领域,为文本条件生成建立了最广泛的基准之一。评估表明,TextAtlasEval基准对最先进的专有模型(如GPT4o与DallE-3)提出了重大挑战,而它们的开源替代品则显示出更大的性能差距。这些证据将TextAtlas5M定位为训练和评估未来文本条件图像生成模型的有价值的数据集。数据集已发布。
当前挑战
TextAtlas5M数据集旨在解决现有数据集在处理长文本输入方面的局限性,并提出了以下挑战:1)所解决的领域问题是图像生成中的长文本渲染,这是由于现有数据集通常专注于较短的文本,而长文本的图像生成仍然是一个挑战。2)构建过程中遇到的挑战包括数据收集和标注的高成本、时间消耗,以及确保数据质量和多样性的难度。3)在评估过程中,现有的模型在处理长文本生成时仍然存在性能差距,需要进一步改进模型以更好地理解和生成长文本。
常用场景
经典使用场景
TextAtlas5M数据集主要用于文本条件图像生成,特别是在处理长文本渲染方面。该数据集包含了500万个包含长文本的图像,涵盖了从广告到信息图表等多种数据类型,使得对大规模生成模型在长文本图像生成方面的评估成为可能。TextAtlas5M还提供了一个包含3000个经过人工改进的测试集TextAtlasEval,覆盖了3个数据领域,为文本条件生成领域建立了最广泛的基准之一。
解决学术问题
TextAtlas5M数据集的引入解决了现有数据集在处理长文本方面的局限性,这些数据集通常专注于较短和较简单的文本。通过提供更复杂和多样化的数据,TextAtlas5M为文本条件图像生成领域带来了新的挑战和机遇。该数据集还提供了一个专门的测试集TextAtlasEval,用于评估长文本信息在图像生成中的性能,从而填补了现有文本渲染基准的空白。
实际应用
TextAtlas5M数据集在实际应用中具有广泛的前景,包括广告设计、信息图表制作和标志设计等。通过使用TextAtlas5M,设计师和开发者可以生成包含复杂布局和密集文本的图像,从而更好地传达信息。此外,TextAtlas5M还可以用于训练和评估未来的文本条件图像生成模型,为文本和视觉内容的融合提供新的可能性。
数据集最近研究
最新研究方向
TextAtlas5M 数据集的引入旨在推动文本条件图像生成领域的进步,特别是针对长文本渲染。该数据集的构建填补了现有数据集在处理长文本输入方面的空白,提供了包含丰富多样、复杂长文本的图像。TextAtlas5M 的特点在于其包含的文本长度更长,图像中文字更密集,且涵盖了真实世界中的多样场景,如广告、信息图表和标识牌等。该数据集的发布为研究人员提供了宝贵的资源,以训练和评估下一代文本条件图像生成模型,并推动了在这一领域的前沿研究。TextAtlas5M 的评估结果表明,即使是先进的模型如 GPT4o 和 DallE-3,在处理长文本图像生成任务时也面临重大挑战。这表明了该数据集在推动文本条件图像生成领域的研究和发展中的重要性。
相关研究论文
- 1TextAtlas5M: A Large-scale Dataset for Dense Text Image Generation中南大学, 中国; 北方工业大学, 中国; 微软, 美国; 新加坡国立大学, 新加坡 · 2025年
以上内容由遇见数据集搜集并总结生成


