Akan Cinematic Emotions (ACE)
收藏arXiv2025-02-16 更新2025-02-27 收录
下载链接:
https://anonymous.4open.science/r/Akan-Cinematic-Emotion-A328/README.md
下载链接
链接失效反馈官方服务:
资源简介:
Akan Cinematic Emotions (ACE)数据集是由哥本哈根信息技术大学、哥伦比亚大学和苹果机器学习研究机构共同开发的,包含385个情感标记的对话和6162条发言,涵盖音频、视觉和文本多模态信息。该数据集以非洲语言Akan为对象,致力于填补情感识别研究中低资源语言的空白。数据集通过21部Akan语电影对话进行收集和标注,包含情感标签和单词级别的韵律突出标注,适用于低资源语言和跨文化的情感识别研究。
The Akan Cinematic Emotions (ACE) dataset was co-developed by the IT University of Copenhagen, Columbia University, and Apple Machine Learning Research. It comprises 385 emotion-annotated dialogues and 6,162 utterances, encompassing audio, visual, and textual multimodal data. Focused on the African language Akan, this dataset aims to fill the critical gap in emotion recognition research for low-resource languages. Collected and annotated from dialogues in 21 Akan-language films, the dataset includes both emotion labels and word-level prosodic prominence annotations, making it suitable for emotion recognition research on low-resource languages and cross-cultural studies.
提供机构:
哥本哈根信息技术大学, 哥伦比亚大学, 苹果机器学习研究
创建时间:
2025-02-16
搜集汇总
数据集介绍
构建方式
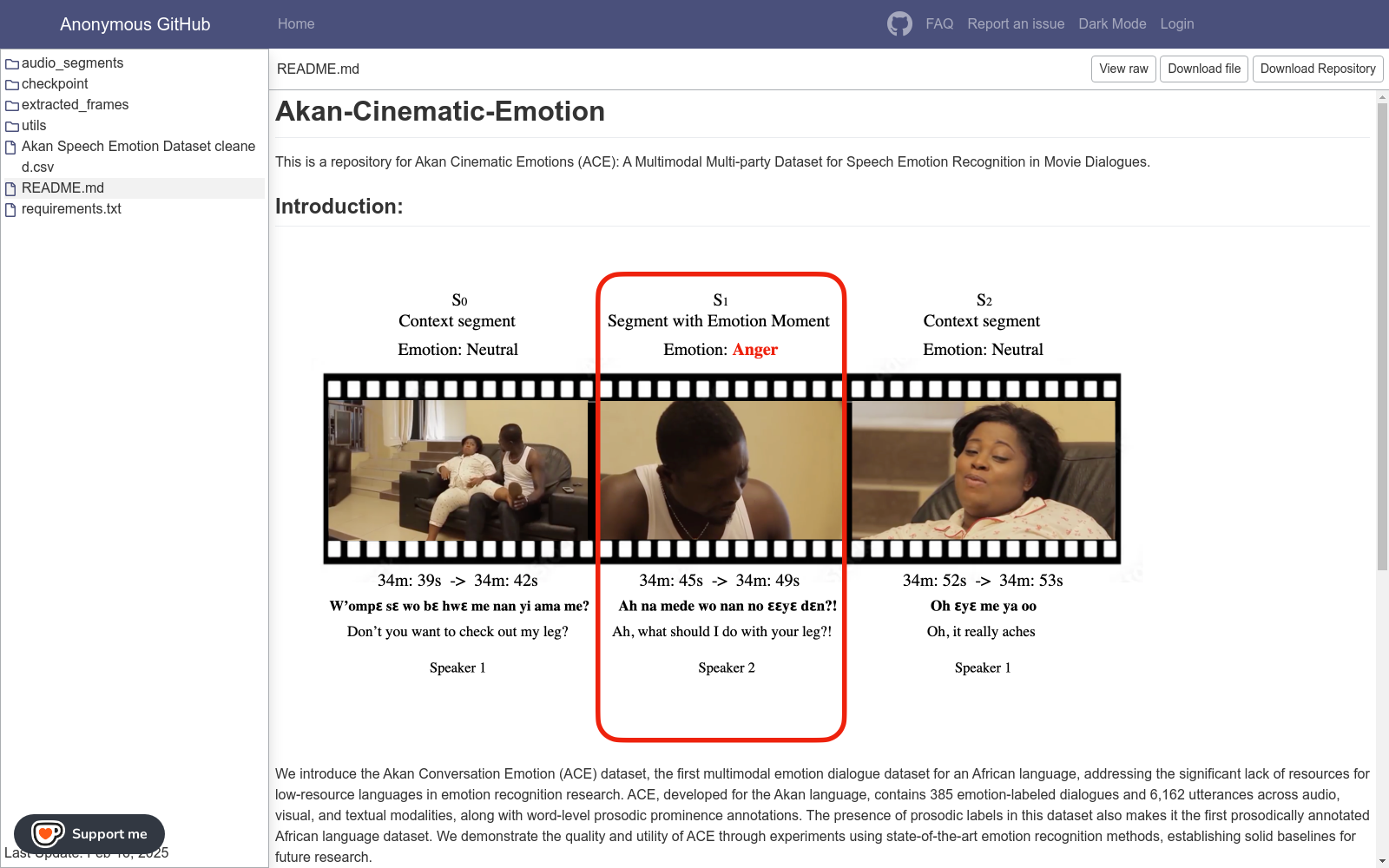
Akan Cinematic Emotions (ACE) 数据集的构建采用了多模态数据集成的方法,涵盖了音频、视觉和文本三种模态。数据集包含了来自21部阿肯语电影中的385个标注了情感的对话和6,162个话语。为了支持对语调在情感识别中的作用的研究,ACE 数据集还包含了词级语调突出标注。数据集的构建过程包括数据选择、标注者与标注过程、文本与说话者标注、情感标注、情感标注最终确定以及语调突出标注。数据选择过程中,研究者从互联网档案中下载了21部阿肯语电影,并确保所选电影符合完整性、可理解性和清晰性的标准。标注过程由来自加纳的语言和圣经翻译机构的阿肯语数据标注专业人员完成,所有标注后的数据都被汇总到一个Excel表中,并进行了冗余条目的消除和标注错误的纠正。
特点
Akan Cinematic Emotions (ACE) 数据集的特点包括:首先,它是首个针对非洲语言的阿肯语多模态情感对话数据集,填补了低资源语言在情感识别研究中的资源空白。其次,ACE 数据集包含了丰富的情感标注,包括7种情感标签,分别为:悲伤、恐惧、愤怒、惊讶、厌恶、快乐和中性。此外,ACE 数据集还包含了词级语调突出标注,这是首个针对非洲语言的语调标注数据集,为研究语调在情感识别中的作用提供了宝贵资源。最后,ACE 数据集包含了来自308位说话者的6,162个话语,确保了数据集的多样性和平衡性。
使用方法
Akan Cinematic Emotions (ACE) 数据集的使用方法包括:首先,研究人员可以使用该数据集进行情感识别模型的训练和评估,以验证模型在低资源语言和跨文化情感识别任务中的性能。其次,由于ACE数据集包含了丰富的语调标注,研究人员还可以使用该数据集研究语调在情感识别中的作用,以及语调在声调语言处理中的重要性。此外,ACE数据集的多模态特性也使其适用于多模态情感识别模型的研究,可以帮助研究人员探索不同模态之间的融合策略和相互作用。
背景与挑战
背景概述
情感识别在对话(Emotion Recognition in Conversation, ERC)是自然语言处理(NLP)的一个快速发展的子领域,其目标是从多轮对话中检测或分类说话者表达的情感状态。尽管ERC在近年来在NLP社区中引起了广泛关注,但现有的ERC数据集主要集中在高资源语言上,如英语和中文,对于低资源语言的资源相对匮乏。为了填补这一空白,David Sasu等人于2025年开发了Akan Cinematic Emotions (ACE)数据集,这是第一个针对非洲语言的多元情感对话数据集,旨在解决低资源语言在情感识别研究中的资源不足问题。ACE数据集包含385个情感标记的对话和6,162个话语,覆盖音频、视觉和文本模态,并包含词级韵律突出标注。ACE的创建为低资源语言的情感识别研究提供了宝贵的资源,并对相关领域产生了深远的影响。
当前挑战
ACE数据集的研究背景和构建过程中面临了多项挑战。首先,现有的ERC数据集主要针对高资源语言,缺乏对低资源语言的资源支持,尤其是在非洲语言方面。ACE的创建填补了这一空白,为低资源语言的ERC研究提供了重要的数据集。其次,构建过程中,研究人员面临着如何有效地集成多模态数据(如音频、视觉和文本)的挑战,以更好地捕捉对话中的情感动态。此外,对于声调语言来说,韵律特征对于情感识别至关重要,因此ACE数据集包含了词级韵律突出标注,为研究韵律在ERC中的作用提供了支持。
常用场景
经典使用场景
Akan Cinematic Emotions (ACE)数据集是一个多模态多语对话数据集,主要用于非洲语言的情感识别研究。该数据集包含了来自21部Akan电影的385个情感标记对话和6,162个语音、视觉和文本模态的语音片段,以及词级韵律突出标注。由于其包含了韵律标注,ACE成为了第一个韵律标注的非洲语言数据集。通过使用最先进的情感识别方法进行实验,我们验证了ACE数据集的质量和实用性,为未来的研究奠定了坚实的基础。我们希望ACE能够激励更多关于包容性、语言和文化多样性的NLP资源的研究。
实际应用
ACE数据集的实际应用场景包括情感识别、情感分析和情感计算等领域。通过使用ACE数据集,研究人员可以开发出更准确、更可靠的情感识别模型,从而在现实世界应用中提供更好的用户体验。例如,情感识别模型可以用于开发情感智能助手、情感分析工具和情感计算系统等。此外,ACE数据集还可以用于研究不同文化背景下情感表达的特点,为跨文化交流和理解提供支持。
衍生相关工作
ACE数据集的衍生相关工作包括对低资源语言的情感识别模型的研究、跨文化情感识别的研究以及韵律在情感识别中的作用的研究等。此外,ACE数据集还可以用于开发新的情感识别方法和技术,如基于深度学习的情感识别模型、基于注意力机制的融合模型等。这些研究将有助于推动情感识别技术的发展,并为低资源语言的情感识别研究提供新的思路和方法。
以上内容由遇见数据集搜集并总结生成


