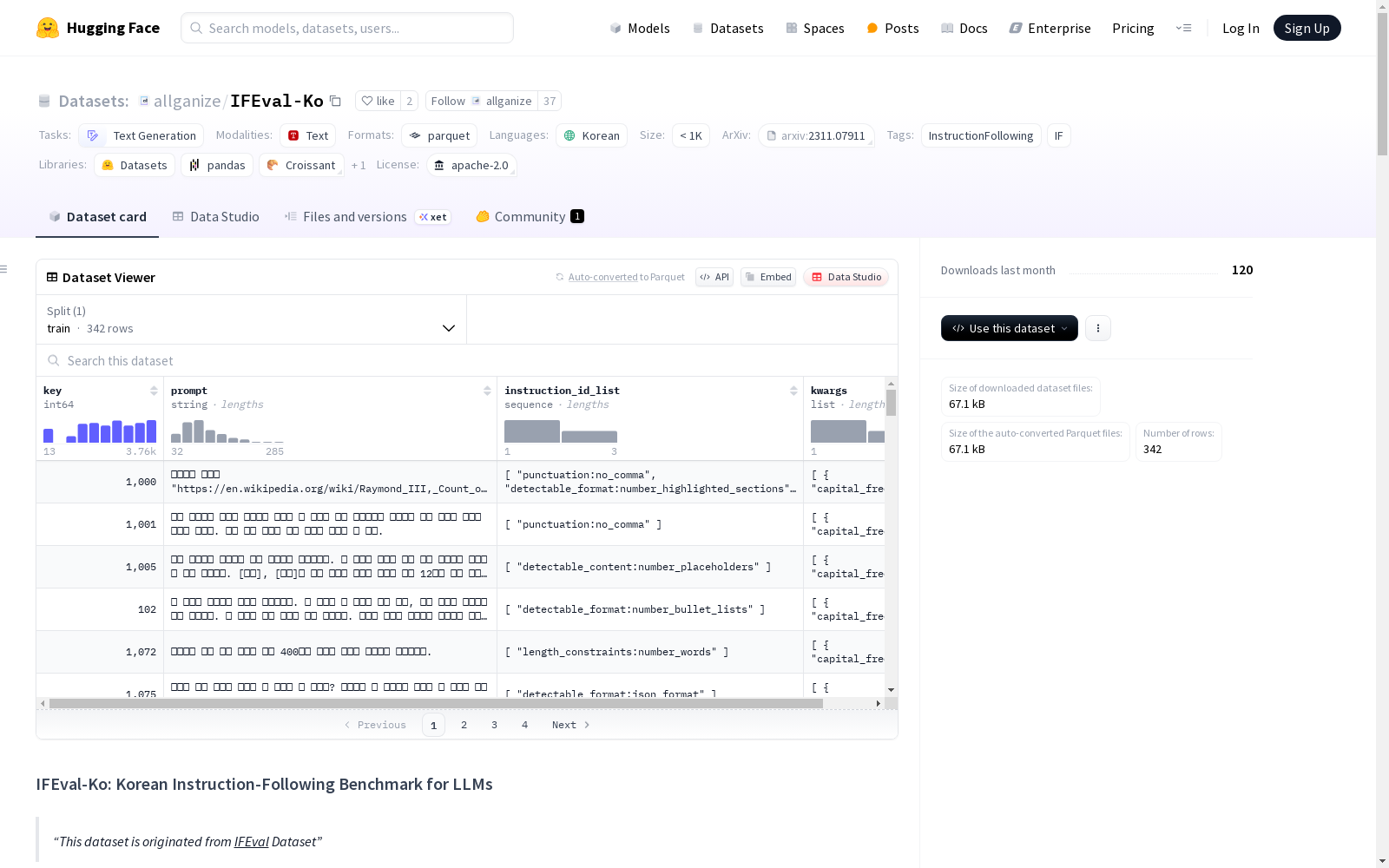
IFEval-Ko
收藏IFEval-Ko: 韩语指令遵循基准数据集
数据集概述
- 来源:基于Google的IFEval数据集
- 语言:韩语
- 许可协议:Apache-2.0
- 任务类别:文本生成
- 标签:InstructionFollowing, IF
- 数据规模:n<1K
数据集详情
-
特征:
key:int64类型prompt:string类型instruction_id_list:string序列kwargs:包含多个子特征的列表,如end_phrase、first_word、forbidden_words等
-
数据分割:
train:342个样本,168406字节
使用方式
-
安装依赖: bash git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness.git cd lm-evaluation-harness pip install -e . pip install langdetect immutabledict
-
下载任务文件: bash python3 -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id=allganize/IFEval-Ko, repo_type=dataset, local_dir=lm_eval/tasks/, allow_patterns=ifeval_ko/*, local_dir_use_symlinks=False)"
-
评估模型:
-
使用Hugging Face Transformers: bash lm_eval --model hf --model_args pretrained={HF_MODEL_REPO} --tasks ifeval_ko --device cuda:0 --batch_size 8
-
使用vLLM: bash lm_eval --model vllm --model_args pretrained={HF_MODEL_REPO},trust_remote_code=True --tasks ifeval_ko
-
修改内容
-
数据转换:
- 使用GPT-4o翻译提示
- 删除84个大小写敏感任务和28个字母依赖任务
- 单位转换(加仑→升,英尺/英寸→米/厘米,美元→韩元)
- 标准化标题和回答语气
-
代码变更:
- 翻译指令选项
- 修改评分类,移除
nltk依赖
评估指标
- 严格准确率:未经转换的响应检查
- 宽松准确率:应用3种转换后检查
- 提示级别:单个提示中的所有指令必须遵循
- 指令级别:单独评估每个指令
引用信息
bibtex @misc{zhou2023instructionfollowingevaluationlargelanguage, title={Instruction-Following Evaluation for Large Language Models}, author={Jeffrey Zhou and Tianjian Lu and Swaroop Mishra and Siddhartha Brahma and Sujoy Basu and Yi Luan and Denny Zhou and Le Hou}, year={2023}, eprint={2311.07911}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2311.07911}, }