VideoChat2-IT
收藏魔搭社区2026-05-16 更新2025-01-04 收录
下载链接:
https://modelscope.cn/datasets/OpenGVLab/VideoChat2-IT
下载链接
链接失效反馈官方服务:
资源简介:
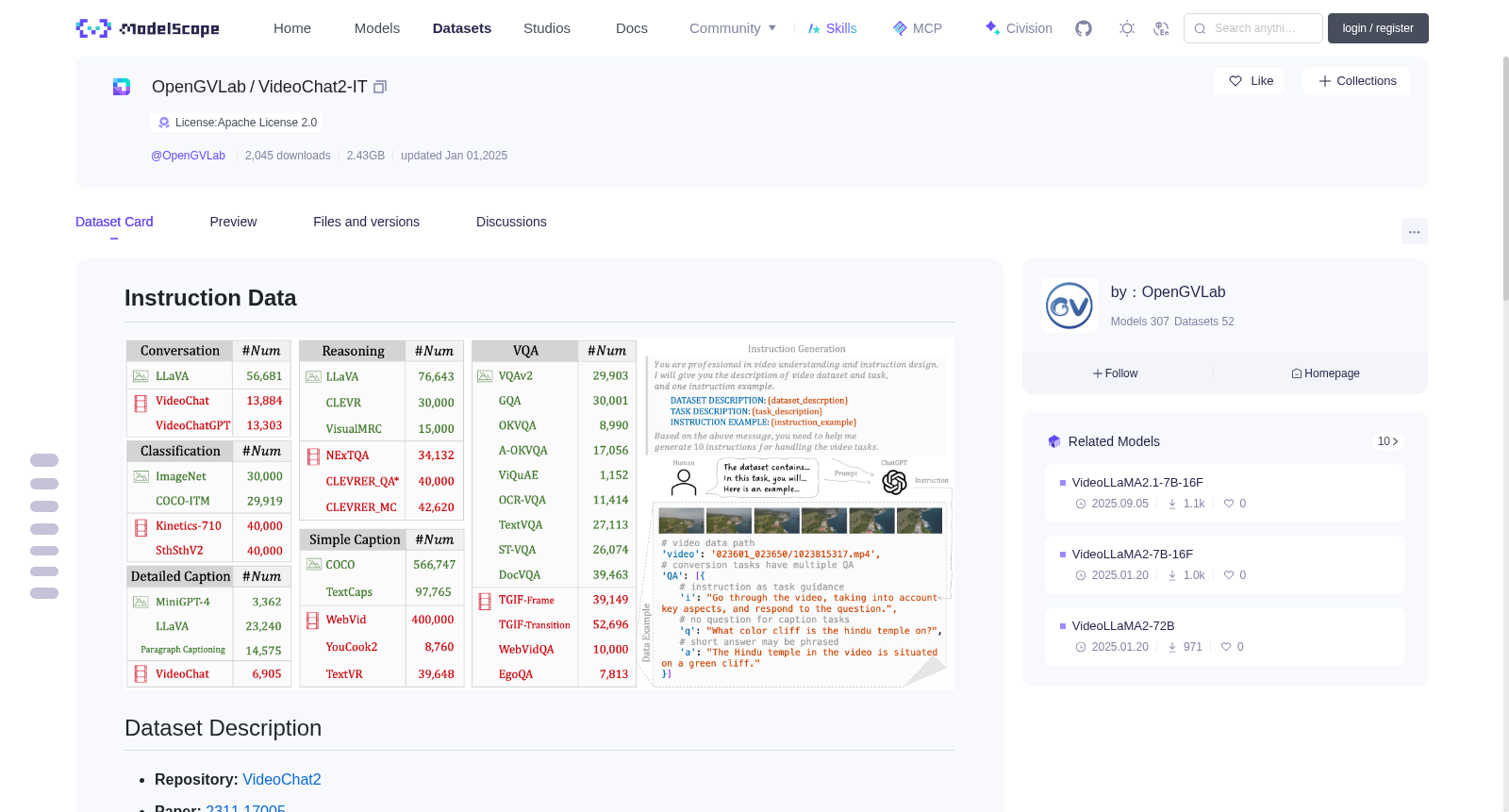
# Instruction Data

## Dataset Description
- **Repository:** [VideoChat2](https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2)
- **Paper:** [2311.17005](https://arxiv.org/abs/2311.17005)
- **Point of Contact:** mailto:[kunchang li](likunchang@pjlab.org.cn)
## Annotations
A comprehensive dataset of **1.9M** data annotations is available in [JSON](https://huggingface.co/datasets/OpenGVLab/VideoChat2-IT) format. Due to the extensive size of the full data, we provide only JSON files here. For corresponding images and videos, please follow our instructions.
## Source data
### Image
For image datasets, we utilized [M3IT](https://huggingface.co/datasets/MMInstruction/M3IT), filtering out lower-quality data by:
- **Correcting typos**: Most sentences with incorrect punctuation usage were rectified.
- **Rephrasing incorrect answers**: Some responses generated by ChatGPT, such as "Sorry, ...", were incorrect. These were rephrased using GPT-4.
You can easily download the datasets we employed from [M3IT](https://huggingface.co/datasets/MMInstruction/M3IT).
### Video
We treated video datasets differently. Please download the original videos from the provided links:
- [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data): Based on [InternVid](https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid), we created additional instruction data and used GPT-4 to condense the existing data.
- [VideoChatGPT](https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data): The original caption data was converted into conversation data based on the same VideoIDs.
- [Kinetics-710](https://github.com/OpenGVLab/UniFormerV2/blob/main/DATASET.md) & [SthSthV2](
https://developer.qualcomm.com/software/ai-datasets/something-something): Option candidates were generated from [UMT](https://github.com/OpenGVLab/unmasked_teacher) top-20 predictions.
- [NExTQA](https://github.com/doc-doc/NExT-QA): Typos in the original sentences were corrected.
- [CLEVRER](https://clevrer.csail.mit.edu/): For single-option multiple-choice QAs, we used only those concerning color/material/shape. For multi-option multiple-choice QAs, we utilized all the data.
- [WebVid](https://maxbain.com/webvid-dataset/): Non-overlapping data was selected for captioning and [QA](https://antoyang.github.io/just-ask.html#webvidvqa).
- [YouCook2](https://youcook2.eecs.umich.edu/): Original videos were truncated based on the official dense captions.
- [TextVR](https://github.com/callsys/textvr): All data was used without modifications.
- [TGIF](https://github.com/YunseokJANG/tgif-qa): Only TGIF$_{frame}$ and TGIF$_{Transition}$ subsets were considered.
- [EgoQA](https://ego4d-data.org/): Some egocentric QAs were generated from Ego4D data.
For all datasets, task instructions were automatically generated using GPT-4.
## Citation
If you find this project useful in your research, please consider cite:
```BibTeX
@article{2023videochat,
title={VideoChat: Chat-Centric Video Understanding},
author={KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao},
journal={arXiv preprint arXiv:2305.06355},
year={2023}
}
@misc{li2023mvbench,
title={MVBench: A Comprehensive Multi-modal Video Understanding Benchmark},
author={Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Yi Liu and Zun Wang and Jilan Xu and Guo Chen and Ping Luo and Limin Wang and Yu Qiao},
year={2023},
eprint={2311.17005},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
# 指令数据集

## 数据集说明
- **仓库地址**:[VideoChat2](https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2)
- **论文链接**:[2311.17005](https://arxiv.org/abs/2311.17005)
- **联络人**:mailto:[李坤昌](likunchang@pjlab.org.cn)
## 标注信息
本仓库提供了总计**190万**条数据标注,均采用JSON(JavaScript Object Notation)格式存储。鉴于完整数据集体量庞大,本仓库仅提供JSON标注文件。若需获取对应的图像与视频资源,请遵循本项目说明进行下载。
## 源数据
### 图像数据
针对图像数据集,我们选用了[M3IT](https://huggingface.co/datasets/MMInstruction/M3IT)数据集,并通过以下步骤过滤低质量数据:
- **修正拼写与标点错误**:修复绝大多数存在标点使用不当的语句。
- **重写不合格回复**:部分由ChatGPT生成的回复(如"Sorry, ..."开头的内容)存在错误,我们使用GPT-4(Generative Pre-trained Transformer 4)对其进行了重写优化。
你可通过[M3IT](https://huggingface.co/datasets/MMInstruction/M3IT)便捷下载我们所使用的数据集。
### 视频数据
我们对视频数据集采用了差异化处理流程,请通过以下链接下载原始视频资源:
- [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data):基于[InternVid](https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid)构建额外的指令数据,并使用GPT-4对现有数据进行精简压缩。
- [VideoChatGPT](https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/data):将原始字幕数据转换为基于相同视频ID的对话数据。
- [Kinetics-710](https://github.com/OpenGVLab/UniFormerV2/blob/main/DATASET.md) & [SthSthV2](https://developer.qualcomm.com/software/ai-datasets/something-something):从[UMT](https://github.com/OpenGVLab/unmasked_teacher)的Top-20预测结果中生成候选选项。
- [NExTQA](https://github.com/doc-doc/NExT-QA):修正原始文本中的拼写错误。
- [CLEVRER](https://clevrer.csail.mit.edu/):针对单选题问答任务,仅保留涉及颜色、材质、形状的样本;针对多选题问答任务,则使用全部数据集样本。
- [WebVid](https://maxbain.com/webvid-dataset/):选取无重复的数据用于字幕生成与问答(Question Answering,简称QA)任务。
- [YouCook2](https://youcook2.eecs.umich.edu/):根据官方密集字幕对原始视频进行截断处理。
- [TextVR](https://github.com/callsys/textvr):直接使用全部原始数据,未做任何修改。
- [TGIF](https://github.com/YunseokJANG/tgif-qa):仅选用TGIF$_{frame}$与TGIF$_{Transition}$两个子集。
- [EgoQA](https://ego4d-data.org/):基于Ego4D数据集生成部分以自我为中心的问答样本。
针对所有数据集,我们均使用GPT-4自动生成任务指令。
## 引用说明
若本项目对你的研究有所帮助,请引用以下文献:
BibTeX
@article{2023videochat,
title={VideoChat: Chat-Centric Video Understanding},
author={KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao},
journal={arXiv preprint arXiv:2305.06355},
year={2023}
}
@misc{li2023mvbench,
title={MVBench: A Comprehensive Multi-modal Video Understanding Benchmark},
author={Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Yi Liu and Zun Wang and Jilan Xu and Guo Chen and Ping Luo and Limin Wang and Yu Qiao},
year={2023},
eprint={2311.17005},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
提供机构:
maas
创建时间:
2024-12-27
搜集汇总
数据集介绍
背景与挑战
背景概述
VideoChat2-IT是一个包含1.9M标注数据的多模态数据集,主要用于视频理解和聊天式视频分析任务。数据集整合了多个公开图像和视频数据集,并利用GPT-4进行数据优化和指令生成,适用于多模态视频理解研究。
以上内容由遇见数据集搜集并总结生成


