MFC-Bench
收藏arXiv2024-06-17 更新2024-06-19 收录
下载链接:
https://github.com/wskbest/MFC-Bench
下载链接
链接失效反馈官方服务:
资源简介:
MFC-Bench是由北京邮电大学、香港浸会大学和香港科技大学联合创建的综合性多模态事实核查基准数据集,包含33,000个样本,用于评估大型视觉-语言模型(LVLMs)的事实准确性。该数据集涵盖了三个主要任务:操纵分类、上下文外分类和真实性分类,旨在检测和纠正多模态内容中的事实错误。创建过程中,数据集从多个来源精心挑选视觉和文本查询,确保对LVLMs在多模态事实核查中的能力进行全面评估。MFC-Bench的应用领域主要集中在提高人工智能在处理复杂视觉和文本元素时的准确性和责任感,以确保在线信息的可信度。
MFC-Bench is a comprehensive multimodal fact-checking benchmark dataset jointly developed by Beijing University of Posts and Telecommunications, Hong Kong Baptist University, and The Hong Kong University of Science and Technology. It consists of 33,000 samples, specifically designed to assess the factual accuracy of Large Vision-Language Models (LVLMs). This dataset encompasses three core tasks: manipulation classification, out-of-context classification, and authenticity classification, with the goal of detecting and rectifying factual errors in multimodal content. During its development, visual and textual queries were meticulously selected from multiple sources to ensure a comprehensive evaluation of LVLMs' capabilities in multimodal fact-checking. The primary application domains of MFC-Bench focus on enhancing the accuracy and accountability of artificial intelligence systems when processing complex visual and textual elements, thereby safeguarding the credibility of online information.
提供机构:
北京邮电大学 香港浸会大学 香港科技大学
创建时间:
2024-06-17
搜集汇总
数据集介绍
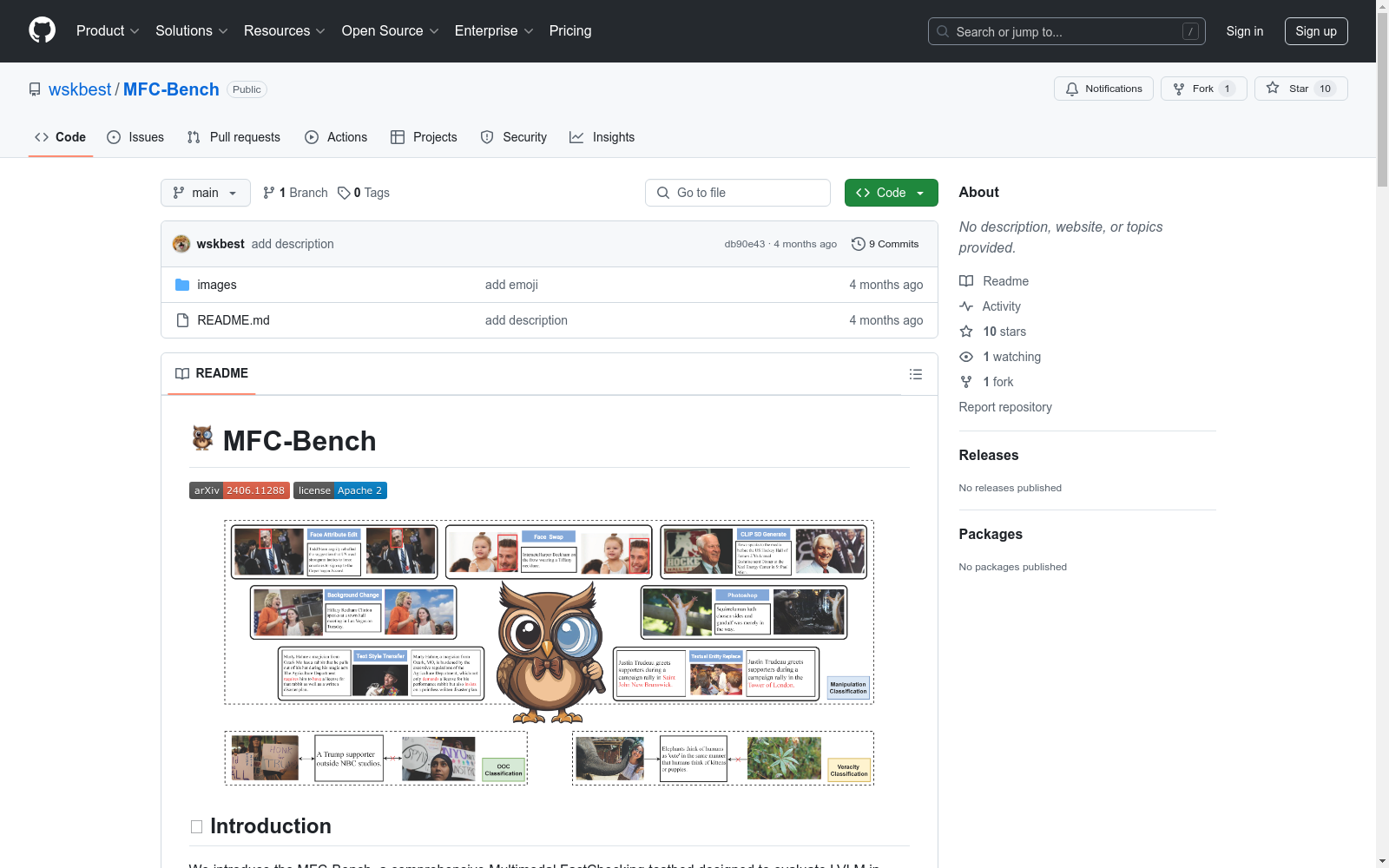
构建方式
MFC-Bench 数据集旨在评估大型视觉语言模型 (LVLMs) 在多模态事实核查任务中的准确性。该数据集由三个任务组成:操纵分类、上下文外分类和真实性分类。操纵分类任务包括六种类型的操纵,如人脸交换、人脸属性编辑、背景更改等。上下文外分类任务旨在评估图像和文本之间的上下文一致性。真实性分类任务评估文本声明基于图像证据的真实性。数据集包括来自不同数据源的33K个多模态样本,涵盖了各种视觉和文本查询,以确保对LVLMs进行全面的评估。
特点
MFC-Bench 数据集的特点在于其全面性和多样性。它包含了各种类型的操纵和上下文外数据,可以评估LVLMs在多模态事实核查任务中的表现。此外,数据集还采用了二元分类方法,使得评估结果更加直观和易于分析。此外,MFC-Bench 还提供了详细的性能分析,包括不同模型的性能差异以及不同提示策略对模型性能的影响。
使用方法
使用 MFC-Bench 数据集进行评估时,需要选择合适的模型和提示策略。数据集提供了四种提示方法:零样本、零样本+思维链、少样本和少样本+思维链。用户可以根据自己的需求选择合适的模型和提示策略,并使用数据集中的多模态样本进行评估。评估结果可以用于了解模型的性能,并指导模型的改进和优化。
背景与挑战
背景概述
在自然语言处理领域,大型语言模型(LLMs)在理解和执行人类指令方面取得了显著进展。这些模型展现出强大的零样本能力,能够在没有进一步参数调整的情况下有效执行任务。近年来,视觉语言模型(LVLMs)的出现进一步推动了多模态推理任务的发展,如视觉问答和图像描述。然而,LVLMs所理解的内容可能由于内在偏见或错误推理而偏离实际事实。为了解决这个问题,MFC-Bench应运而生,这是一个严谨且全面的基准测试,旨在评估LVLMs在三个任务上的事实准确性:操纵、上下文和真实性分类。MFC-Bench由北京邮电大学和香港浸会大学的研究人员开发,通过对12个多样性和代表性的LVLMs进行评估,揭示了当前模型在多模态事实检查方面的不足,并对各种形式的操纵内容表现出不敏感性。MFC-Bench的创建旨在提高人们对LVLMs在可信人工智能方面的潜力的关注。
当前挑战
MFC-Bench在评估LVLMs的多模态事实检查能力时面临着多项挑战。首先,LVLMs在处理多模态内容时,可能会因为内在偏见或错误推理而导致内容与实际事实不符。其次,构建MFC-Bench时需要精心设计各种操纵技术,如人脸交换、人脸属性编辑、背景更改等,以全面评估LVLMs在识别操纵内容方面的能力。此外,MFC-Bench的创建还面临着如何提高LVLMs对各种形式操纵内容的敏感性的挑战。
常用场景
经典使用场景
MFC-Bench数据集主要用于评估大型视觉语言模型(LVLMs)在多模态事实核查任务中的事实准确性。该数据集涵盖了三个主要的任务:操纵分类、上下文外分类和真实性分类。操纵分类任务旨在识别通过多种技术(如人脸交换、人脸属性编辑、背景更改等)操纵的多模态内容。上下文外分类任务则关注识别图像和文本之间的虚假联系。真实性分类任务则是基于图像证据评估文本声明的真实性。这些任务共同构成了一个全面的测试平台,用于评估LVLMs在处理复杂多模态内容时的事实核查能力。
实际应用
MFC-Bench数据集的实际应用场景广泛,包括但不限于社交媒体内容审核、新闻真实性核查和在线信息过滤。通过使用该数据集进行模型训练和评估,可以开发出更准确、可靠的多模态事实核查系统,帮助用户识别和过滤虚假信息,维护网络空间的健康和真实。此外,该数据集还可以用于教育和研究目的,帮助研究人员和学生对多模态事实核查技术有更深入的理解,并推动该领域的技术创新。
衍生相关工作
MFC-Bench数据集的推出衍生了一系列相关的经典工作,推动了多模态事实核查领域的研究进展。例如,一些研究者利用MFC-Bench数据集评估了不同LVLMs的性能,揭示了这些模型在处理复杂多模态内容时的优势和局限性。此外,还有一些研究者基于MFC-Bench数据集设计了新的多模态事实核查任务和评估指标,为该领域的研究提供了新的思路和方向。这些相关工作共同推动了多模态事实核查技术的发展,为构建更准确、可靠的多模态事实核查系统提供了重要的理论和实践基础。
以上内容由遇见数据集搜集并总结生成


