MonumentalSystems/chinchilla-master-corpus-v1
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/MonumentalSystems/chinchilla-master-corpus-v1
下载链接
链接失效反馈官方服务:
资源简介:
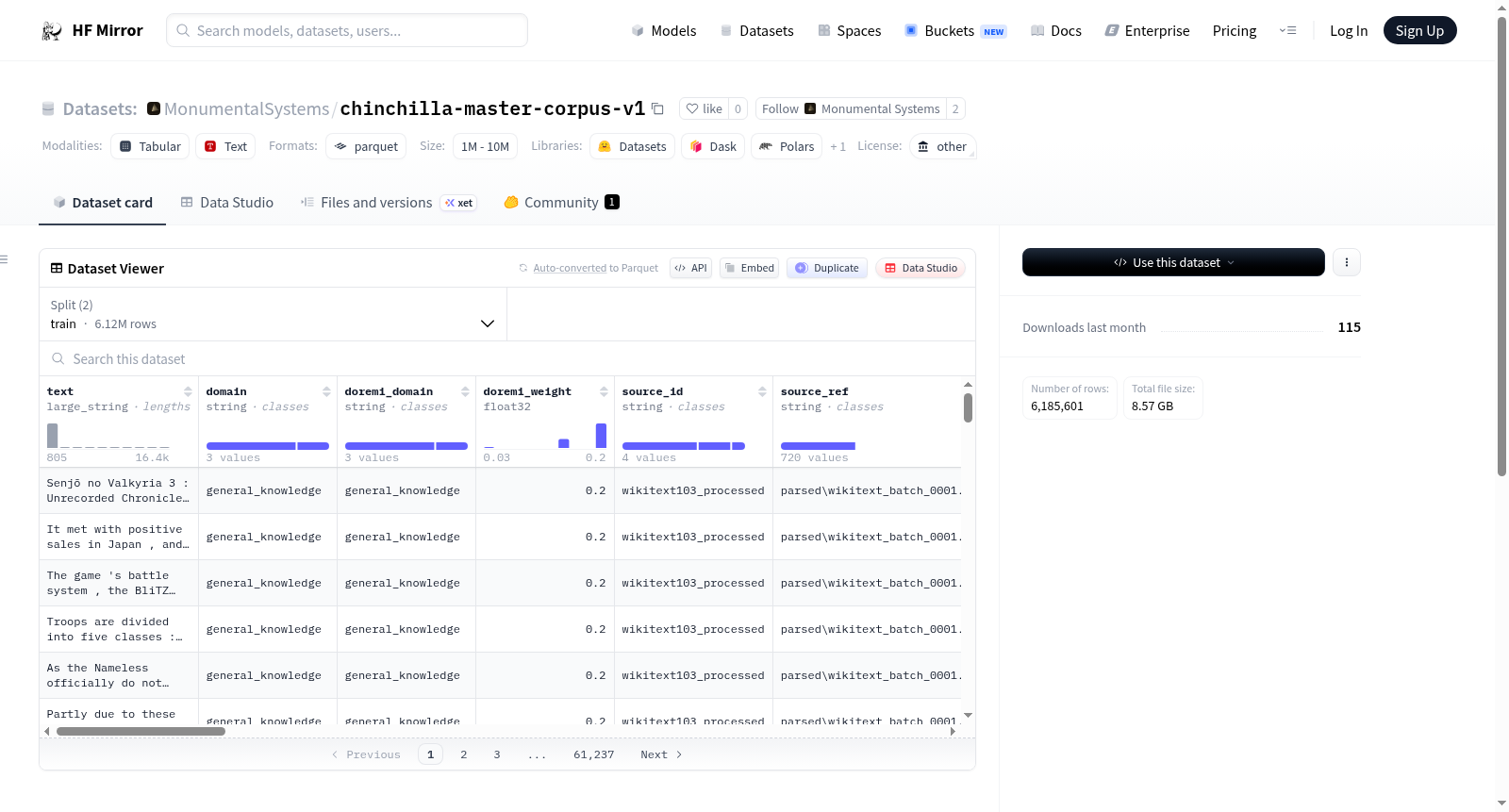
该数据集包含一个经过筛选的文本语料库的parquet分片,分为train和validation两个部分。数据集包含多个重要列,如text、domain、doremi_domain等,提供了丰富的元数据和文本特征。数据集规模在1M到10M之间,格式为parquet。许可证为other,用户在使用前应查阅具体的许可条款。
This dataset contains parquet shards for a curated text corpus with train and validation splits. It includes various notable columns such as text, domain, doremi_domain, etc., providing a rich set of metadata and features. The dataset is categorized under the size range of 1M to 10M entries and is in parquet format. The license is listed as other, indicating that users should review the specific license terms before use.
提供机构:
MonumentalSystems
搜集汇总
数据集介绍
构建方式
Chinchilla Master Corpus v1数据集以parquet格式存储,包含训练集与验证集两个核心划分。该语料库通过严格的文本筛选与质量把控流程构建,利用去重工具(如_dedup.sqlite)确保数据的唯一性,并依据多个维度的元数据字段(如domain、source_type、content_type)对文本来源与内容类型进行系统化归类,从而形成结构清晰、冗余度低的高质量文本集合。
特点
该数据集最显著的特点在于其丰富的注释体系。它不仅记录了文本的原始域和来源信息,还引入了doremi_weight等权重字段以支持动态采样策略,以及reading_level、complexity、flesch、mtld等可读性与复杂度指标,便于下游任务按难度筛选。此外,quality_pass与quality_reason字段明确标记了每段文本的质量审查结果,为模型训练提供了透明的数据质量控制依据。
使用方法
使用者可通过加载parquet文件直接获取text列进行语言模型训练或评估。建议结合doremi_weight字段实施非均匀采样,以优化不同域或难度层级数据的训练效率。同时,借助domain、content_type、curriculum_stage等字段,研究者可以灵活构造专注于特定领域或课程学习阶段的子集,适用于可解释性分析或课程学习等高级训练范式。
背景与挑战
背景概述
Chinchilla Master Corpus v1数据集诞生于大语言模型领域对高质量、大规模文本语料迫切需求的背景下,由致力于研究模型规模与数据量最佳配比的研究机构开发。该数据集的核心研究问题聚焦于如何构建一个经过精心筛选与平衡的文本语料库,以支持像Chinchilla这样的高效语言模型训练。其影响力在于,通过提供包含文本内容、领域标签、可读性指标及课程学习阶段等多维元数据的语料,推动了数据驱动型训练策略的演进,为探索数据质量与模型性能之间的内在关联提供了重要基准。
当前挑战
该数据集所解决的领域问题挑战在于,大语言模型训练往往依赖未经严格筛选的网络文本,导致训练效率低下、模型偏见明显,而Chinchilla Master Corpus v1通过引入域名过滤、可读性评估与质量校验等多层次筛选流程,提升了语料的纯净度与代表性。构建过程中,挑战包括对海量原始文本的清洗与去重(如使用_sqlite进行精确去重)、跨域数据平衡以避免主题倾斜,以及定义并计算复杂度与课程阶段等复合指标,确保语料在语言难度与知识覆盖上的渐进式分布,从而适配不同训练阶段的需求。
常用场景
经典使用场景
在大规模语言模型预训练的研究中,Chinchilla Master Corpus v1 数据集作为精心筛选与质量控制的文本语料库,被广泛用于语言模型的训练与评估。该数据集包含丰富的元信息标签,如文本难度、阅读等级、领域归属及质量控制标记,使得研究者能够基于细粒度属性进行数据筛选与课程学习。经典的使用方式是结合 doremi 加权策略,利用 domain 与 doremi_domain 字段对不同领域的数据进行动态采样,从而在保持语料多样性的同时优化模型在特定领域上的表现。
实际应用
在实际应用层面,Chinchilla Master Corpus v1 支持教育科技领域的自适应学习系统构建,通过利用阅读等级与学科主题标签,可训练出能够根据学习者认知水平动态调整内容呈现的语言模型。此外,内容创作工具可以基于该语料库中标记的文本复杂度与写作风格特征,开发辅助写作与文本润色功能。在信息检索与推荐系统领域,数据集提供的领域分类与内容类型标签能够有效提升文档理解与分类模型的泛化能力,支撑更精准的知识服务。
衍生相关工作
基于 Chinchilla Master Corpus v1,研究者衍生出多项具有影响力的工作。首先,该语料库被用于验证课程学习策略在大规模语言模型训练中的有效性,相关实验揭示了按难度递增编排训练数据能够显著提升模型的收敛速度与最终性能。其次,数据集中丰富的元信息激励了多任务学习框架的探索,研究者利用 domain 与 content_type 标签进行域自适应与迁移学习研究。此外,质量评分标注机制催生了自动化数据清洗与质量评估模型的设计,为后续更高效的语料库构建方法论奠定了实践基础。
以上内容由遇见数据集搜集并总结生成


