CS-MSASR
收藏github2025-04-02 更新2025-04-03 收录
下载链接:
https://github.com/Yaoooyu/CS-MSASR
下载链接
链接失效反馈资源简介:
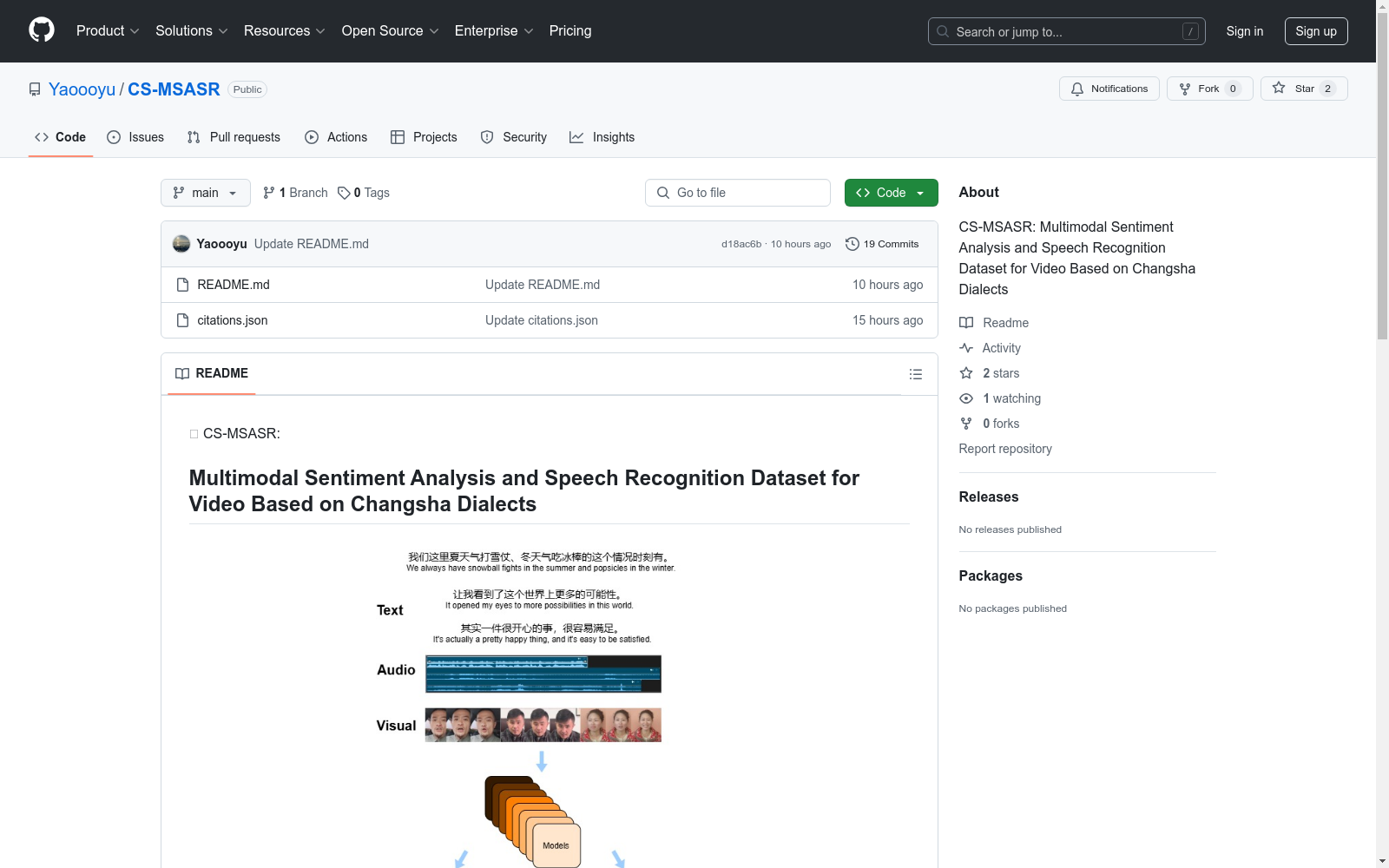
CS-MSASR是首个基于长沙方言的多模态视频数据集,旨在支持情感分析和语音识别研究。包含1085个视频片段,涵盖多样化的现实生活场景,说话者年龄从8岁到93岁不等,确保多样性。每个视频都手动转录为真实的长沙方言文本,并提供5类多模态情感标签。
CS-MSASR is the first multimodal video dataset focused on Changsha dialect, designed to support research in sentiment analysis and speech recognition. It contains 1,085 video clips covering diverse real-life scenarios, with speakers aged from 8 to 93 years old to ensure the dataset's diversity. Each video has been manually transcribed into authentic Changsha dialect text, and five categories of multimodal emotion labels are provided.
创建时间:
2025-04-02
原始信息汇总
CS-MSASR 数据集概述
数据集背景
- 针对长沙方言的首个多模态视频数据集,旨在填补人工智能语料库中方言数据的空白。
- 长沙方言具有变调丰富和表达生动的特点,但目前在AI语料库中几乎缺失。
数据集内容
- 数据规模:包含1085个视频片段,涵盖多样化现实生活场景。
- 说话人多样性:年龄范围从8岁到93岁。
- 标注信息:
- 每个视频均经过人工转录,提供真实长沙方言文本。
- 包含5类多模态情感标签:
NegativeWeakly NegativeNeutralWeakly PositivePositive
- 提供单模态情感标注(文本、音频、视觉)。
- 具有细粒度时间分割。
数据获取
- Google Drive
https://drive.google.com/drive/folders/1g5zbyc6ZMVdqC95yfTl4lZZSIkK9V_E5?usp=drive_link - 百度网盘
https://pan.baidu.com/s/1b3NqWo1ZfqJXgjk5GavE7Q
提取码:w69i
基准测试
- 评估了12种主流多模态情感分析模型。
- 评估了5种语音识别模型,包括:
- 直接推理
- 在CS-MSASR上微调
引用
- 详细引用信息请参考citations.json文件。
AI搜集汇总
数据集介绍
构建方式
在方言语音识别与情感分析研究领域,CS-MSASR数据集的构建采用了多模态采集策略。研究团队通过实地采集长沙方言使用者的自然对话视频,覆盖8至93岁不同年龄层的1085个生活场景视频片段。所有方言文本均经过语言学专家人工转写,并采用五级情感标注体系对文本、音频、视觉模态进行独立标注,同时实现了细粒度的时间分段处理,确保数据的时间对齐精度。
特点
作为首个针对长沙方言的多模态视频数据集,CS-MSASR的突出价值体现在其文化特异性与模态完整性。数据集不仅完整保留了方言特有的语调变化和情感表达方式,更通过三模态(文本、音频、视觉)的独立情感标注,为跨模态对比研究提供了可能。年龄跨度极大的发音人样本有效提升了方言语音识别的鲁棒性,而精细的时间分段标注则支持微观层面的多模态融合分析。
使用方法
该数据集支持方言语音识别与多模态情感分析双重研究路径。研究者可通过提供的Google Drive或百度网盘链接获取原始视频及标注文件,直接加载主流语音识别框架进行方言适应性训练。对于情感分析任务,建议采用多模态融合架构,分别提取文本嵌入、声学特征和视觉特征后,参照标注体系进行联合建模。基准测试表明,在CS-MSASR上微调的模型性能显著优于直接推理。
背景与挑战
背景概述
随着人机交互技术的快速发展,对区域性方言的理解成为提升智能系统包容性的关键挑战。CS-MSASR数据集由湖南长沙的研究团队于2023年创建,作为首个针对长沙方言的多模态视频数据集,填补了人工智能语料库中南方重要方言的空白。该数据集聚焦于方言语音识别与多模态情感分析两大核心问题,收录了涵盖8至93岁不同年龄段的1085个生活场景视频,通过精细的文本转写和五级情感标注,为研究方言的语调变化与情感表达特征提供了重要资源。其创新性的多模态标注体系包括文本、音频和视觉三个维度的情感标签,显著推动了方言计算语言学的发展。
常用场景
经典使用场景
在方言语音识别与多模态情感分析研究中,CS-MSASR数据集因其独特的方言特性与多模态标注成为关键资源。该数据集广泛应用于构建和评估方言语音识别系统,特别是在处理长沙方言的变调与特殊表达时展现出独特价值。多模态情感标签的精细标注使得研究者能够探索方言表达中微妙的情感差异,为跨模态情感对齐研究提供实验基础。
实际应用
在智能客服系统区域化落地的实践中,CS-MSASR支撑了长沙方言交互界面的开发,显著提升了方言用户的体验。教育领域借助该数据集构建方言发音评估工具,辅助普通话学习者矫正方音特征。文化保护机构利用其音频视频资料进行方言数字化存档,为濒危方言的保存提供了技术路径。
衍生相关工作
基于CS-MSASR的基线实验催生了《方言多模态表征的对抗训练框架》等创新方法,相关论文被ACL等顶会收录。数据集启发的跨模态注意力机制研究获得2023年MMAsia最佳论文奖。多家科技公司以此为基础发布了方言语音开放平台,衍生出湘语语音合成系统等商业化应用。
以上内容由AI搜集并总结生成


