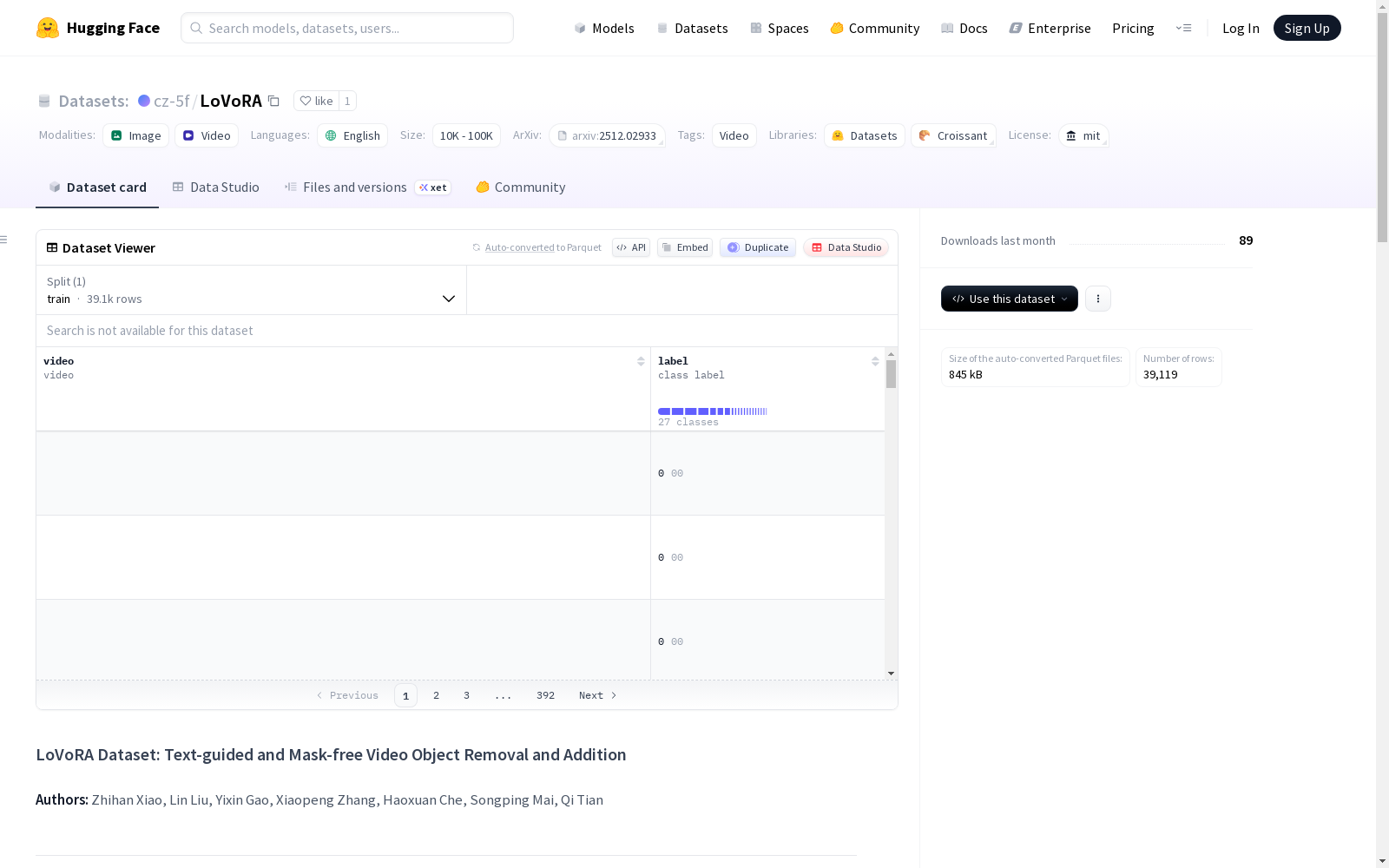
LoVoRA
收藏LoVoRA 数据集概述
基本信息
- 数据集名称: LoVoRA Dataset: Text-guided and Mask-free Video Object Removal and Addition
- 作者: Zhihan Xiao, Lin Liu, Yixin Gao, Xiaopeng Zhang, Haoxuan Che, Songping Mai, Qi Tian
- 许可证: mit
- 主要语言: en
- 标签: Video
数据集简介
LoVoRA 数据集是一个用于文本引导、无需掩码的视频对象移除与添加的高质量基准数据集。该数据集由高保真度的图像编辑对构建并合成为连贯的视频序列,提供对齐的源-目标视频对、时间一致的空时掩码、详细的光流与遮挡图以及指令级的编辑标注。
数据集构建流程
- 图像到视频(I2V)转换
- 从编辑后的图像生成掩码
- 光流估计
- 使用光流和遮挡图进行掩码传播
- 高质量视频修复
数据集对比
LoVoRA 在基于提示跟随(PF)和编辑质量(EQ)的 VLM 评估中取得了最先进的结果:
| 数据集 | PF | EQ | 生成基础 |
|---|---|---|---|
| InsV2V | -- | -- | Prompt-to-Prompt adaptation |
| ICVE-SFT | -- | -- | Object removal + inpainting |
| Senorita-2M | 3.533 | 3.883 | Object removal + inpainting |
| InsViE-1M | 3.133 | 3.667 | Video inversion + reconstruction |
| Ditto | 4.417 | 4.733 | Depth-guided generation |
| LoVoRA | 4.375 | 4.850 | Optical-flow-based mask propagation |
数据结构
每个样本包含以下组件: json { "tar_video": "src_video/XX/image_XXX.mp4", "src_video": "tar_video/XX/image_XXX.mp4", "object_file_path": "reference/XX/image_XXX/src_ref_image-image_reference.png", "text": "Change ...", "mask_file_path": "mask_video/XX/image_XXX.mp4" }
下载与使用
可通过以下方式下载整个数据集: python from datasets import load_dataset dataset = load_dataset("cz-5f/LoVoRA")
metadata.json 中的每条记录提供了视频、参考图像、掩码和文本指令的必要文件路径。实际的视频和掩码文件以上述目录结构中独立的 .mp4 资源形式存储。
应用场景
- 视频对象移除、添加与替换
- 空时掩码预测
- 基于光流的掩码传播
引用
若使用此数据集,请引用: bibtex @misc{xiao2025lovoratextguidedmaskfreevideo, title={LoVoRA: Text-guided and Mask-free Video Object Removal and Addition with Learnable Object-aware Localization}, author={Zhihan Xiao and Lin Liu and Yixin Gao and Xiaopeng Zhang and Haoxuan Che and Songping Mai and Qi Tian}, year={2025}, eprint={2512.02933}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2512.02933}, }
相关链接
- 数据集地址: https://huggingface.co/datasets/cz-5f/LoVoRA
- 项目主页: https://cz-5f.github.io/LoVoRA.github.io
- 论文: https://arxiv.org/abs/2512.02933
- GitHub: https://github.com/cz-5f/LoVoRA.github.io