MedConceptsQA
收藏arXiv2024-05-15 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/ofir408/MedConceptsQA
下载链接
链接失效反馈官方服务:
资源简介:
MedConceptsQA是一个开放源代码的医学概念问答基准数据集,由本古里安大学软件与信息系统工程系的研究团队创建。该数据集包含超过800,000个问题,涵盖诊断、程序和药物等多种医学概念,并分为简单、中等和困难三个难度级别。数据集的创建过程涉及使用PyHealth工具将医学代码词汇表表示为无向图,并根据不同难度级别随机选择或按距离选择替代医学代码。该数据集主要用于评估大型语言模型在医学领域的理解和推理能力,特别是对于临床大型语言模型(CLLMs)的性能评估。
MedConceptsQA is an open-source medical concept question answering benchmark dataset created by the research team from the Department of Software and Information Systems Engineering at Ben-Gurion University of the Negev. This dataset contains over 800,000 questions covering various medical concepts including diagnosis, procedures and medications, and is divided into three difficulty levels: simple, medium and hard. The dataset construction process utilized the PyHealth tool to represent medical code vocabularies as undirected graphs, and alternative medical codes were selected either randomly or based on graph distance corresponding to different difficulty tiers. This dataset is primarily applied to evaluate the understanding and reasoning capabilities of large language models in the medical domain, particularly the performance of clinical large language models (CLLMs).
提供机构:
本古里安大学软件与信息系统工程系
创建时间:
2024-05-13
搜集汇总
数据集介绍
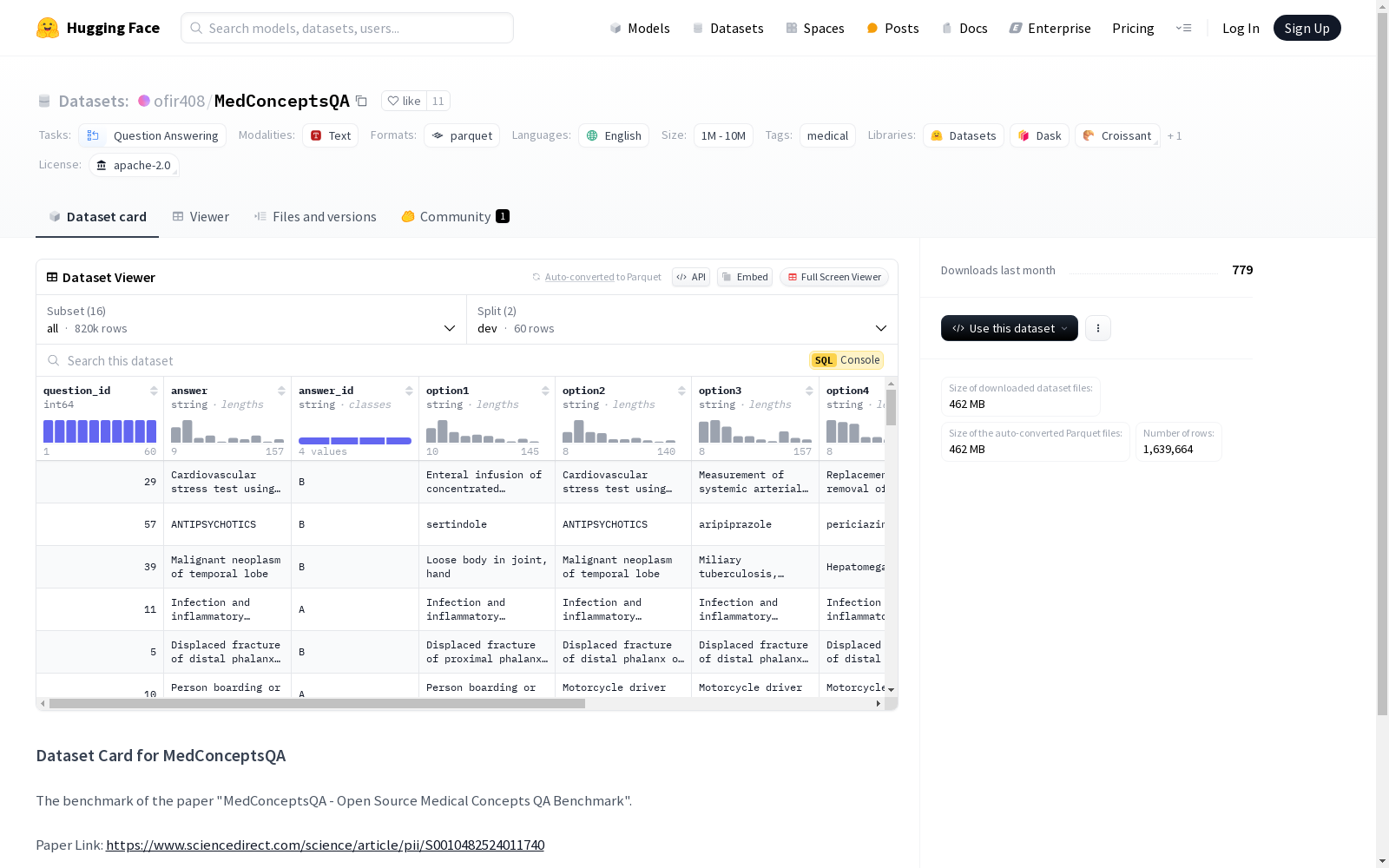
构建方式
MedConceptsQA数据集通过精心设计,涵盖了诊断、手术和药物等多个医学概念领域,包含超过80万个问题和答案。数据集中的问题基于ICD9-CM、ICD10-CM诊断代码,ICD9-PROC和ICD10-PROC手术代码,以及ATC药物代码。每个问题被分为三个难度级别:简单、中等和困难。难度级别的划分基于选项与正确答案之间的语义距离,简单级别选项随机选择,中等级别选项与正确答案的距离为三到五条边,而困难级别选项与正确答案的距离仅为两条边。这种设计确保了数据集的多样性和挑战性,能够有效评估大型语言模型在医学概念理解上的能力。
使用方法
MedConceptsQA数据集适用于评估和训练大型语言模型在医学概念理解和推理方面的能力。用户可以通过零样本学习和少样本学习两种方式对模型进行评估,其中少样本学习使用4个示例来引导模型回答问题。数据集的广泛应用场景包括医学问答系统、临床文本分类、医疗教育以及医学文本生成等。通过使用该数据集,研究人员可以深入分析模型在不同医学概念和难度级别上的表现,从而优化和改进模型的性能。
背景与挑战
背景概述
MedConceptsQA数据集由Ben-Gurion大学的Ofir Ben Shoham和Nadav Rappoport领导的研究团队创建,旨在为医学概念问答提供一个开源基准。该数据集包含了超过800,000个问题,涵盖了诊断、手术和药物等多个医学词汇,并根据难度分为简单、中等和困难三个级别。其核心研究问题在于评估大型语言模型(LLMs)对医学概念的理解和推理能力,尤其是在临床语言模型(CLLMs)中的表现。尽管CLLMs在医学数据上进行了预训练,但在该基准测试中,其表现接近随机猜测,而GPT-4等通用LLMs则表现出显著的改进。MedConceptsQA的推出为医学领域的LLMs评估提供了宝贵的资源,推动了医学自然语言处理的发展。
当前挑战
MedConceptsQA数据集面临的主要挑战包括:首先,构建过程中需要处理大量复杂的医学代码和词汇,确保问题的多样性和难度分布合理。其次,尽管CLLMs在医学数据上进行了预训练,但在该基准测试中表现不佳,显示出对医学概念理解的不足。此外,通用LLMs如GPT-4虽然在基准测试中表现较好,但其准确性仍未达到理想水平,尤其是在处理复杂医学代码时。最后,数据集的评估方法需要进一步优化,以确保能够准确反映模型的实际表现,并为未来的模型改进提供指导。
常用场景
经典使用场景
MedConceptsQA 数据集的经典应用场景在于评估大型语言模型(LLMs)在医学概念理解和推理方面的能力。该数据集包含了超过80万道涉及诊断、手术和药物等医学概念的多选题,分为简单、中等和困难三个难度级别。通过这些题目,研究者可以测试模型在不同医学术语和编码体系中的表现,尤其是临床大型语言模型(CLLMs)在处理医学编码和概念时的准确性。
解决学术问题
MedConceptsQA 数据集解决了当前临床大型语言模型在医学概念理解上的不足问题。尽管这些模型经过医学数据的预训练,但在处理医学编码和概念时,其表现接近随机猜测。该数据集通过提供大量多样化的医学概念问题,揭示了现有模型在医学推理上的局限性,并为未来的模型改进提供了基准。其意义在于推动医学领域中LLMs的进一步发展,特别是在提高模型对医学术语和编码的理解能力方面。
实际应用
MedConceptsQA 数据集在实际应用中具有广泛的前景,特别是在医学教育和临床决策支持系统中。例如,它可以用于开发智能医学问答系统,帮助医生和医学生快速准确地理解复杂的医学编码和概念。此外,该数据集还可以用于训练和评估医学聊天机器人,提升其在处理患者咨询和提供医学建议时的准确性和可靠性。通过这些应用,MedConceptsQA 有助于提高医疗服务的质量和效率。
数据集最近研究
最新研究方向
MedConceptsQA数据集的最新研究方向主要集中在评估大型语言模型(LLMs)在医学概念理解和推理方面的能力。该数据集通过涵盖诊断、手术和药物等多个医学领域的标准化编码,设计了不同难度级别的问题,旨在测试模型对医学概念的深度理解。研究结果表明,尽管临床专用的大型语言模型(CLLMs)在医学数据上进行了预训练,但在该基准测试中的表现接近随机猜测,而通用语言模型如GPT-4在零样本和少样本学习中表现出显著优势,尤其是在理解复杂医学概念方面。未来的研究方向可能包括改进CLLMs的训练方法,以提升其在医学概念理解和推理任务中的表现,并探索更多样化的医学编码体系以扩展数据集的应用范围。
相关研究论文
- 1MedConceptsQA: Open Source Medical Concepts QA Benchmark本古里安大学软件与信息系统工程系 · 2024年
以上内容由遇见数据集搜集并总结生成


