Hacker News OpenAI Embeddings
收藏www.kaggle.com2023-06-11 更新2025-03-24 收录
下载链接:
https://www.kaggle.com/julien040/hacker-news-openai-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
# Hacker News Posts with Text Embeddings
*Disclaimer: I'm not affiliated with Y Combinator*
## Description
This dataset contains more than 100,000 posts from Hacker News, a social news website focusing on computer science and entrepreneurship. The dataset includes the following fields for each post:
- `id`: the story id (primary key)
- `title`: the story title
- `url`: the story url
- `score`: the story score
- `time`: the timestamp of the story
- `comments`: the number of comments
- `author`: the author of the story
- `embeddings`: an array of 1536 floats representing the story embedding
The dataset is licensed under CC BY-NC-SA 4.0 and contains only stories that have a score greater than 100. The text of each article was extracted from the link and embeddings were computed using the `text-ada-embeddings-002` model from OpenAI.
## Data Collection
The data was collected using the Hacker News API. I have written a blog post explaining how I have fetched the articles and computed the embeddings. You can find the post [here](https://julienc.me/articles/Extract_embeddings_Hacker_News_article).
## Data Visualizations
In this section, I will include some visualizations of the data to help users better understand the dataset.
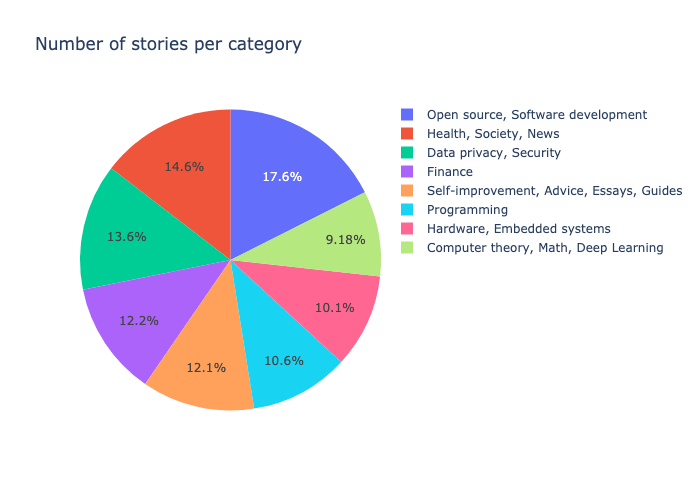
Figure 1: Distribution of the stories in the dataset.
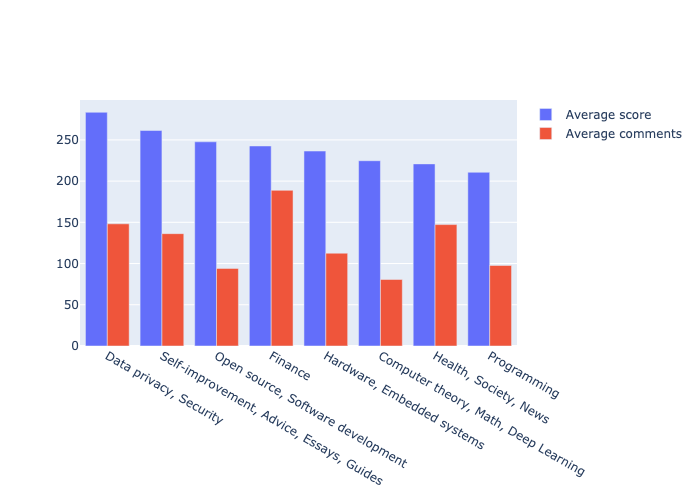
Figure 2: Relationship between the number of comments and the score for the stories in the dataset.
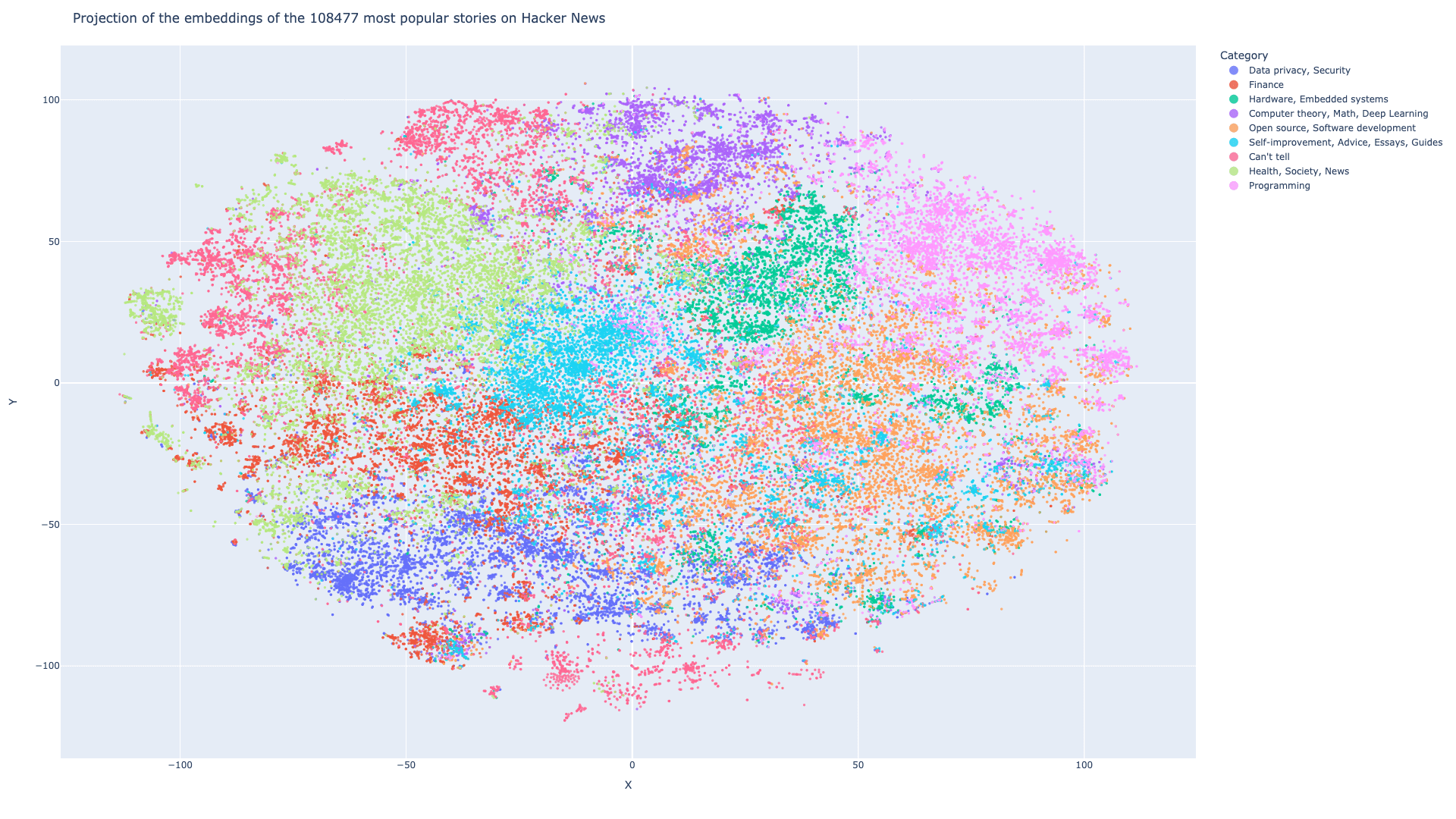
Figure 3: t-SNE projection of the story embeddings.
## Future Updates
I plan to update this dataset regularly to include new stories from Hacker News. I may also add new fields to the dataset based on user feedback and suggestions. If you have any comments or suggestions, please feel free to contact me.
## Usage
This dataset can be used for various natural language processing tasks such as text classification, clustering, and sentiment analysis. The embeddings can also be used for tasks such as similarity search and recommendation systems.
## Citation
If you use this dataset in your research, please cite the following:
```bibles
@misc{julien cagniart_2023,
title={Hacker News OpenAI Embeddings},
url={https://www.kaggle.com/dsv/5901263},
DOI={10.34740/KAGGLE/DSV/5901263},
publisher={Kaggle},
author={Julien CAGNIART},
year={2023}
}
```
## Acknowledgements
Thanks to Diffbot for providing their APIs for free to extract the text of the articles.
## Example Usage
Here is an example of how to import the `story.csv` file using Pandas and convert the `embeddings` column from JSON to a numpy array:
```python
import pandas as pd
import numpy as np
import json
# Load the dataset
df = pd.read_csv('story.csv')
# Convert the embeddings column from JSON to numpy array
df['embeddings'] = df['embeddings'].apply(lambda x: np.array(json.loads(x)))
```
Now the `embeddings` column contains a numpy array of shape `(1536,)` for each story.
{'#Disclaimer': '本声明声明本人与Y Combinator无任何关联关系', '#Description': '本数据集收录了超过10万篇来自Hacker News(一个专注于计算机科学和创业的社交新闻网站)的帖子。数据集包含每篇帖子的以下字段:
- `id`:故事ID(主键)
- `title`:故事标题
- `url`:故事链接
- `score`:故事评分
- `time`:故事时间戳
- `comments`:评论数量
- `author`:故事作者
- `embeddings`:表示故事嵌入的1536个浮点数的数组
数据集采用CC BY-NC-SA 4.0许可协议,仅包含评分大于100的故事。每篇文章的文本均从链接中提取,嵌入值使用OpenAI的`text-ada-embeddings-002`模型计算得出。', '#Data Collection': '数据通过Hacker News API收集。本人已撰写博客文章,详细解释了如何获取文章并计算嵌入值。相关文章链接[在此](https://julienc.me/articles/Extract_embeddings_Hacker_News_article)。', '#Data Visualizations': '本节将包含一些数据可视化,以帮助用户更好地理解数据集。

图1:数据集中故事类型的分布。

图2:数据集中故事评论数量与评分之间的关系。

图3:故事嵌入的t-SNE投影。', '#Future Updates': '本人计划定期更新此数据集,以包含来自Hacker News的新故事。根据用户反馈和建议,数据集可能还会添加新字段。如果您有任何评论或建议,请随时与我联系。', '#Usage': '本数据集可用于各种自然语言处理任务,如文本分类、聚类和情感分析。嵌入值也可用于相似度搜索和推荐系统。', '#Citation': '如果您在研究中使用了本数据集,请引用以下内容:
bibles
@misc{julien cagniart_2023,
title={Hacker News OpenAI Embeddings},
url={https://www.kaggle.com/dsv/5901263},
DOI={10.34740/KAGGLE/DSV/5901263},
publisher={Kaggle},
author={Julien CAGNIART},
year={2023}
}
', '#Acknowledgements': '感谢Diffbot免费提供其API,用于提取文章文本。', '#Example Usage': "以下是如何使用Pandas导入`story.csv`文件,并将`embeddings`列从JSON转换为numpy数组的示例:
python
import pandas as pd
import numpy as np
import
# 加载数据集
df = pd.read_csv('story.csv')
# 将embeddings列从JSON转换为numpy数组
df['embeddings'] = df['embeddings'].apply(lambda x: np.array(.loads(x)))
# 现在embeddings列包含每个故事的形状为`(1536,)`的numpy数组。
"}
提供机构:
www.kaggle.com


