BrunoHays/english-en-x-code-switching-main-lang
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/BrunoHays/english-en-x-code-switching-main-lang
下载链接
链接失效反馈官方服务:
资源简介:
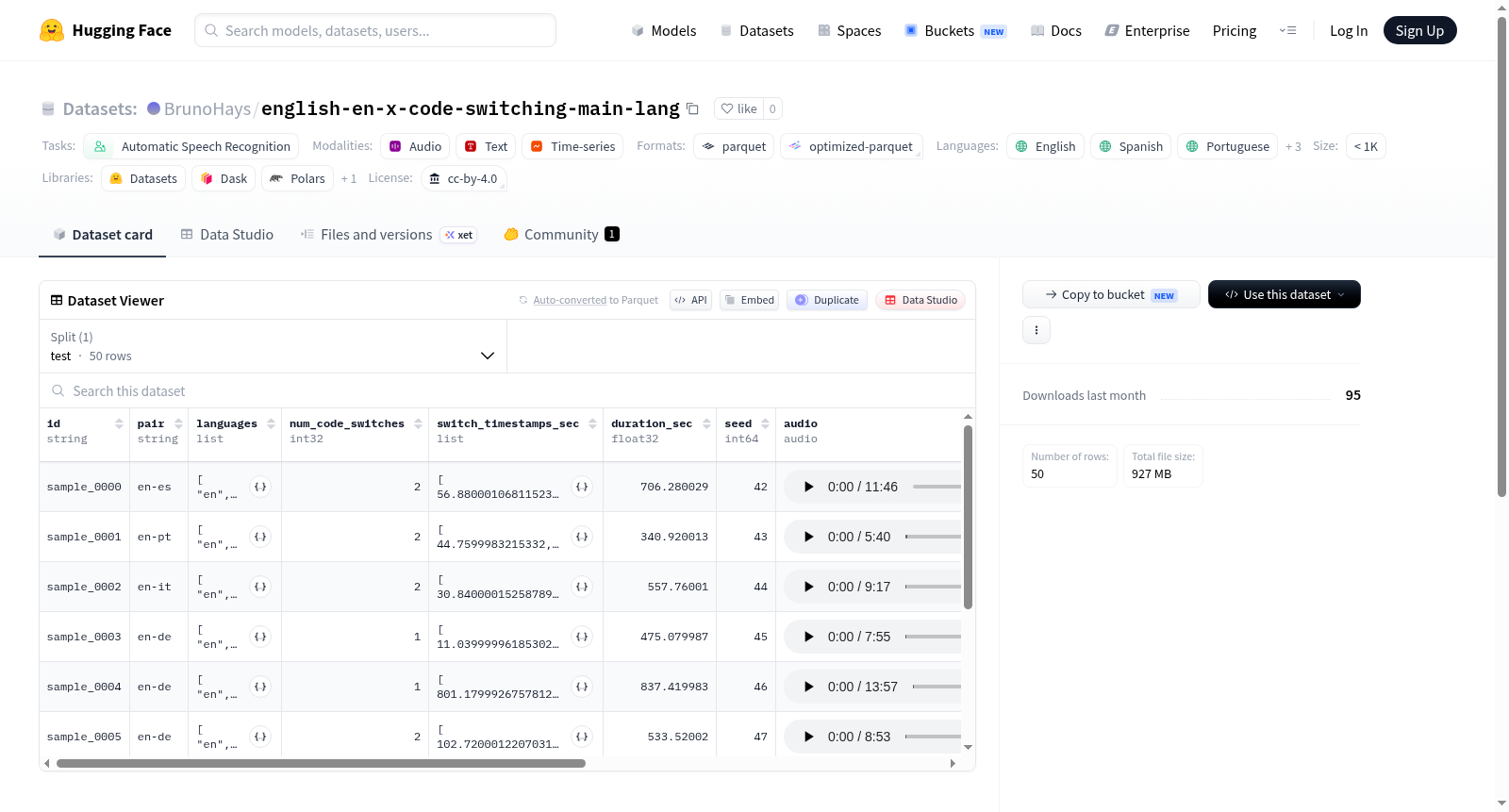
该数据集包含从FLEURS构建的合成的英语加另一种语言的代码转换样本。源数据来自google/fleurs,经过重新采样到16000 Hz。生成器使用种子42创建了50个混合样本,每个样本包含英语和西班牙语、葡萄牙语、法语、德语或意大利语中的一种。每个选定的发声在连接前经过RMS归一化到-20.0 dBFS,峰值限制在0.99。混合数据集存储了带有语言标签和时间戳的转录文本,而样本数据集则单独存储每个完整的发声块,并通过parent_id链接回原始数据。
This dataset contains synthetic English-plus-one-language code-switching samples built from FLEURS. Source data is `google/fleurs` at revision `refs/convert/parquet`, split `test`, resampled to 16000 Hz. The generator uses seed `42` and creates 50 mixed samples. Each mixed sample contains English and exactly one of Spanish, Portuguese, French, German, or Italian, sampled uniformly. Each selected utterance is RMS-normalized to -20.0 dBFS before concatenation, with peak limiting at 0.99. The mixed dataset stores transcription with language tags and timestamps, while the samples dataset stores each full utterance chunk separately and links it back with `parent_id`.
提供机构:
BrunoHays
搜集汇总
数据集介绍
构建方式
该数据集基于FLEURS语料库构建,选取其测试集子集,并将所有音频重采样至16kHz。通过设定随机种子42,为每一条英语-西班牙语、葡萄牙语、法语、德语或意大利语的双语组合生成50条混合样本,语言对均匀采样。每条参与混合的语音片段首先经过均方根归一化至-20.0 dBFS,并施加0.99的峰值限制,而后进行拼接,确保合成语音的声学一致性。
特点
数据集具有鲜明的代码转换特性,每条样本均包含英语与另一选定语言的交替片段。混合样本以带时间戳的标签形式记录转录文本,标记每个语言片段起始与结束时刻,便于后续对齐与分析。独立样本集则保留每条完整语音片段及其对应的父样本ID,而合并样本集将相邻同语言片段整合为单一语言段落行,显著提升了分割与标注的灵活性。
使用方法
该数据集适用于自动语音识别系统中的代码转换研究,尤其适合训练和评估多语言混合语音模型。用户可直接加载混合样本进行端到端转录,或利用带时间戳的标签提取特定语言段落。独立与合并两种格式支持按需选取词级或句级对齐粒度,便于开展双语标注、语言边界检测或跨语言声学建模等任务。
背景与挑战
背景概述
该数据集创建于近年来,由研究团队基于FLEURS语料库生成,旨在解决多语言代码转换语音识别中的关键问题。核心研究问题聚焦于如何构建包含英语与西班牙语、葡萄牙语、法语、德语及意大利语中的一种语言混合的合成语音样本。通过采用固定种子和标准化预处理流程,该数据集为自动语音识别领域提供了高质量的多语言混合训练与评估基准,对推动跨语言语音技术的进步具有显著影响力。
当前挑战
数据集所解决的领域挑战在于自动语音识别系统对代码转换语音的识别性能低下,尤其是英语与多种欧洲语言混合的复杂场景。构建过程中面临的技术挑战包括:确保合成样本的声学自然性,通过RMS归一化和峰值限制避免拼接失真;精确标注语言切换边界,采用时间戳标记转录文本;处理多语言音频段的均匀采样与平衡,避免语言分布偏斜导致的模型过拟合问题。
常用场景
经典使用场景
该数据集通过合成英语与另一种语言(西班牙语、葡萄牙语、法语、德语或意大利语)的语码转换音频,为多语言语音识别系统提供了高质量的基准测试和训练资源。其经典使用场景包括评估和提升端到端自动语音识别模型在跨语言混合语境下的理解能力,尤其是在处理自然对话中频繁出现的语言交替现象时。研究人员利用此数据集可系统地分析模型对语码转换边界的感知精度、各语言片段的识别准确性以及多语言纠缠带来的挑战。
解决学术问题
该数据集有效解决了多语言语音识别中语码转换数据稀缺的核心问题。在学术研究中,传统单语言数据集难以覆盖真实世界中的语言混合现象,导致模型在处理非单一语言输入时性能显著下降。通过提供结构化、可重复的合成语码转换样本,该数据集使研究者能定量评估并改进模型在多语言动态切换环境下的鲁棒性,推动了跨语言语音理解理论的发展。
衍生相关工作
基于该数据集,衍生出一系列聚焦于语码转换建模的经典工作,包括研究不同语言对齐策略对识别性能的影响、探索端到端模型在混合语言输入下的注意力机制变化,以及开发语言边界检测与多任务学习的统一框架。此外,该数据集也启发了基于对比学习的跨语言表示增强方法,以及将合成数据与真实语码转换数据结合以提升泛化能力的半监督训练范式。
以上内容由遇见数据集搜集并总结生成


