PowerZooDataset
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/PowerZooJax/PowerZooDataset
下载链接
链接失效反馈官方服务:
资源简介:
PowerZoo数据集是一个包含真实世界电力系统和数据中心时间序列数据的开源数据集,专为强化学习和预测研究设计。数据集包含:1) 11个来自公共监管机构和云服务提供商的parquet时间序列文件,涵盖英国和澳大利亚的电力负荷、燃料发电、日前预测和市场中间价格,以及阿里巴巴、Azure和Google的数据中心利用率数据;2) 14个电力网络案例文件,覆盖从5到2383个总线的输电系统和从33到533个总线的配电系统;3) 11个JSON清单文件,用于将原始列映射到共享规范模式。数据集适用于时间序列预测、表格回归和强化学习任务,特别适合电力系统优化、负荷预测和数据中心能源管理研究。数据规模在1M到10M之间,包含多种时间分辨率(5分钟到30分钟)。数据集采用混合上游许可证,用户需遵守各自原始数据源的许可条款。
The PowerZoo dataset is an open-source dataset containing real-world power system and data center time series data, specifically designed for reinforcement learning and forecasting research. The dataset includes: 1) 11 parquet time series files from public regulatory agencies and cloud service providers, covering electricity load, fuel generation, day-ahead forecasts, and market clearing prices in the UK and Australia, as well as data center utilization data from Alibaba, Azure, and Google; 2) 14 power network case files, covering transmission systems from 5 to 2383 buses and distribution systems from 33 to 533 buses; 3) 11 JSON manifest files for mapping raw columns to a shared canonical schema. The dataset is suitable for time series forecasting, tabular regression, and reinforcement learning tasks, particularly for power system optimization, load forecasting, and data center energy management research. The data size ranges from 1M to 10M, with various time resolutions (5 minutes to 30 minutes). The dataset uses a mixed upstream license, and users must comply with the license terms of the respective original data sources.
创建时间:
2026-05-04
原始信息汇总
PowerZoo 数据集详情
数据集概览
PowerZoo 是一个面向电力系统和数据中心领域的真实世界时间序列数据集,结合了规范电网拓扑结构和 JSON 映射清单,专为强化学习和预测研究设计。数据集位于 Hugging Face 平台,ID 为 PowerZooJax/PowerZooDataset。
主要特征:
- 语言: 英文
- 规模: 100 万至 1000 万行(1M < n < 10M)
- 任务类型: 时间序列预测、表格回归、强化学习
- 标签: 电力系统、电力、强化学习、基准测试、时间序列、智能电网、数据中心、负荷预测、最优潮流
数据集内容
数据集包含三大类资源:
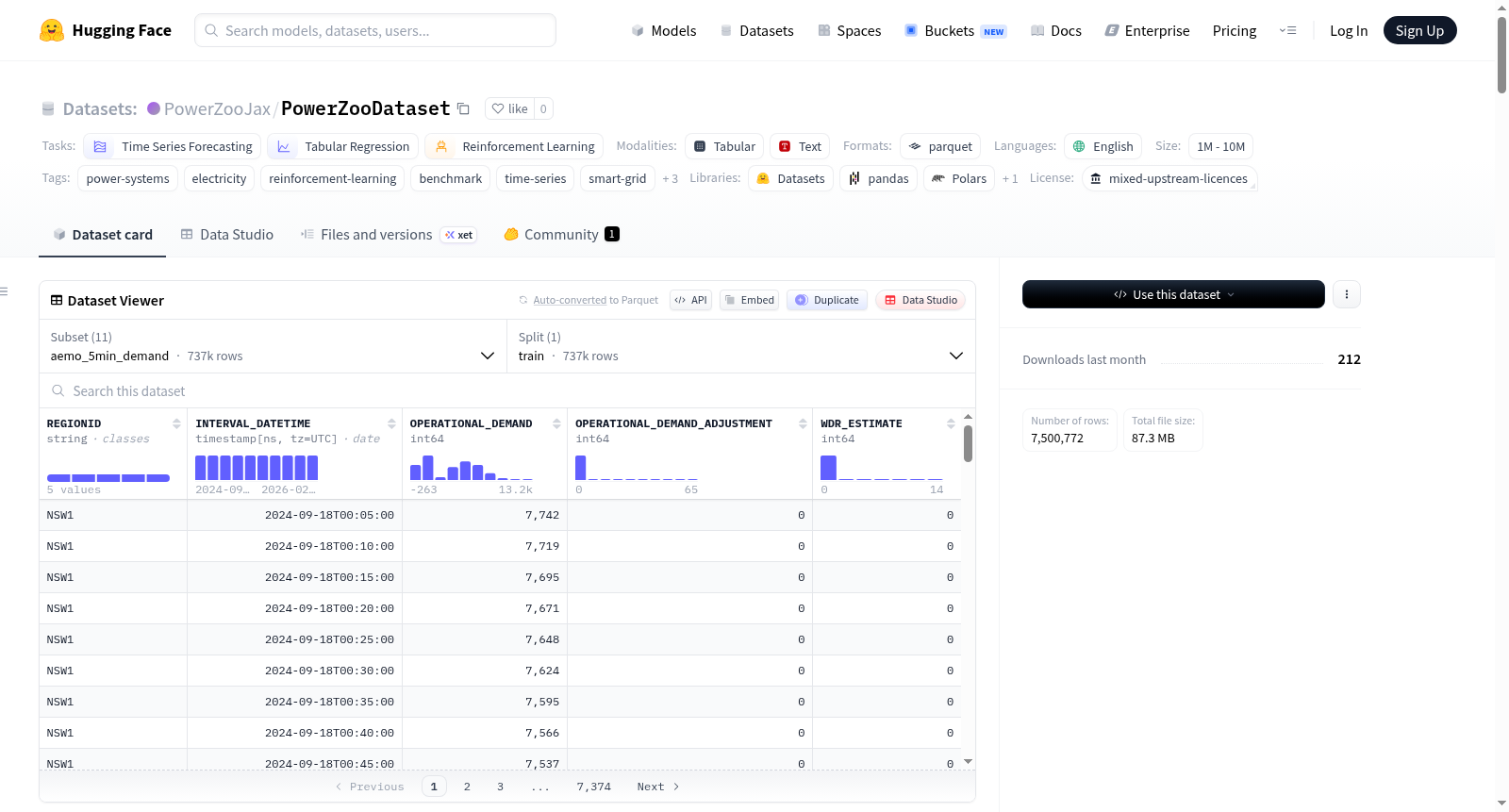
1. 时间序列 Parquet 文件(共 11 个)
| 文件名 | 领域 | 时间分辨率 | 行数 | 列数 | 文件大小 |
|---|---|---|---|---|---|
AEMO_5min_Demand_2025_2026.parquet |
澳大利亚 NEM 需求(5 个区域) | 5 分钟 | 737,400 | 5 | 6.5 MB |
AEMO_Forecast_vs_Actual_2025.parquet |
澳大利亚 NEM 概率预测 vs 实际 | 30 分钟 | 89,145 | 10 | 1.6 MB |
Ausgrid_Zone_Substation_FY25_imputed_15min.parquet |
新南威尔士州变电站(175 个站点) | 15 分钟 | 6,095,040 | 4 | 60 MB |
GB_NESO_Demand_2009_2025_30min.parquet |
英国 NESO 历史需求 | 30 分钟 | 285,454 | 22 | 4.7 MB |
GB_Forecast_Actual_Demand_2023_2025_30min.parquet |
英国日前预测 vs 实际 | 30 分钟 | 48,283 | 3 | 0.8 MB |
GB_Gen_by_Type_2016_2025_30min.parquet |
英国按燃料类型发电量 | 30 分钟 | 180,048 | 13 | 6.2 MB |
MID_GB_30min_aligned_to_gen.parquet |
英国 APX/N2EX 中间价格与成交量 | 30 分钟 | 48,283 | 6 | 0.8 MB |
alibaba_dc_2018_300s.parquet |
阿里巴巴生产集群(CPU/内存/网络/磁盘) | 5 分钟 | 2,243 | 6 | 0.1 MB |
alibaba_gpu_2020_300s.parquet |
阿里巴巴 GPU 集群(GPU/CPU 利用率) | 5 分钟 | 415 | 3 | <0.1 MB |
azure_dc_v2_300s.parquet |
Azure VM 追踪 v2(CPU、已分配内存) | 5 分钟 | 8,640 | 3 | 0.2 MB |
google_dc_2019_300s.parquet |
Google Borg 2019(CPU/内存/CPI) | 5 分钟 | 8,064 | 5 | 0.3 MB |
每个 Parquet 文件附带一个 JSON 元数据文件,包含来源 URL、来源组织、生成时间戳、列数据类型、区域/类别枚举及时区约定。
2. 电力网络案例文件(共 14 个)
位于 powergrid_case/ 目录下,提供统一的 Python 表示,分为输电和配电系统:
输电系统(高压):
| 文件 | 母线数 | 来源 | 描述 |
|---|---|---|---|
transmission/Case5.py |
5 | MATPOWER | IEEE 5 母线测试系统 |
transmission/Case14.py |
14 | MATPOWER | IEEE 14 母线测试系统 |
transmission/Case29GB.py |
29 | 自定义 | 英国简化 29 母线输电网络 |
transmission/Case118.py |
118 | MATPOWER | IEEE 118 母线测试系统 |
transmission/Case300.py |
300 | MATPOWER | IEEE 300 母线测试系统 |
transmission/Case552GB.py |
552 | 英国 | 英国 552 母线输电系统 |
transmission/Case1354pegase.py |
1354 | MATPOWER | 欧洲 PEGASE 1354 母线系统 |
transmission/Case2383wp.py |
2383 | MATPOWER | 波兰 2383 母线冬季峰值系统 |
配电系统中压:
| 文件 | 母线数 | 来源 | 描述 |
|---|---|---|---|
distribution/Case33bw.py |
33 | MATPOWER | IEEE 33 母线 Baran & Wu 径向配电系统 |
distribution/Case118zh.py |
118 | MATPOWER | 118 母线 Zhang 配电系统 |
distribution/Case123.py |
123 | MATPOWER | IEEE 123 母线三相配电系统 |
distribution/Case141.py |
141 | MATPOWER | 141 母线 Caracas 配电系统 |
distribution/Case533mt_hi.py |
533 | MATPOWER | 533 母线瑞典配电系统(高负荷) |
distribution/Case533mt_lo.py |
533 | MATPOWER | 533 母线瑞典配电系统(低负荷) |
每个案例文件继承 ClearCase 基类,暴露四个 Pandas DataFrame 表(节点、机组、线路、负荷),使用 MATPOWER 兼容单位(MW、MVAr、p.u.)。
3. JSON 映射清单(共 11 个)
位于 manifests/ 目录下,为每个 Parquet 文件提供列映射规则,将原始列转换为共享规范模式,包含:
column_map:列重命名规则index_map:索引列定义(日期时间、区域等)derived:派生列定义normalize:归一化缩放因子time_mode:时间模式(日历或周期)- 来源信息、区域值、日期范围等
数据模式约定
- 时间戳: 日历模式文件存储为 UTC 时区的
datetime64[ns],GB NESO 需求数据除外(使用SETTLEMENT_DATE+SETTLEMENT_PERIOD两列索引) - 周期模式: 数据中心追踪标记为
time_mode = "profile"和cyclical = true,作为周期性外生信号使用 - 插补:
Ausgrid_Zone_Substation_FY25_imputed_15min.parquet包含插补值,插补方法未记录 - 单位: 电力列为 MW,市场价格列为 £/MWh,数据中心利用率为 0–100%
数据来源与许可
数据集从以下公共来源衍生:
- AEMO(澳大利亚能源市场运营商)
- Ausgrid(澳大利亚配电公司)
- Elexon BMRS(英国电力市场)
- NESO(英国国家能源系统运营商)
- Alibaba Group(阿里巴巴集群追踪)
- Microsoft(Azure 公共数据集)
- Google(Google 集群数据)
各上游数据受其自身许可条款约束,用户需自行遵守。数据集的打包制品(映射清单、案例文件、模式协调逻辑)计划以宽松开源许可发布。
预期用途与限制
预期用途:
- 强化学习研究
- 负荷/发电预测
- 最优潮流基准测试
- 配电系统控制
- 数据中心功耗优化
- 需求响应研究
限制:
- 发布时的静态快照,上游数据持续更新
- 仅覆盖英国和澳大利亚地理范围
- Ausgrid 追踪包含未记录方法的插补值
- 数据中心追踪仅提供映射列的 5 分钟分辨率数据
- 电网案例参数与命名源系统一致,但并非字节级相同
搜集汇总
数据集介绍
构建方式
PowerZooDataset汇聚了来自电力系统与数据中心领域的多源时序数据与电网拓扑案例。其构建过程首先从澳大利亚能源市场运营商、英国Elexon和国家电网、阿里巴巴、微软Azure、谷歌等权威机构公开的监管与云平台数据中,提取了11个Parquet格式的时间序列文件,覆盖电力负荷、发电构成、日前预测、市场电价及数据中心利用率等关键指标。数据集同时集成了14个Python定义的电力网络案例文件,涵盖5至2383个节点的输电网与33至533个节点的配电网。为统一多源异构数据,项目设计了11个JSON清单文件,将原始列的命名与单位映射至规范化的公用模式,并附加缩放因子与时区信息,使得来自不同数据源的轨迹能够在同一实验框架下无缝组合。
特点
该数据集的核心特点在于其高度结构化与跨域兼容性。时序数据在格式上统一为Parquet列式存储,并附带详尽的元数据JSON,记录了来源机构、生成时间戳、列类型、区域枚举及时区约定。电网案例则采用统一的ClearCase基类,以MATPOWER兼容的单位提供节点、机组、线路与负荷四张表格,便于直接调用电力系统分析函数。特别值得注意的是,数据中心轨迹被标记为‘配置文件模式’,作为周期性外生信号而非绝对日历序列使用。此外,数据集通过清单文件中的派生字段定义,支持闭式推导运算,如将多种发电类型聚合为风能可用出力,极大地增强了数据的灵活性与研究适配性。
使用方法
研究人员可通过多种方式加载该数据集。最直接的方式是使用Pandas结合huggingface_hub下载单个Parquet文件并读取。亦可利用Hugging Face的datasets库,按配置名称(如aemo_5min_demand)加载指定子集。对于强化学习或预测基准研究,推荐安装PowerZooJax基准包,通过其DataLoader类同时指定数据目录与清单目录,实现自动化加载与归一化。电网案例则通过Python直接导入对应模块,实例化后即可调用拓扑检查与节点功率传输分布因子计算等方法。使用时需注意,部分数据如GB NESO历史需求采用双列索引,需依照清单中的datetime_recipe字段重构时间戳,而数据中心轨迹的epoch时间锚点亦为正确解析的关键。
背景与挑战
背景概述
PowerZooDataset诞生于电力系统与数据中心交叉研究蓬勃发展的背景下,由PowerZooJax团队于近年构建并发布。该数据集旨在弥合电力时序预测与强化学习研究之间数据孤岛的鸿沟,其核心研究问题是如何为电力系统运行优化(如最优潮流、负荷预测)提供真实、多样且标准化的基准测试平台。数据集整合了来自英国、澳大利亚电力监管机构(如Elexon、AEMO、NESO)及全球科技巨头(阿里巴巴、微软、谷歌)数据中心长达数年的运行轨迹,覆盖从5节点到2383节点的输电与配电网典型拓扑。通过统一的清单文件映射各异的数据源至规范模式,PowerZooDataset显著降低了跨域研究的预处理成本,为智能电网与数据中心能效管理领域的研究者提供了不可或缺的公共资源。
当前挑战
该数据集所解决的领域核心挑战在于电力系统与数据中心研究长期面临的数据碎片化与标准化缺失问题——不同来源的电负荷、电价、发电构成及服务器利用率数据格式各异,且缺乏与电网物理拓扑的关联,致使研究成果难以复现与对比。构建过程中面临的挑战尤为突出:首先,需从多个权威机构以不同时间分辨率(5分钟至30分钟不等)发布的原始数据中,通过精心设计的清单文件实现时间戳对齐与列名规范映射,如处理GB NESO数据中结算时期与日期联合索引的UTC重建;其次,数据中心轨迹的时间模式被标注为周期性而非绝对日历,需锚定特定epoch以支持强化学习中的轮次采样;最后,Ausgrid等数据集存在上游发布的插值处理,其插值方法未公开,要求用户在应用中谨慎甄别原始与修正值,确保下游任务的物理一致性。
常用场景
经典使用场景
PowerZooDataset作为电力系统与数据中心交叉领域的综合基准数据集,其经典使用场景主要体现在强化学习和时序预测的研究中。该数据集整合了来自英国和澳大利亚电力监管机构发布的真实负荷、发电类型、日前预测及市场电价数据,同时涵盖了阿里巴巴、微软Azure和谷歌等云服务提供商的数据中心资源利用率轨迹。研究者可通过数据集提供的统一规范模式,将不同来源的时序数据无缝集成至强化学习实验环境中,从而开展电网经济调度、数据中心功率调控以及需求响应策略的模拟训练。电力潮流网络拓扑的Python类定义进一步支撑了最优潮流与分布式控制的标准化基准测试。
解决学术问题
该数据集精准回应了电力系统研究中长期存在的两大核心难题:一是真实世界运行数据获取门槛高且格式各异,导致强化学习与预测模型的可复现性不足;二是电网与数据中心跨域协同优化缺乏统一的基准测试平台。PowerZooDataset通过提供源自官方监管机构的负荷与发电时间序列、涵盖从5节点到2383节点的输配电网络拓扑案例、以及将原始列映射至规范模式的JSON清单,系统性地破解了数据碎片化与实验不可比的困境。这一规范化的数据集构建范式,不仅推动了负荷预测、最优潮流和需求响应等经典学术议题的实证研究,更促成了强化学习算法在电力与计算资源协同调度中的严谨评估,为智能电网领域的方法论进步奠定了坚实的数据基础。
衍生相关工作
PowerZooDataset的发布催生了一系列具有深远影响的衍生研究工作,其核心围绕强化学习与最优潮流算法的标准化评估展开。基于该数据集,研究者构建了电力系统专用强化学习基准测试框架PowerZoo与PowerZooJax,这些框架为电网调度与控制领域的深度强化学习模型提供了统一的环境接口和性能对比协议。在时序预测方向,衍生工作聚焦于多区域负荷与可再生能源发电的可解释性预测模型,利用数据集中的日前预报与实际值对比样本提升预测鲁棒性。数据中心能效优化方面,衍生研究探索了将电网电价信号引入数据中心任务调度的协同框架,推动了算力与电力系统互联的跨学科融合。这些经典工作的涌现,标志着该数据集已成为连接电力工程、机器学习与运筹优化的重要社区基础设施。
以上内容由遇见数据集搜集并总结生成


