pdp4k
收藏Hugging Face2026-04-28 更新2026-04-29 收录
下载链接:
https://huggingface.co/datasets/Julian2002/pdp4k
下载链接
链接失效反馈官方服务:
资源简介:
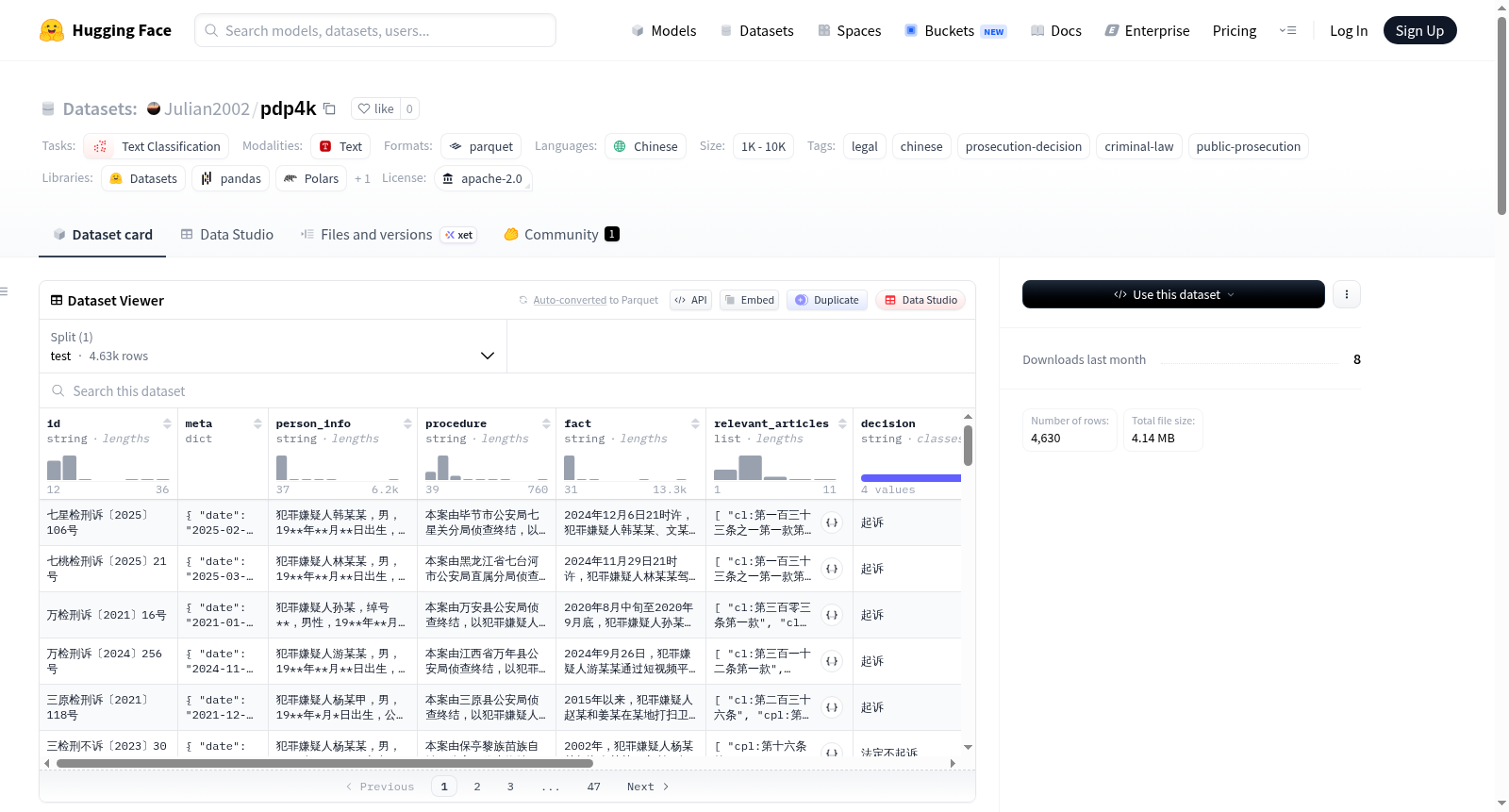
PDP-4K 是一个中文检察机关公诉决定预测数据集,包含 4,630 条结构化检察文书样本。该数据集旨在支持法律自然语言处理研究,特别是公诉决定的预测任务。数据集中的每个样本包含犯罪嫌疑人信息、案件程序、案件事实、相关法条以及公诉决定类型。公诉决定分为四类:起诉、相对不起诉、法定不起诉和存疑不起诉。数据集覆盖了31个省级地区的检察文书,时间范围为2014年至2026年。此外,数据集还提供了每条文书的元数据(日期和省份)、原始审查意见和决定文本以及来源网页URL。数据集当前仅提供测试集,适用于零样本学习、提示工程、上下文学习和模型评测实验。
创建时间:
2026-04-26
原始信息汇总
数据集概述:PDP-4K(公诉决定预测数据集)
基本信息
- 语言:中文
- 许可证:Apache-2.0
- 任务类别:文本分类(法律领域)
- 标签:法律、中文、公诉决定、刑法、公诉
- 数据规模:1,000 < n < 10,000
数据集规模与分割
- 总样本数:4,630 条(当前仅提供 test 分割)
- 数据大小:下载大小 4,133,482 字节,数据集大小 13,984,506 字节
任务描述
给定 犯罪嫌疑人信息、案件程序 和 案件事实,模型需预测:
- 适用法条(
relevant_articles):使用cl:(刑法)、cpl:(刑事诉讼法)、cpr:(其他相关法规)前缀标识法律来源。 - 公诉决定(
decision):四分类标签。
标签分布
| 分割 | 样本总数 | 起诉 | 相对不起诉 | 法定不起诉 | 存疑不起诉 |
|---|---|---|---|---|---|
| test | 4,630 | 4,008 | 480 | 41 | 101 |
数据来源与时间范围
- 来源覆盖:100% 样本包含
source_url字段。 - 文书日期范围:2014-01-24 至 2026-03-03。
- 覆盖地区:31 个省级行政区。
- 法条标注总数:14,764 条(其中
cl:7,841 条、cpl:6,912 条、cpr:11 条)。
样本量最多的省级地区(前10名)
| 地区 | 样本数 |
|---|---|
| 内蒙古自治区 | 1,359 |
| 山西省 | 592 |
| 云南省 | 548 |
| 广东省 | 340 |
| 陕西省 | 268 |
| 广西壮族自治区 | 208 |
| 天津市 | 123 |
| 北京市 | 119 |
| 贵州省 | 107 |
| 黑龙江省 | 106 |
字段说明
| 字段名 | 类型 | 说明 |
|---|---|---|
id |
string | 文书唯一标识 |
meta |
dict | 元数据,包含 date(日期)、province(省份) |
person_info |
string | 犯罪嫌疑人信息(已脱敏) |
procedure |
string | 案件程序信息 |
fact |
string | 案件事实 |
relevant_articles |
list[string] | 相关法条(带 cl: / cpl: / cpr: 前缀) |
decision |
string | 公诉决定类型(起诉、相对不起诉、法定不起诉、存疑不起诉) |
raw_reasoning_and_decision |
string | 原始审查意见和决定文本 |
source_url |
string | 文书来源网页 URL |
标签定义
- 起诉:犯罪事实清楚、证据确实充分,依法应当追究刑事责任。
- 相对不起诉:已构成犯罪,但犯罪情节轻微,依法不需要判处刑罚或免除刑罚。
- 法定不起诉:没有犯罪事实,或存在依法不追究刑事责任的情形。
- 存疑不起诉:经补充侦查后仍证据不足,不符合起诉条件。
注意事项
- 本数据集仅用于法律 NLP 研究与模型评测,不构成法律意见。
- 文本来自公开检察文书并经过结构化处理,使用时需注意个人信息保护和合规要求。
- 当前仅提供 test split,适合零样本、提示工程、上下文学习和模型评测实验。
搜集汇总
数据集介绍
构建方式
PDP-4K数据集源自中国检察机关公开的检察文书,经由系统性的结构化处理构建而成。研究者广泛采集了涵盖31个省级地区的起诉与不起诉决定文书,时间跨度从2014年至2026年。在此基础上,对每份文书进行了精细的字段抽取与标注,提取出犯罪嫌疑人信息、案件程序、案件事实、相关法条以及最终的公诉决定等关键要素。其中,法条标注采用了带有前缀的标准化格式,以区分法律来源。当前版本作为测试集,包含4630条样本,类分布呈现长尾特征,起诉案件占据多数,而不起诉类型相对稀疏。
使用方法
在应用时,研究者应将犯罪嫌疑人信息、案件程序描述以及案件事实文本作为模型输入,驱使其生成对应的法条列表与公诉决定标签。鉴于当前版本仅包含测试分割,该数据集特别适合用于评估预训练语言模型在未见数据上的泛化能力,尤其适用于零样本或少样本学习范式的探索。实践操作中,可将`fact`字段作为主要输入,辅以`person_info`与`procedure`字段的上下文信息,构建多样化的提示模板。模型输出需与`relevant_articles`列表及`decision`标签进行比对,以衡量预测准确度,并依据四分类混淆矩阵深入分析不同类型公诉决定的推理表现。
背景与挑战
背景概述
PDP-4K(Prosecution Decision Prediction Dataset)是由中文法律自然语言处理研究团队于近年构建的专门数据集,旨在推动检察机关公诉决定预测任务的发展。该数据集收录了4,630条源自中国31个省级地区的结构化检察文书,时间跨度从2014年至2026年,覆盖起诉、相对不起诉、法定不起诉和存疑不起诉四类公诉决定。其核心研究问题在于利用犯罪嫌疑人信息、案件程序及事实,预测适用法条与最终公诉决定,为法律智能辅助决策提供数据基础。PDP-4K的发布填补了中文公诉决定预测领域标准评测数据的空白,对司法人工智能中的法律推理、文本分类和可解释性研究具有重要推动作用。
当前挑战
PDP-4K数据集所解决的领域问题在于公诉决定预测任务的法律复杂性,包括如何从多源信息中准确识别适用法条并区分四种决定类型,尤其是不起诉情形间的细微差异,这对模型的语义理解与法律知识整合能力构成严峻考验。构建过程中面临的挑战包括:从公开检察文书中提取结构化信息时需兼顾脱敏合规与数据完整性;数据集存在严重类别不平衡,起诉样本占比超86%,而不起诉类别样本稀缺,易导致模型预测偏差;此外,仅提供测试集的设计意在鼓励零样本与迁移学习方法,但这也对模型在缺乏训练数据条件下的泛化能力提出了更高要求。
常用场景
经典使用场景
在法律人工智能的蓬勃发展中,PDP-4K数据集为中文法律文本理解与推理提供了关键支撑。其经典使用场景聚焦于检察机关公诉决定预测任务,模型需综合犯罪嫌疑人信息、案件程序及事实,精准预测适用法条与四类公诉决定(起诉、相对不起诉、法定不起诉、存疑不起诉)。该场景融合了信息抽取、多标签分类与法律推理,成为评测模型在法律语境下对复杂叙事理解、实体关系建模及规范适用能力的标杆任务。
解决学术问题
PDP-4K直面法律自然语言处理中的核心学术挑战:如何从非结构化的案件叙事中自动化推断公诉机关的决策逻辑。传统依赖人工规则或浅层特征的方法难以捕捉法条与事实间的微妙关联。该数据集通过结构化标注3,146条法条关联及明确决策标签,推动了多任务学习、注意力机制与法律知识注入等研究方向,显著提升了模型在证据不足、情节轻微等边缘案例上的判别鲁棒性,为构建可解释、可信赖的法律辅助裁判系统奠定了数据基础。
实际应用
在司法实务中,PDP-4K所孵化的技术直接赋能检察机关智慧辅助办案系统。实际应用涵盖:自动审查起诉阶段的文书预生成,快速匹配相关法条并提示证据审查要点;对存疑不起诉等高风险案例进行风险预警,辅助检察官决策一致性校验;以及跨省案件质量研判,通过统一模型评估不同地区起诉标准差异。该数据集已成为法律科技公司开发“案件繁简分流”与“文书智能生成”模块的核心训练资源,有效缓解基层检务人员工作负荷。
数据集最近研究
最新研究方向
随着法律人工智能在司法场景中的纵深发展,PDP-4K数据集聚焦于中国检察机关公诉决定预测这一前沿任务,尤其在少样本和零样本学习范式下展现出独特价值。该数据集覆盖2014至2026年间31个省级地区的结构化检察文书,精细化标注了起诉、相对不起诉、法定不起诉及存疑不起诉四类决定,并关联法律条文,为构建可解释、跨地域的智能公诉辅助系统提供了高质量基准。当前研究热点集中于利用大语言模型进行法条感知的推理与决策预测,探索如何在复杂事实与程序信息中捕捉司法裁量的潜在逻辑,同时应对文书样本类别高度不平衡的挑战。PDP-4K的发布不仅推动了司法NLP评测从粗粒度分类向细粒度、多标签预测演进,更助力中国智慧检务建设中“公平正义可计算”的伦理设计与实证验证。
以上内容由遇见数据集搜集并总结生成


