TrainingDataPro/ocr-receipts-text-detection
收藏Hugging Face2024-04-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TrainingDataPro/ocr-receipts-text-detection
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': receipt
'1': shop
'2': item
'3': date_time
'4': total
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 55510934
num_examples: 20
download_size: 54557192
dataset_size: 55510934
---
# OCR Receipts from Grocery Stores Text Detection - retail dataset
The Grocery Store Receipts Dataset is a collection of photos captured from various **grocery store receipts**. This dataset is specifically designed for tasks related to **Optical Character Recognition (OCR)** and is useful for retail.
# 💴 For Commercial Usage: To discuss your requirements, learn about the price and buy the dataset, leave a request on **[TrainingData](https://trainingdata.pro/datasets/ocr-receipts-text-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection)** to buy the dataset
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: **item, store, date_time and total**.

# Dataset structure
- **images** - contains of original images of receipts
- **boxes** - includes bounding box labeling for the original images
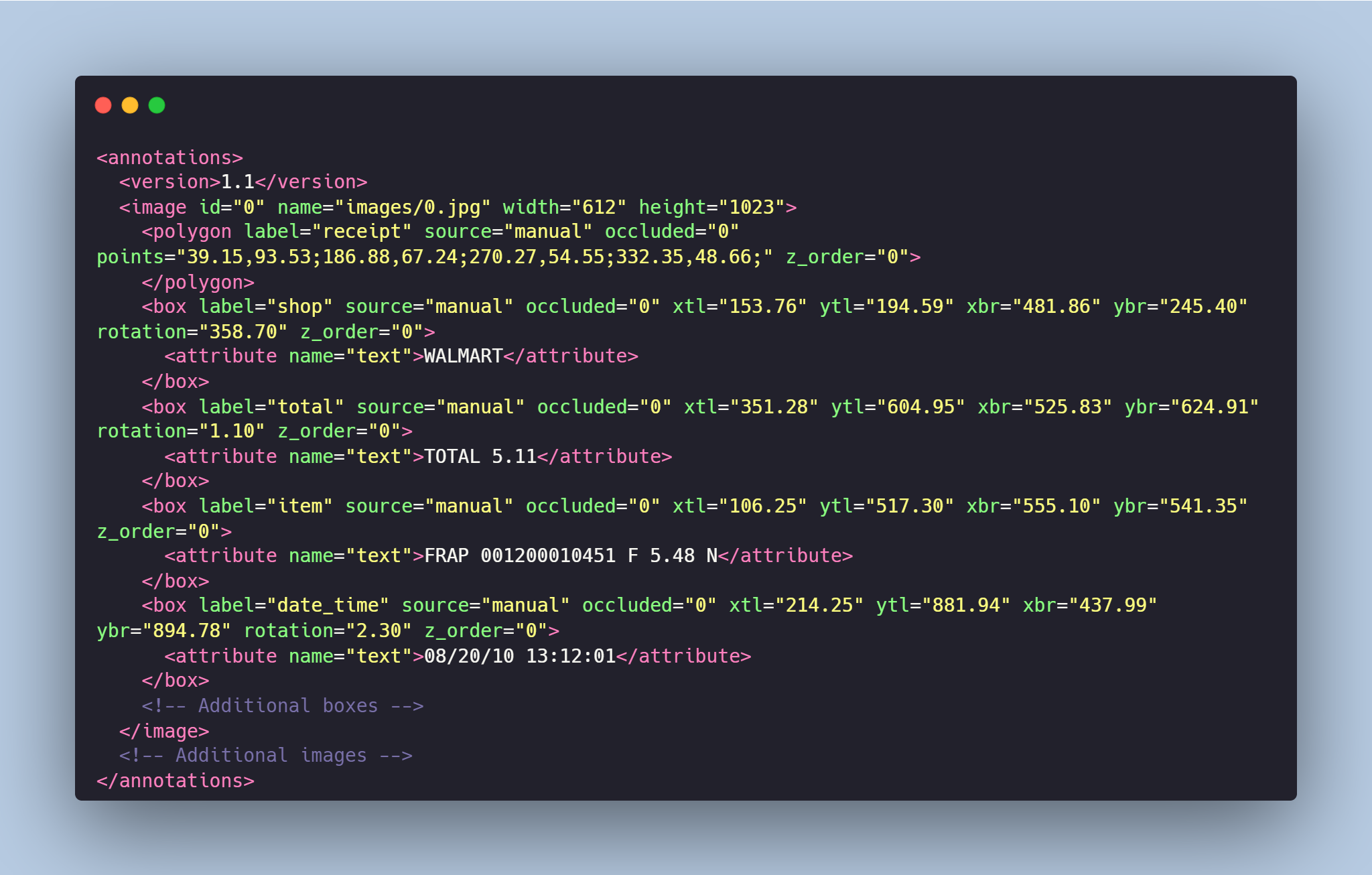
- **annotations.xml** - contains coordinates of the bounding boxes and detected text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
### Classes:
- **store** - name of the grocery store
- **item** - item in the receipt
- **date_time** - date and time of the receipt
- **total** - total price of the receipt
# Text Detection in the Receipts might be made in accordance with your requirements.
# 💴 Buy the Dataset: This is just an example of the data. Leave a request on **[https://trainingdata.pro/datasets](https://trainingdata.pro/datasets/ocr-receipts-text-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection)** to discuss your requirements, learn about the price and buy the dataset
## **[TrainingData](https://trainingdata.pro/datasets/ocr-receipts-text-detection?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection)** provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
*keywords: receipts reading, retail dataset, consumer goods dataset, grocery store dataset, supermarket dataset, deep learning, retail store management, pre-labeled dataset, annotations, text detection, text recognition, optical character recognition, document text recognition, detecting text-lines, object detection, scanned documents, deep-text-recognition, text area detection, text extraction, images dataset, image-to-text, object detection*
提供机构:
TrainingDataPro
原始信息汇总
数据集概述
数据集信息
- 语言: 英语
- 许可证: CC BY-NC-ND 4.0
- 任务类别:
- 图像到文本
- 目标检测
- 标签:
- 代码
- 金融
数据集结构
- 特征:
id: 数据类型为int32name: 数据类型为stringimage: 数据类型为imagemask: 数据类型为imagewidth: 数据类型为uint16height: 数据类型为uint16shapes: 序列类型,包含以下子特征:label: 数据类型为class_label,包含以下类别:0: receipt1: shop2: item3: date_time4: total
type: 数据类型为stringpoints: 序列类型,包含float32类型的序列rotation: 数据类型为float32occluded: 数据类型为uint8attributes: 序列类型,包含以下子特征:name: 数据类型为stringtext: 数据类型为string
数据分割
- 训练集:
- 字节数: 55510934
- 样本数: 20
数据大小
- 下载大小: 54557192
- 数据集大小: 55510934
数据集描述
- 名称: OCR Receipts from Grocery Stores Text Detection - retail dataset
- 描述: 该数据集包含从不同杂货店收据拍摄的照片,专门设计用于光学字符识别(OCR)任务,适用于零售领域。
- 图像: 包含原始收据图像
- 边界框: 包含原始图像的边界框标注
- 标注文件:
annotations.xml包含边界框的坐标和检测到的文本
数据格式
- 每个图像文件夹中的图像都伴随一个
annotations.xml文件,指示边界框的坐标和检测到的文本。 - 类别:
store: 杂货店名称item: 收据中的商品date_time: 收据的日期和时间total: 收据的总价
搜集汇总
数据集介绍

以上内容由遇见数据集搜集并总结生成


