rootsautomation/RICO-WidgetCaptioning
收藏Hugging Face2024-04-16 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/rootsautomation/RICO-WidgetCaptioning
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc-by-4.0
size_categories:
- 10K<n<100K
task_categories:
- image-to-text
- text-generation
pretty_name: Widget Captioning
tags:
- screens
- mobile
- phones
dataset_info:
features:
- name: screenId
dtype: int64
- name: captions
sequence: string
- name: view_hierarchy
dtype: string
- name: bbox
sequence: float64
- name: file_name
dtype: string
- name: file_name_semantic
dtype: string
- name: semantic_annotations
dtype: string
- name: app_package_name
dtype: string
- name: play_store_name
dtype: string
- name: category
dtype: string
- name: average_rating
dtype: float64
- name: number_of_ratings
dtype: string
- name: number_of_downloads
dtype: string
- name: file_name_icon
dtype: string
- name: image
dtype: image
- name: image_icon
dtype: image
- name: image_semantic
dtype: image
splits:
- name: train
num_bytes: 10278117710.220001
num_examples: 41221
- name: val
num_bytes: 880438420.595
num_examples: 3483
- name: test
num_bytes: 987366583.47
num_examples: 3621
download_size: 2945501992
dataset_size: 12145922714.285
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
---
# Dataset Card for RICO Widget Captioning
Widget Captioning is a dataset for providing captions for UI elements on mobile screens.
It uses the RICO image database.
## Dataset Details
### Dataset Description
- **Curated by:** Google Research, UIUC, Northwestern, Georgia Tech
- **Funded by:** Google Research
- **Shared by:** Google Research
- **Language(s) (NLP):** English
- **License:** CC-BY-4.0
### Dataset Sources
- **Repository:**
- [google-research-datasets/widget-caption](https://github.com/google-research-datasets/widget-caption)
- [RICO raw downloads](http://www.interactionmining.org/rico.html)
- **Paper:**
- [Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements](https://arxiv.org/abs/2010.04295)
- [Rico: A Mobile App Dataset for Building Data-Driven Design Applications](https://dl.acm.org/doi/10.1145/3126594.3126651)
## Uses
This dataset is for developing multimodal automations for mobile screens.
### Direct Use
- Enhancing screen readers
- Screen indexing
- Conversational mobile applications
- Q&A on screens
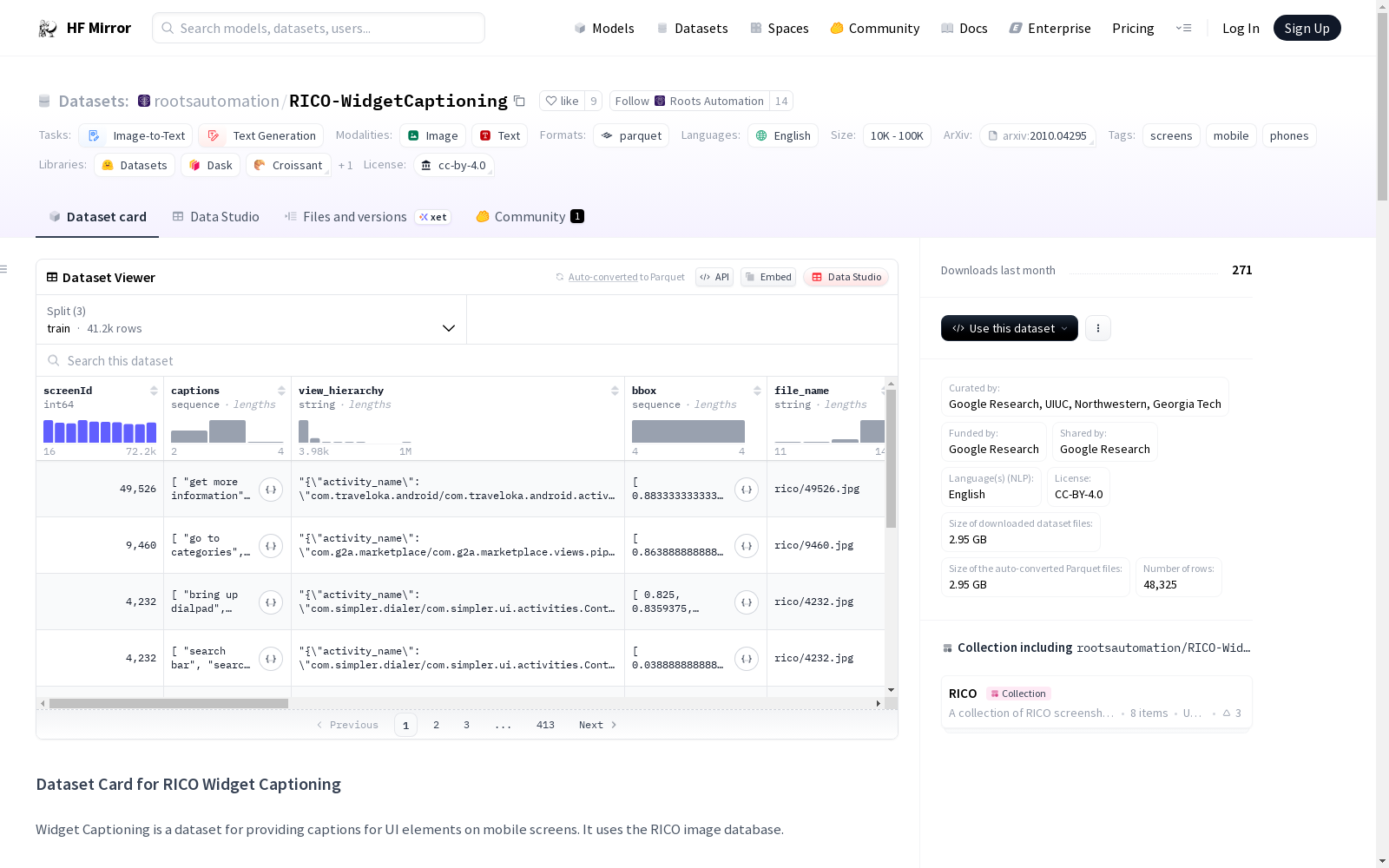
## Dataset Structure
- `screenId`: Unique RICO screen ID
- `image`: RICO screenshot
- `image_icon`: Google Play Store icon for the app
- `image_semantic`: Semantic RICO screenshot; details are abstracted away to main visual UI elements
- `file_name`: Image local filename
- `file_name_icon`: Icon image local filename
- `file_name_semantic`: Screenshot Image as a semantic annotated image local filename
- `captions`: A list of string captions
- `bbox`: The bounding box for the widget being captioned, relatively scaled with the image size so that coordinates are in [0, 1]
- `app_package_name`: Android package name
- `play_store_name`: Google Play Store name
- `category`: Type of category of the app
- `number_of_downloads`: Number of downloads of the app (as a coarse range string)
- `number_of_ratings`: Number of ratings of the app on the Google Play store (as of collection)
- `average_rating`: Average rating of the app on the Google Play Store (as of collection)
- `semantic_annotations`: Reduced view hierarchy, to the semantically-relevant portions of the full view hierarchy. It corresponds to what is visualized in `image_semantic` and has a lot of details about what's on screen. It is stored as a JSON object string.
## Dataset Creation
### Curation Rationale
- RICO rationale: Create a broad dataset that can be used for UI automation. An explicit goal was to develop automation software that can validate an app's design and assess whether it achieves its stated goal.
- Widget Captioning rationale: Create a dataset that helps machines reason about UI elements on screens
### Source Data
- RICO: Mobile app screenshots, collected on Android devices.
- Widget Captioning: Human annotated concise captions for widgets on screen
#### Data Collection and Processing
- RICO: Human and automated collection of Android screens. ~9.8k free apps from the Google Play Store.
- Widget Captioning: Takes the subset of screens used in RICO, eliminates screens with missing or inaccurate view hierarchies.
#### Who are the source data producers?
- RICO: 13 human workers (10 from the US, 3 from the Philippines) through UpWork.
- Widget Captioning: 5.4k annotators through Amazon Mechanical Turk
## Citation
### RICO
**BibTeX:**
```misc
@inproceedings{deka2017rico,
title={Rico: A mobile app dataset for building data-driven design applications},
author={Deka, Biplab and Huang, Zifeng and Franzen, Chad and Hibschman, Joshua and Afergan, Daniel and Li, Yang and Nichols, Jeffrey and Kumar, Ranjitha},
booktitle={Proceedings of the 30th annual ACM symposium on user interface software and technology},
pages={845--854},
year={2017}
}
```
**APA:**
Deka, B., Huang, Z., Franzen, C., Hibschman, J., Afergan, D., Li, Y., ... & Kumar, R. (2017, October). Rico: A mobile app dataset for building data-driven design applications. In Proceedings of the 30th annual ACM symposium on user interface software and technology (pp. 845-854).
### Widget Captioning
**BibTeX:**
```misc
@inproceedings{li2020widget,
title={Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements},
author={Li, Yang and Li, Gang and He, Luheng and Zheng, Jingjie and Li, Hong and Guan, Zhiwei},
booktitle={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
pages={5495--5510},
year={2020}
}
```
**APA:**
Li, Y., Li, G., He, L., Zheng, J., Li, H., & Guan, Z. (2020, November). Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 5495-5510).
## Dataset Card Authors
Hunter Heidenreich, Roots Automation
## Dataset Card Contact
hunter "DOT" heidenreich "AT" rootsautomation "DOT" com
---
language:
- 英语
license: cc-by-4.0
size_categories:
- 10000 < 样本数量 < 100000
task_categories:
- 图像到文本
- 文本生成
pretty_name: 组件字幕(Widget Captioning)
tags:
- 屏幕
- 移动端
- 手机
dataset_info:
features:
- name: screenId
dtype: int64
- name: captions
sequence: 字符串
- name: view_hierarchy
dtype: 字符串
- name: bbox
sequence: float64
- name: file_name
dtype: 字符串
- name: file_name_semantic
dtype: 字符串
- name: semantic_annotations
dtype: 字符串
- name: app_package_name
dtype: 字符串
- name: play_store_name
dtype: 字符串
- name: category
dtype: 字符串
- name: average_rating
dtype: float64
- name: number_of_ratings
dtype: 字符串
- name: number_of_downloads
dtype: 字符串
- name: file_name_icon
dtype: 字符串
- name: image
dtype: 图像
- name: image_icon
dtype: 图像
- name: image_semantic
dtype: 图像
splits:
- name: 训练集(train)
num_bytes: 10278117710.220001
num_examples: 41221
- name: 验证集(val)
num_bytes: 880438420.595
num_examples: 3483
- name: 测试集(test)
num_bytes: 987366583.47
num_examples: 3621
download_size: 2945501992 字节
dataset_size: 12145922714.285 字节
configs:
- config_name: 默认(default)
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
---
# RICO 组件字幕数据集卡片(RICO Widget Captioning)
组件字幕(Widget Captioning)是一款用于为移动屏幕上的用户界面(UI)元素生成字幕的数据集,其基于RICO图像数据库构建。
## 数据集详情
### 数据集描述
- "整理方":谷歌研究院、伊利诺伊大学厄巴纳-香槟分校(UIUC)、西北大学、佐治亚理工学院
- "资助方":谷歌研究院
- "共享方":谷歌研究院
- "自然语言处理所用语言":英语
- "许可协议":CC-BY-4.0
### 数据集来源
- "代码仓库":
- [google-research-datasets/widget-caption](https://github.com/google-research-datasets/widget-caption)
- [RICO 原始数据集下载页](http://www.interactionmining.org/rico.html)
- "相关论文":
- [《组件字幕:为移动用户界面元素生成自然语言描述》(Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements)](https://arxiv.org/abs/2010.04295)
- [《RICO:一款用于构建数据驱动设计应用的移动应用数据集》(Rico: A Mobile App Dataset for Building Data-Driven Design Applications)](https://dl.acm.org/doi/10.1145/3126594.3126651)
## 使用场景
本数据集用于开发移动屏幕的多模态自动化工具。
### 直接应用场景
- 增强屏幕阅读器功能
- 屏幕索引构建
- 对话式移动应用开发
- 屏幕相关问答系统
## 数据集结构
- `screenId`:唯一的RICO屏幕标识符
- `image`:RICO屏幕截图
- `image_icon`:对应应用的谷歌应用商店图标
- `image_semantic`:语义化RICO屏幕截图,已将细节抽象为主要视觉用户界面(UI)元素
- `file_name`:图像本地文件名
- `file_name_icon`:图标图像本地文件名
- `file_name_semantic`:语义标注截图的本地文件名
- `captions`:字符串字幕列表
- `bbox`:待标注组件的边界框,相对于图像尺寸进行缩放,坐标范围为[0, 1]
- `app_package_name`:Android应用包名
- `play_store_name`:谷歌应用商店应用名称
- `category`:应用所属类别
- `number_of_downloads`:应用下载量(以粗略范围字符串形式存储)
- `number_of_ratings`:谷歌应用商店中该应用的评分数量(数据收集时的统计值)
- `average_rating`:谷歌应用商店中该应用的平均评分(数据收集时的统计值)
- `semantic_annotations`:简化后的视图层级,仅保留完整视图层级中与语义相关的部分,对应`image_semantic`中的可视化内容,包含屏幕上所有元素的详细信息,以JSON对象字符串形式存储。
## 数据集构建
### 构建初衷
- RICO数据集构建初衷:构建可用于用户界面自动化的大规模数据集,核心目标是开发能够验证应用设计并评估其是否达成既定目标的自动化软件。
- 组件字幕(Widget Captioning)数据集构建初衷:创建一款可帮助机器理解屏幕上用户界面(UI)元素的数据集。
### 源数据
- RICO:在Android设备上收集的移动应用屏幕截图
- 组件字幕(Widget Captioning):针对屏幕上的UI组件的人工标注简洁字幕
#### 数据收集与处理
- RICO:通过人工与自动化手段收集Android设备屏幕,涵盖谷歌应用商店中约9800款免费应用
- 组件字幕(Widget Captioning):从RICO数据集的屏幕样本中筛选,移除缺失或视图层级不准确的样本
#### 数据源生产者
- RICO:通过UpWork平台招募的13名标注人员(10名来自美国,3名来自菲律宾)
- 组件字幕(Widget Captioning):通过亚马逊众包平台(Amazon Mechanical Turk)招募的5400名标注人员
## 引用信息
### RICO 数据集
**BibTeX格式**:
misc
@inproceedings{deka2017rico,
title={Rico: A mobile app dataset for building data-driven design applications},
author={Deka, Biplab and Huang, Zifeng and Franzen, Chad and Hibschman, Joshua and Afergan, Daniel and Li, Yang and Nichols, Jeffrey and Kumar, Ranjitha},
booktitle={Proceedings of the 30th annual ACM symposium on user interface software and technology},
pages={845--854},
year={2017}
}
**APA格式**:
Deka, B., Huang, Z., Franzen, C., Hibschman, J., Afergan, D., Li, Y., ... & Kumar, R. (2017, 10月). RICO: 一款用于构建数据驱动设计应用的移动应用数据集. 见第30届ACM用户界面软件与技术年会论文集 (pp. 845-854).
### 组件字幕(Widget Captioning)数据集
**BibTeX格式**:
misc
@inproceedings{li2020widget,
title={Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements},
author={Li, Yang and Li, Gang and He, Luheng and Zheng, Jingjie and Li, Hong and Guan, Zhiwei},
booktitle={Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
pages={5495--5510},
year={2020}
}
**APA格式**:
Li, Y., Li, G., He, L., Zheng, J., Li, H., & Guan, Z. (2020, 11月). 组件字幕:为移动用户界面元素生成自然语言描述. 见2020年经验方法自然语言处理会议(EMNLP)论文集 (pp. 5495-5510).
## 数据集卡片作者
亨特·海登赖希(Hunter Heidenreich),Roots自动化公司
## 数据集卡片联系人
hunter "DOT" heidenreich "AT" rootsautomation "DOT" com
提供机构:
rootsautomation
原始信息汇总
数据集概述
基本信息
- 名称: Widget Captioning
- 语言: 英语
- 许可证: CC-BY-4.0
- 大小: 10K<n<100K
- 任务类别: image-to-text, text-generation
- 标签: screens, mobile, phones
数据集内容
- 特征:
screenId: 整数,唯一屏幕IDcaptions: 字符串序列,屏幕描述view_hierarchy: 字符串,视图层次结构bbox: 浮点数序列,边界框坐标file_name: 字符串,图像本地文件名file_name_semantic: 字符串,语义注释图像本地文件名semantic_annotations: 字符串,语义注释app_package_name: 字符串,Android包名play_store_name: 字符串,Google Play商店名称category: 字符串,应用类别average_rating: 浮点数,应用平均评分number_of_ratings: 字符串,应用评分数量number_of_downloads: 字符串,应用下载数量file_name_icon: 字符串,图标图像本地文件名image: 图像数据类型image_icon: 图像数据类型,应用图标image_semantic: 图像数据类型,语义截图
数据集结构
- 分割:
train: 41221个样本,大小10278117710.220001字节val: 3483个样本,大小880438420.595字节test: 3621个样本,大小987366583.47字节
- 下载大小: 2945501992字节
- 数据集大小: 12145922714.285字节
数据集创建
- 来源数据:
- RICO: 移动应用截图,Android设备收集
- Widget Captioning: 人工注释的屏幕小部件简短描述
- 数据收集和处理:
- RICO: 人工和自动收集,约9.8k免费应用
- Widget Captioning: 从RICO中筛选,移除缺失或不准确的视图层次结构的屏幕
- 数据生产者:
- RICO: 13名人工工作者
- Widget Captioning: 5.4k名注释者通过Amazon Mechanical Turk
搜集汇总
数据集介绍
构建方式
RICO-WidgetCaptioning数据集的构建,首先基于RICO图像数据库,该数据库包含了从Android设备上收集的移动应用程序屏幕截图。在构建过程中,数据集选取了约9.8k个来自Google Play商店的免费应用程序的屏幕截图。随后,通过人工和自动化方式收集这些屏幕截图,并对屏幕截图进行筛选,移除了缺失或不准确的视图层次结构的屏幕。在此基础上,进一步通过Amazon Mechanical Turk平台上的5.4k名标注者,为选取的屏幕上的小部件提供了简洁的文本描述,形成了最终的标注数据集。
特点
该数据集的特点在于其专注于为移动屏幕上的用户界面元素生成自然语言描述。它涵盖了各种类型的移动应用程序界面,并且提供了丰富的字段信息,如屏幕ID、应用包名、Play商店名称、类别、下载次数、评分数量和平均评分等。此外,每个屏幕截图都伴有相应的语义注释和边界框信息,这使得数据集不仅适用于图像到文本的任务,还适用于构建数据驱动的界面设计应用程序。
使用方法
使用该数据集时,研究者可以依据数据集提供的配置文件,分别获取训练集、验证集和测试集的数据。每个数据点都包含了屏幕截图、标注的文本描述、边界框信息以及应用的相关元数据。这些信息可以用于增强屏幕阅读器、屏幕索引、对话式移动应用程序以及屏幕内容的问答系统等研究和应用。
背景与挑战
背景概述
在移动应用界面自动化领域,RICO-WidgetCaptioning数据集的构建承载了重要的研究意义。该数据集由Google Research、UIUC、Northwestern和Georgia Tech共同策划,并于2017年推出,旨在通过提供移动屏幕上UI元素的 captions,推动界面自动化技术的发展。数据集以英语为主要语言,采用了Creative Commons BY 4.0许可。其核心研究问题聚焦于如何通过机器学习技术,实现对移动应用界面元素的自动描述,进而提升屏幕阅读器、屏幕索引、对话式移动应用以及屏幕问答等领域的性能。RICO-WidgetCaptioning数据集的推出,为相关领域的研究提供了宝贵的资源,极大地推动了移动应用界面自动化技术的发展。
当前挑战
尽管RICO-WidgetCaptioning数据集在研究领域具有重要影响力,但在构建和使用过程中也面临诸多挑战。首先,数据集的构建需要处理大量移动应用截图,并确保这些截图能够准确反映应用的UI元素,这对数据的收集和清洗提出了高要求。其次,数据集的质量高度依赖于人类标注的准确性,而标注过程中的主观性和不一致性为数据集的可靠性带来了挑战。此外,如何确保自动生成的captions既准确又具有自然语言的流畅性,是当前研究中的一个重要难题。这些挑战不仅要求研究者在算法上进行创新,还要求在数据收集和处理过程中采取更为严谨的方法。
常用场景
经典使用场景
在移动应用界面自动化的研究领域,RICO-WidgetCaptioning数据集的应用尤为关键。该数据集提供了对移动屏幕UI元素的自然语言描述,其经典使用场景包括增强屏幕阅读器、屏幕索引、构建对话式移动应用以及屏幕内容问答系统。
衍生相关工作
基于该数据集,研究者们已经开展了一系列相关工作,如构建数据驱动的界面设计应用、开发自动化的界面元素描述生成模型等,这些研究进一步推动了移动应用界面自动化技术的发展。
数据集最近研究
最新研究方向
在移动用户界面元素的自然语言描述生成领域,RICO-WidgetCaptioning数据集正推动着前沿研究的深入。该数据集通过提供移动应用界面元素的截图及对应的简洁注释,助力研究人员开发能够理解和描述界面元素的多模态自动化系统。近期研究集中于利用此数据集提升屏幕阅读器的性能、实现屏幕索引、构建对话式移动应用以及屏幕内容的问答系统。这些研究成果不仅增进了机器对用户界面设计的理解,也为视障用户提供了更为精准的辅助,具有重要的社会影响和实际应用价值。
以上内容由遇见数据集搜集并总结生成


