Mouwiya/Video-10M
收藏Hugging Face2024-05-24 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Mouwiya/Video-10M
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: videoid
dtype: int64
- name: contentUrl
dtype: string
- name: duration
dtype: string
- name: page_dir
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 2993227031
num_examples: 10727607
- name: validation
num_bytes: 1394310
num_examples: 5000
download_size: 1564635003
dataset_size: 2994621341
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
task_categories:
- text-to-video
- video-classification
size_categories:
- 10M<n<100M
---
# Dataset Name: Video-10M
## Description:
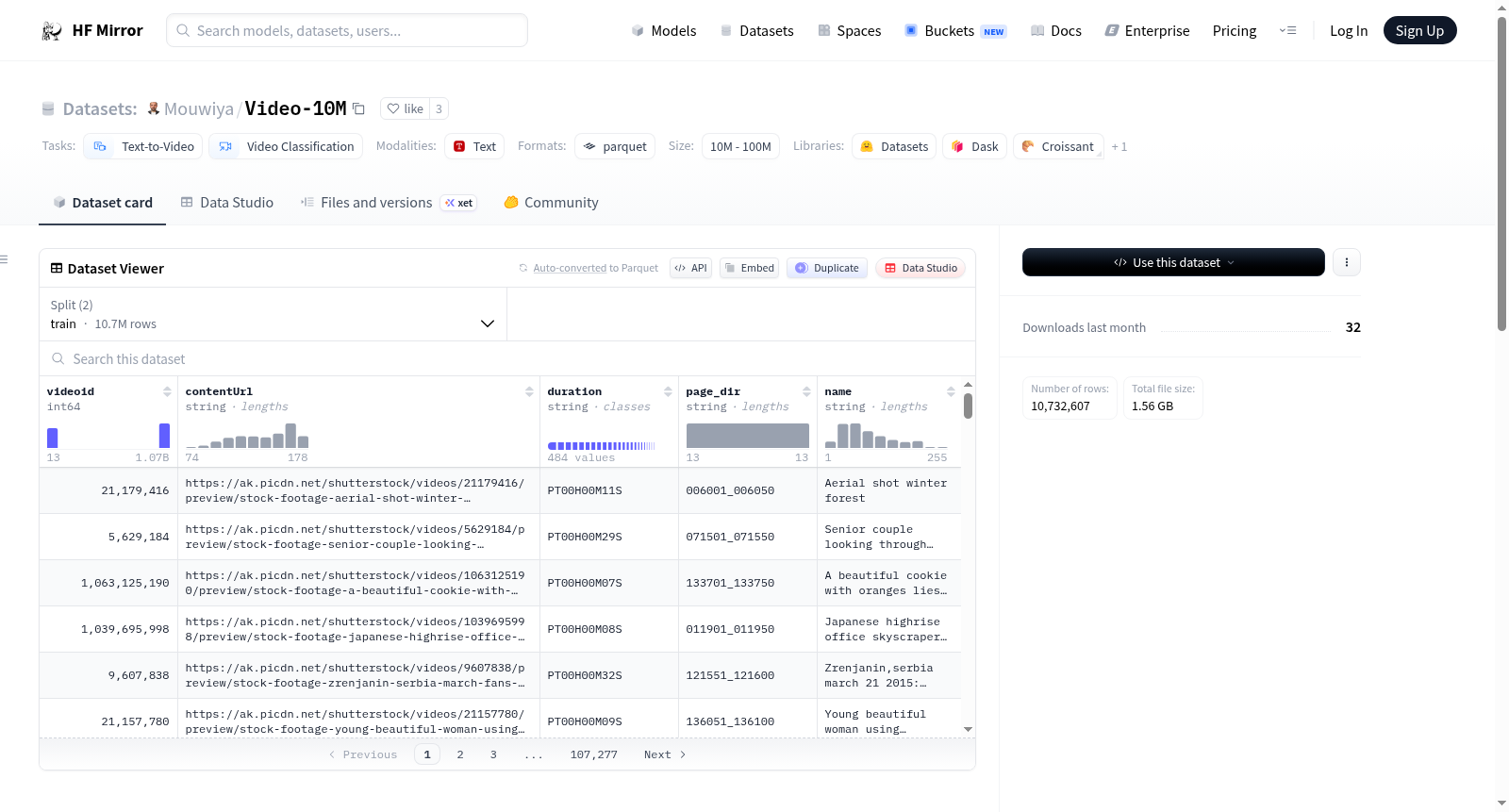
Video-10M is a dataset consisting of 10 million videos, each accompanied by metadata including video ID, content URL, duration, page directory, and name. The dataset covers a wide range of video content, from nature scenes and outdoor activities to culinary arts and urban landscapes. It provides a diverse collection of videos suitable for various video classification tasks.
## Split Information:
- Train Split: Contains 10,727,607 samples.
- Validation Split: Contains 5,000 samples.
## Features:
- videoid: Unique identifier for the video.
- contentUrl: URL or path to access the video content.
- duration: Duration of the video in hours, minutes, and seconds.
- page_dir: Directory or category associated with the video.
- name: Descriptive name or title for the video.
## Usage:
The dataset can be used for a wide range of video classification tasks, including but not limited to content categorization, scene recognition, activity recognition, and object detection. Researchers, developers, and practitioners can leverage this dataset to train and evaluate video classification models across different domains and applications.
## Download
```python
from datasets import load_dataset, Dataset
#Load the dataset
dataset = load_dataset("Mouwiya/Video-10M")
```
## Contact
**Mouwiya S. A. Al-Qaisieh**
mo3awiya@gmail.com
dataset_info:
features:
- name: videoid(视频ID)
dtype: int64
- name: contentUrl(内容URL)
dtype: string
- name: duration(时长)
dtype: string
- name: page_dir(页面目录)
dtype: string
- name: name(名称)
dtype: string
splits:
- name: train(训练集)
num_bytes: 2993227031
num_examples: 10727607
- name: validation(验证集)
num_bytes: 1394310
num_examples: 5000
download_size: 1564635003
dataset_size: 2994621341
configs:
- config_name: default(默认配置)
data_files:
- split: train(训练集)
path: data/train-*
- split: validation(验证集)
path: data/validation-*
task_categories:
- text-to-video(文本到视频)
- video-classification(视频分类)
size_categories:
- 10M<n<100M
---
# 数据集名称:Video-10M
## 数据集描述:
Video-10M是一个包含1000万条视频的数据集,每条视频均附带元数据,涵盖视频ID(videoid)、内容访问URL(contentUrl)、时长(duration)、页面目录(page_dir)以及视频名称(name)。该数据集覆盖了广泛的视频内容范畴,从自然景观、户外活动到烹饪艺术与城市风貌均有涉及,提供了多样化的视频集合,适用于各类视频分类任务。
## 划分信息:
- 训练集:包含10,727,607条样本。
- 验证集:包含5,000条样本。
## 特征说明:
- videoid:视频的唯一标识符。
- contentUrl:用于访问视频内容的URL或路径。
- duration:以时、分、秒格式标注的视频时长。
- page_dir:与视频关联的目录或分类信息。
- name:视频的描述性名称或标题。
## 使用场景:
该数据集可应用于各类视频分类任务,包括但不限于内容分类、场景识别、活动识别以及目标检测。研究人员、开发者与从业者可借助该数据集,在不同领域与应用场景中训练并评估视频分类模型。
## 下载方式
python
from datasets import load_dataset, Dataset
#加载数据集
dataset = load_dataset("Mouwiya/Video-10M")
## 联系方式
**Mouwiya S. A. Al-Qaisieh**
mo3awiya@gmail.com
提供机构:
Mouwiya
原始信息汇总
数据集概述:Video-10M
数据集描述
Video-10M 是一个包含1000万个视频的数据集,每个视频附带元数据,包括视频ID、内容URL、时长、页面目录和名称。该数据集涵盖了从自然景观、户外活动到烹饪艺术和城市景观等多种视频内容,适合用于各种视频分类任务。
数据集特征
- videoid: 视频的唯一标识符,数据类型为
int64。 - contentUrl: 访问视频内容的URL或路径,数据类型为
string。 - duration: 视频时长,以小时、分钟和秒表示,数据类型为
string。 - page_dir: 与视频关联的目录或类别,数据类型为
string。 - name: 视频的描述性名称或标题,数据类型为
string。
数据集分割信息
- 训练集: 包含10,727,607个样本,总大小为2993227031字节。
- 验证集: 包含5,000个样本,总大小为1394310字节。
数据集大小
- 下载大小: 1564635003字节
- 数据集总大小: 2994621341字节
任务类别
- 文本到视频
- 视频分类
大小类别
- 10M<n<100M
搜集汇总
数据集介绍
构建方式
在视频数据科学领域,大规模数据集的构建是推动模型泛化能力的关键。Video-10M数据集通过系统化采集网络视频资源,整合了超过一千万条视频样本,每条样本均包含视频ID、内容URL、时长、页面目录及名称等结构化元数据。构建过程中,数据源自多样化的公开视频平台,覆盖自然景观、户外活动、烹饪艺术与城市风貌等多个主题,确保了内容的广泛代表性。数据经过清洗与标注,划分为训练集与验证集,其中训练集包含10,727,607个样本,验证集则提供5,000个样本,以支持稳健的模型评估。
特点
该数据集的核心特点在于其规模宏大与多样性丰富,视频数量达到千万级别,为视频分类任务提供了充足的训练资源。元数据设计科学,涵盖视频标识、访问路径、时长及分类目录,便于研究者进行多维度分析。内容跨域广泛,从动态场景到静态对象均有涉及,增强了数据集在跨领域应用中的适应性。此外,数据集以标准格式存储,支持高效加载与处理,适用于文本到视频生成、视频分类等多种计算机视觉任务,为算法开发与性能验证奠定了坚实基础。
使用方法
在视频分析研究中,Video-10M数据集为模型训练与评估提供了便捷途径。用户可通过HuggingFace库直接加载数据集,使用load_dataset函数调用“Mouwiya/Video-10M”配置,自动获取训练与验证分割。数据以结构化特征呈现,包括videoid、contentUrl等字段,便于集成到现有机器学习流程中。该数据集适用于内容分类、场景识别、活动检测等任务,研究者可基于其丰富样本开发或优化视频分类模型,并通过验证集进行性能测试,推动视频理解技术的进步。
背景与挑战
背景概述
随着多媒体技术的飞速发展,视频数据已成为人工智能研究的重要资源。Video-10M数据集由Mouwiya S. A. Al-Qaisieh于近期构建,旨在为视频分类、场景识别及内容理解等任务提供大规模、多样化的训练素材。该数据集涵盖了自然景观、户外活动、烹饪艺术及城市风貌等多种视频内容,其核心研究问题聚焦于如何利用海量视频数据提升计算机视觉模型的泛化能力与鲁棒性。作为包含千万级别样本的资源,Video-10M为视频理解领域的算法创新奠定了坚实基础,推动了多模态学习与智能视频分析技术的进步。
当前挑战
在视频分类领域,模型需应对视频内容的高度动态性与时空复杂性,例如光照变化、视角转换及背景干扰等因素,这要求算法具备强大的特征提取与序列建模能力。构建Video-10M数据集时,研究人员面临数据采集与标注的挑战,包括从开放网络源中筛选高质量视频、确保内容多样性,以及处理视频时长、格式与元数据的一致性。此外,大规模视频存储与高效访问机制的设计也是关键难题,需平衡数据规模与计算资源之间的制约关系。
常用场景
经典使用场景
在计算机视觉领域,大规模视频数据集为模型训练提供了丰富的视觉素材。Video-10M以其千万级别的视频样本,成为视频分类任务中的经典资源。该数据集广泛应用于场景识别、活动分类及内容标注等研究,通过其多样化的视频内容,支持模型学习从自然景观到城市生活的广泛视觉模式,为视频理解技术的进步奠定了数据基础。
解决学术问题
视频理解研究常受限于数据规模与多样性不足,难以捕捉复杂时空特征。Video-10M通过提供海量且覆盖多领域的视频样本,有效缓解了数据稀缺性问题。它助力学术社区探索视频分类、动作识别及跨模态学习等核心课题,推动了深度学习模型在时序数据处理上的创新,为视频分析领域的理论发展与算法优化提供了关键支撑。
衍生相关工作
围绕Video-10M,研究社区衍生出多项经典工作,主要集中在视频分类架构的改进与跨任务迁移学习上。例如,基于该数据集的预训练模型被用于细粒度动作识别、视频字幕生成及异常检测等任务,促进了如时空卷积网络、注意力机制等先进方法在视频领域的适配与优化,进一步拓展了视频数据集在学术与工程中的影响力。
以上内容由遇见数据集搜集并总结生成


