中国主要木材名称国标数据库
收藏国家林业和草原科学数据中心2006-05-09 更新2024-03-06 收录
下载链接:
https://www.forestdata.cn/dataDetail.html?id=CSTR:17575.11.0120180509013.020001.V1
下载链接
链接失效反馈资源简介:
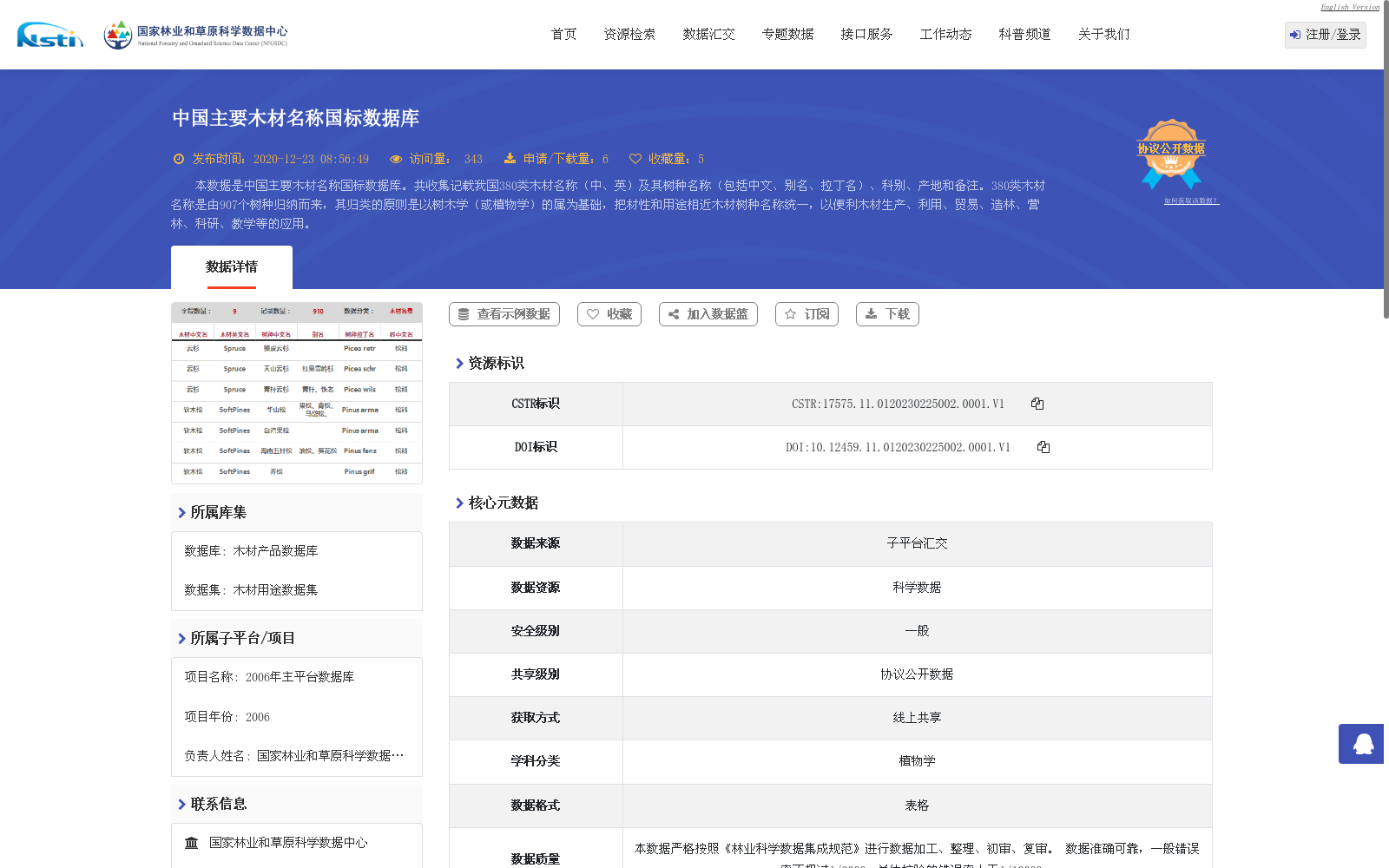
本数据是中国主要木材名称国标数据库。共收集记载我国380类木材名称(中、英)及其树种名称(包括中文、别名、拉丁名)、科别、产地和备注。380类木材名称是由907个树种归纳而来,其归类的原则是以树木学(或植物学)的属为基础,把材性和用途相近木材树种名称统一,以便利木材生产、利用、贸易、造林、营林、科研、教学等的应用。
This dataset is the national standard database for major Chinese timber names. It collects and documents 380 types of timber names (in both Chinese and English) of China, alongside the corresponding tree species information including Chinese names, aliases, Latin names, plant families, producing areas, and notes. The 380 timber name categories are summarized from 907 tree species. The classification is based on genera in dendrology (or botany), unifying the names of timber tree species with similar wood properties and uses, to facilitate applications in timber production, utilization, trade, afforestation, forest management, scientific research, teaching and other relevant fields.
提供机构:
国家林业和草原科学数据中心
创建时间:
2006-05-09
AI搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是中国主要木材名称国标数据库,收集了380类木材名称及其相关树种信息,包括中英文名称、别名、拉丁名、科别、产地等,由907个树种归纳而来,旨在统一材性和用途相近的木材名称,便于生产、贸易和科研应用。数据集基于2006年数据,以表格格式提供,数据质量高,错误率低,覆盖中国范围,适用于木材科学和工业领域。
以上内容由AI搜集并总结生成


