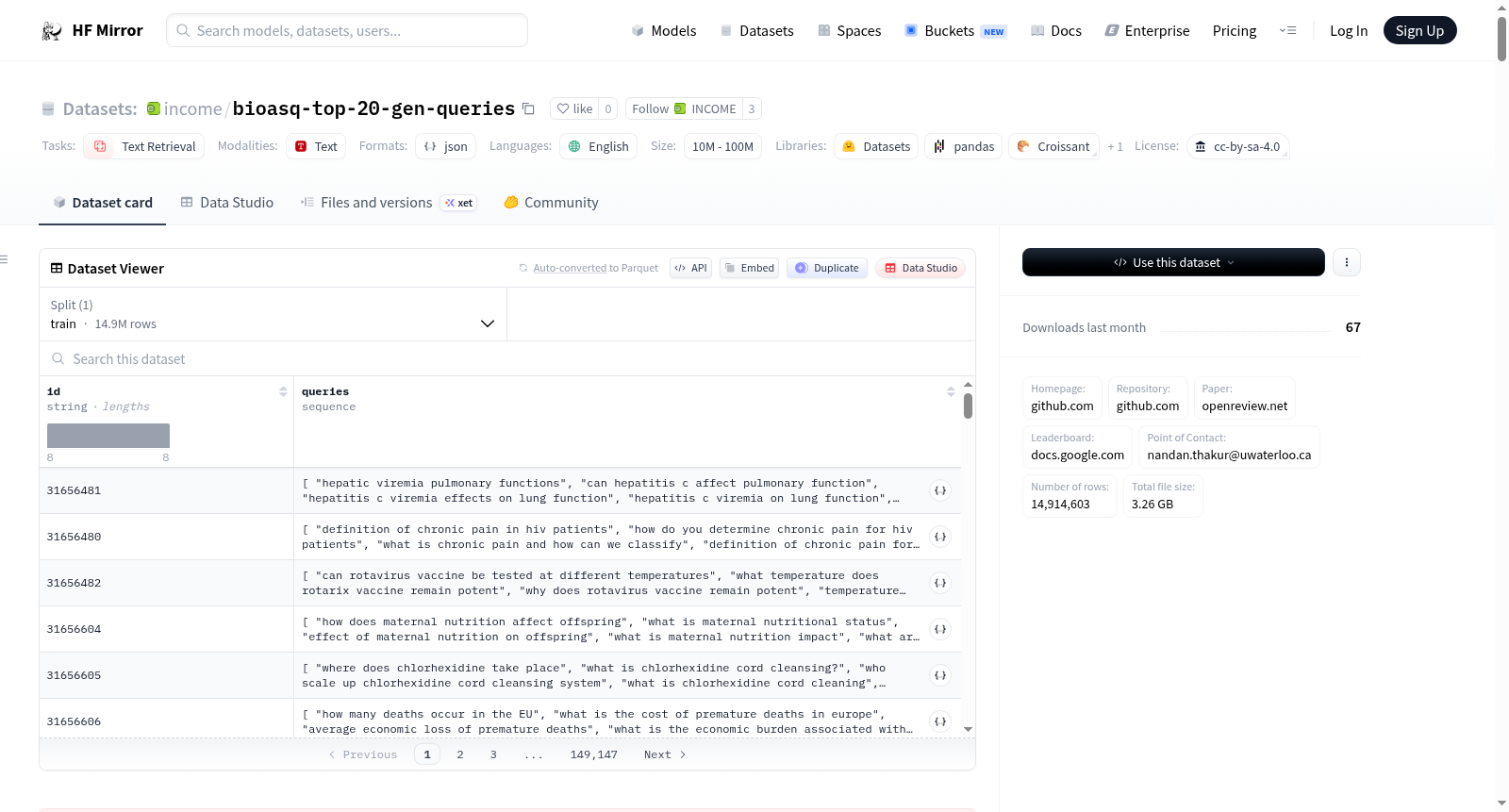
income/bioasq-top-20-gen-queries
收藏Hugging Face2023-01-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/income/bioasq-top-20-gen-queries
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
---
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.
提供机构:
income
原始信息汇总
数据集概述
数据集名称
- 名称: BEIR Benchmark
- 别名: BEIR
数据集基本信息
- 语言: 英语 (
en) - 许可证: CC-BY-SA-4.0
- 多语言性: 单语种
- 数据集大小:
- MSMARCO: 1M<n<10M
- TREC-COVID: 100k<n<1M
- NFCorpus: 1K<n<10K
- NQ: 1M<n<10M
- HotpotQA: 1M<n<10M
- FiQA: 10K<n<100K
- ArguAna: 1K<n<10K
- Touche-2020: 100K<n<1M
- CQADupstack: 100K<n<1M
- Quora: 100K<n<1M
- DBpedia: 1M<n<10M
- SciDocs: 10K<n<100K
- FEVER: 1M<n<10M
- Climate-FEVER: 1M<n<10M
- SciFact: 1K<n<10K
任务类别
- 任务: 文本检索
数据集结构
- 文件格式:
corpus:.jsonl(jsonlines)queries:.jsonl(jsonlines)qrels:.tsv(tab-separated)
- 数据字段:
- Corpus:
_id(string),title(string, optional),text(string) - Queries:
_id(string),text(string) - Qrels:
query-id(string),corpus-id(string),score(int32)
- Corpus:
数据集创建
-
引用信息:
@inproceedings{ thakur2021beir, title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models}, author={Nandan Thakur and Nils Reimers and Andreas R{"u}ckl{e} and Abhishek Srivastava and Iryna Gurevych}, booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)}, year={2021}, url={https://openreview.net/forum?id=wCu6T5xFjeJ} }
贡献者
- 贡献者: @Nthakur20
搜集汇总
数据集介绍
构建方式
在信息检索领域,合成查询的生成对于评估模型性能至关重要。该数据集基于BEIR基准中的NFCorpus语料库,采用DocT5query模型(BeIR/query-gen-msmarco-t5-base-v1)为每个文档生成20条合成查询。生成过程通过evaluate_anserini_docT5query_parallel.py脚本实现,确保了查询的多样性和相关性,为信息检索任务提供了丰富的测试数据。
特点
该数据集作为BEIR基准的一部分,专注于生物医学信息检索任务,其特点在于每个文档对应20条高质量合成查询,显著扩展了传统检索数据集的覆盖范围。查询内容紧密围绕文档主题,模拟真实用户意图,同时保持了语言的自然性和多样性。这种设计使得数据集能够有效评估模型在零样本或小样本场景下的泛化能力,为信息检索研究提供了标准化测试平台。
使用方法
该数据集适用于信息检索模型的训练与评估,用户可通过加载标准化的JSONL格式文件获取文档、查询及关联标注。典型应用包括:利用合成查询增强检索模型的训练数据,或在零样本设置下测试模型性能。数据集与BEIR基准兼容,可直接集成到现有评估流程中,通过计算NDCG、MAP等指标量化模型效果,为生物医学领域的检索研究提供可靠支持。
背景与挑战
背景概述
信息检索领域长期面临评估标准不统一的困境,BEIR基准应运而生,由德国达姆施塔特工业大学UKP实验室的Nandan Thakur等学者于2021年构建。该基准系统整合了涵盖事实核查、生物医学检索、问答系统等九大任务的十八个异构数据集,旨在为零样本检索模型提供跨领域的统一评估框架。其创新性在于通过标准化数据格式与评估协议,推动了检索系统从领域依赖向泛化能力的范式转变,成为衡量现代密集检索与稀疏检索模型性能的黄金标准。
当前挑战
BEIR基准致力于解决信息检索模型在零样本场景下的泛化能力评估难题,其核心挑战在于如何设计能够准确反映跨领域检索性能的异构任务集合。构建过程中面临多重挑战:首先,数据集成需要统一不同来源的标注规范与质量层次,例如生物医学文献的专业性与社交媒体文本的随意性存在显著差异;其次,合成查询生成依赖的DocT5query模型可能引入语义偏差,导致生成查询与真实用户意图存在分布差异;最后,评估体系需平衡检索精度与召回率在不同任务中的权重,避免因任务特性差异导致评估结果失真。
常用场景
经典使用场景
在信息检索领域,BEIR基准数据集为评估检索模型的零样本泛化能力提供了标准化的测试平台。该数据集整合了涵盖事实核查、问答系统、生物医学检索等九大任务的十八个异构数据集,其经典使用场景在于系统性地衡量不同检索算法在未见领域数据上的表现。研究者通过BEIR能够对比稀疏检索与稠密检索模型的优劣,探索跨领域知识迁移的有效性,从而推动检索技术向更通用、更鲁棒的方向演进。
解决学术问题
BEIR基准的构建旨在解决信息检索研究中模型评估单一化、领域适应性不足的学术难题。传统检索模型通常在特定数据集上表现优异,却难以泛化至其他领域,BEIR通过引入多任务、多领域的异构数据,为评估模型的零样本学习能力提供了严谨的框架。该数据集促进了检索模型从狭窄的任务专家向通用检索系统的转变,对推动领域自适应、跨任务迁移学习等前沿研究方向具有深远意义。
衍生相关工作
围绕BEIR基准,学术界衍生了一系列经典研究工作,例如稀疏检索模型SPLADE和稠密检索模型Contriever均在BEIR上进行了广泛评估与优化。这些工作不仅提升了检索性能,还深入探讨了模型架构、预训练策略与多任务学习的融合机制。同时,BEIR也催生了如ANCE、DPR等代表性稠密检索方法的改进版本,推动了检索模型在零样本设置下的创新,为后续研究提供了可复现的基线与丰富的比较基准。
以上内容由遇见数据集搜集并总结生成


