RoParQ
收藏arXiv2025-11-27 更新2025-11-28 收录
下载链接:
https://huggingface.co/datasets/m-joon-ixix/RoParQ
下载链接
链接失效反馈官方服务:
资源简介:
RoParQ是由首尔国立大学构建的专用于评估大语言模型对转述问题鲁棒性的基准数据集。该数据集包含10,273条高质量多选问答样本,源自MMLU、ARC、CommonsenseQA和MathQA四大权威数据集,通过Gemini和Claude等专有模型生成语义等价的转述变体。数据集构建过程采用严格的预处理流程,包括封闭式问答筛选、问题长度控制及基于法官模型的不一致置信度过滤机制。该数据集主要应用于增强大语言模型的语义不变性理解,旨在解决模型对表面语言模式过度依赖而导致的转述敏感性问题,推动可信人工智能的发展。
RoParQ is a benchmark dataset constructed by Seoul National University specifically for evaluating the robustness of Large Language Models (LLMs) against paraphrased questions. This dataset contains 10,273 high-quality multiple-choice question-answering samples derived from four authoritative datasets: MMLU, ARC, CommonsenseQA, and MathQA. Semantically equivalent paraphrased variants were generated using proprietary models such as Gemini and Claude. The dataset construction process adopts a strict preprocessing pipeline, including closed-ended QA screening, question length control, and an inconsistency confidence filtering mechanism based on judge models. This dataset is primarily applied to enhance the understanding of semantic invariance in LLMs, aiming to resolve the paraphrasing sensitivity issue caused by models' over-reliance on superficial linguistic patterns, and to promote the development of trustworthy artificial intelligence.
提供机构:
首尔国立大学
创建时间:
2025-11-27
原始信息汇总
RoParQ数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 问答
- 语言: 英语
数据集配置
1. 通用知识配置 (general-knowledge)
数据文件结构
- 训练集: general-knowledge/train-*
- 验证集: general-knowledge/validation-*
- 测试集: general-knowledge/test-*
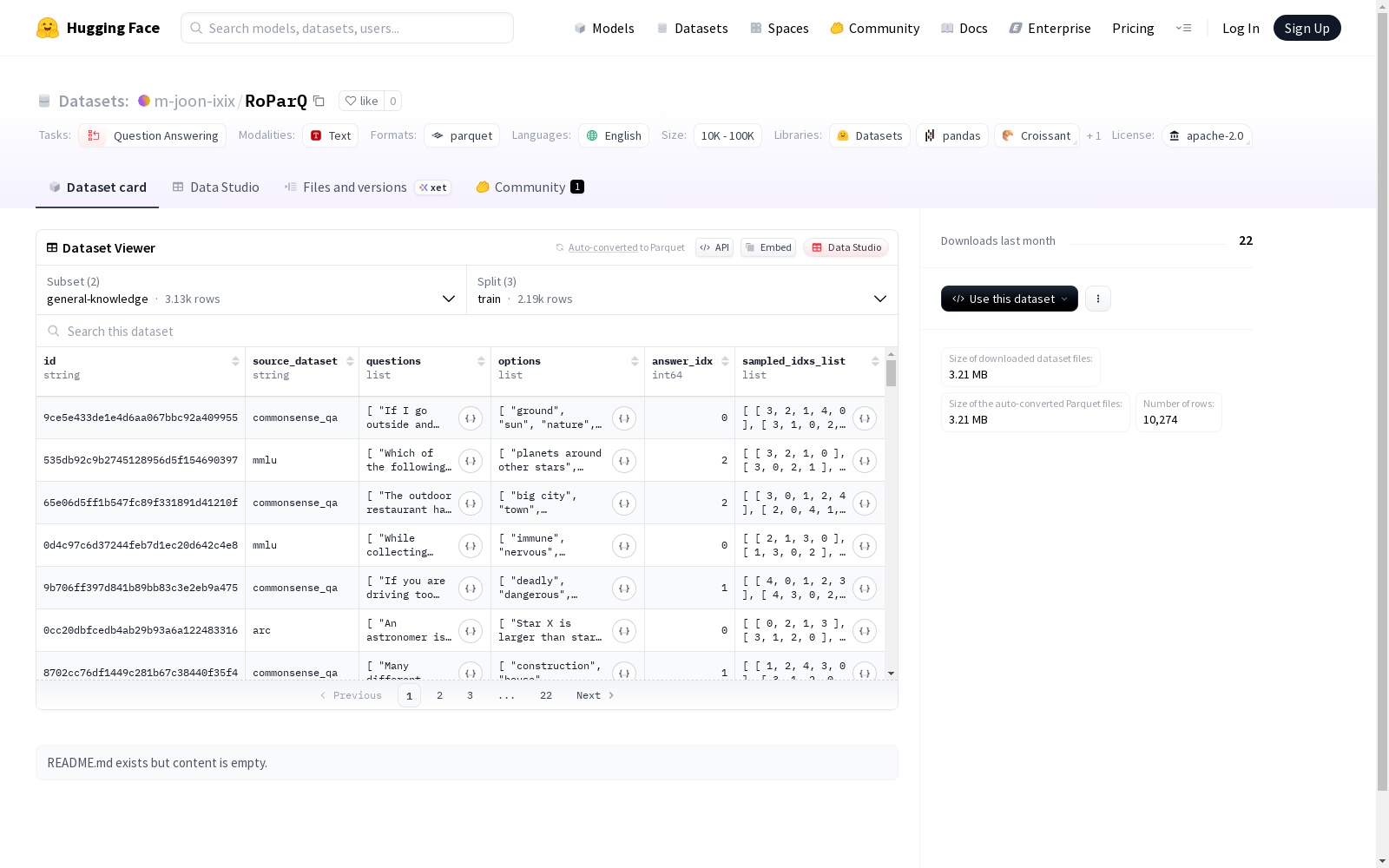
特征字段
- id: 字符串类型
- source_dataset: 字符串类型
- questions: 字符串列表
- options: 字符串列表
- answer_idx: 整型
- sampled_idxs_list: 整型列表的列表
数据统计
- 训练集: 2,194个样本,1,751,721字节
- 验证集: 470个样本,379,435字节
- 测试集: 470个样本,374,751字节
- 下载大小: 866,662字节
- 数据集总大小: 2,505,907字节
2. 数学推理配置 (math-reasoning)
数据文件结构
- 训练集: math-reasoning/train-*
- 验证集: math-reasoning/validation-*
- 测试集: math-reasoning/test-*
特征字段
- id: 字符串类型
- source_dataset: 字符串类型
- questions: 字符串列表
- options: 字符串列表
- answer_idx: 整型
- sampled_idxs_list: 整型列表的列表
数据统计
- 训练集: 4,998个样本,4,948,523字节
- 验证集: 1,071个样本,1,066,962字节
- 测试集: 1,071个样本,1,058,168字节
- 下载大小: 2,340,396字节
- 数据集总大小: 7,073,653字节
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,评估大语言模型对语义等效问题的鲁棒性至关重要。RoParQ数据集的构建基于四个标准多选问答基准(MMLU、ARC、CommonsenseQA和MathQA),通过专有模型生成高质量释义变体,并利用开源评判模型筛选出引发模型置信度不一致的样本,确保数据聚焦于当前模型的薄弱环节。
特点
该数据集的核心特征在于其精心设计的跨释义一致性评估框架,涵盖通用知识与数学推理两大子集,每个原始问题均配备两种语义等效的释义版本。通过引入XParaCon量化指标,能够精确衡量模型在应对不同表述时的稳定性,为研究语义不变性提供了可靠基准。
使用方法
研究人员可将RoParQ用于闭卷多选问答任务的鲁棒性评估,通过对比模型在原始问题与释义变体上的表现计算XParaCon分数。此外,数据集支持基于推理的监督微调方法,训练模型在生成答案前显式验证跨表述的语义一致性,从而提升对表面语言变化的适应能力。
背景与挑战
背景概述
RoParQ数据集由首尔国立大学的Minjoon Choi团队于2025年提出,旨在解决大型语言模型对语义等效但表述不同的问题产生不一致回答的核心研究问题。该数据集基于MMLU、ARC、CommonsenseQA和MathQA等经典基准,通过专有模型生成高质量复述问题,并利用评判模型筛选出引发模型置信度波动的样本,从而构建专门评估跨复述一致性的封闭式多项选择题基准。这一创新填补了自然语言处理领域对语义不变性评估的空白,为提升模型鲁棒性提供了关键数据支撑。
当前挑战
RoParQ数据集主要应对大型语言模型在复述问题一致性方面的挑战,即模型依赖表面语言模式而非深层语义理解导致的回答不稳定问题。构建过程中面临多重技术难题:需通过专有模型生成语义精确的复述变体,同时设计基于标准差的XParaCon指标量化模型稳定性;数据筛选需平衡不同领域特征,确保封闭式问答设置下排除上下文依赖干扰,并处理数学推理与常识问答的异质性问题。这些挑战共同推动了语义对齐技术的发展。
常用场景
经典使用场景
在自然语言处理领域,RoParQ数据集主要被用于评估大型语言模型对同义转述问题的鲁棒性。该数据集通过从标准基准中筛选出能引发模型不一致置信度的转述问题对,构建了一个专门测试跨转述一致性的评估框架。研究人员利用这一基准系统分析模型在保持语义不变的前提下,对多样化表述的适应能力,从而揭示模型是否真正掌握语义理解而非依赖表层语言模式。
衍生相关工作
RoParQ推动了多项语义鲁棒性研究的进展。基于其构建范式,后续研究开发了面向开放域问答的转述增强数据集。其提出的对齐方法启发了参数高效微调技术在语义一致性任务中的应用,衍生出融合对比学习的转述不变性训练框架。这些工作共同构成了语言模型鲁棒性研究的重要分支,持续推动着可靠人工智能系统的发展。
数据集最近研究
最新研究方向
在自然语言处理领域,RoParQ数据集的推出标志着对大型语言模型语义鲁棒性研究的重要突破。该数据集通过构建同义改写问题对,系统评估模型在封闭式多选题场景下的跨语义一致性表现,揭示了当前模型对表面语言模式的依赖问题。前沿研究聚焦于开发基于推理的监督微调方法,通过显式训练模型识别语义不变性,显著提升了轻量级模型的跨语义稳定性。这一进展不仅推动了语义理解评估范式的革新,更为构建可靠高效的语言模型提供了理论支撑与实践路径。
相关研究论文
- 1RoParQ: Paraphrase-Aware Alignment of Large Language Models Towards Robustness to Paraphrased Questions首尔国立大学 · 2025年
以上内容由遇见数据集搜集并总结生成


