reasoning-core/procedural-pretraining-pile
收藏Hugging Face2026-04-30 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/reasoning-core/procedural-pretraining-pile
下载链接
链接失效反馈官方服务:
资源简介:
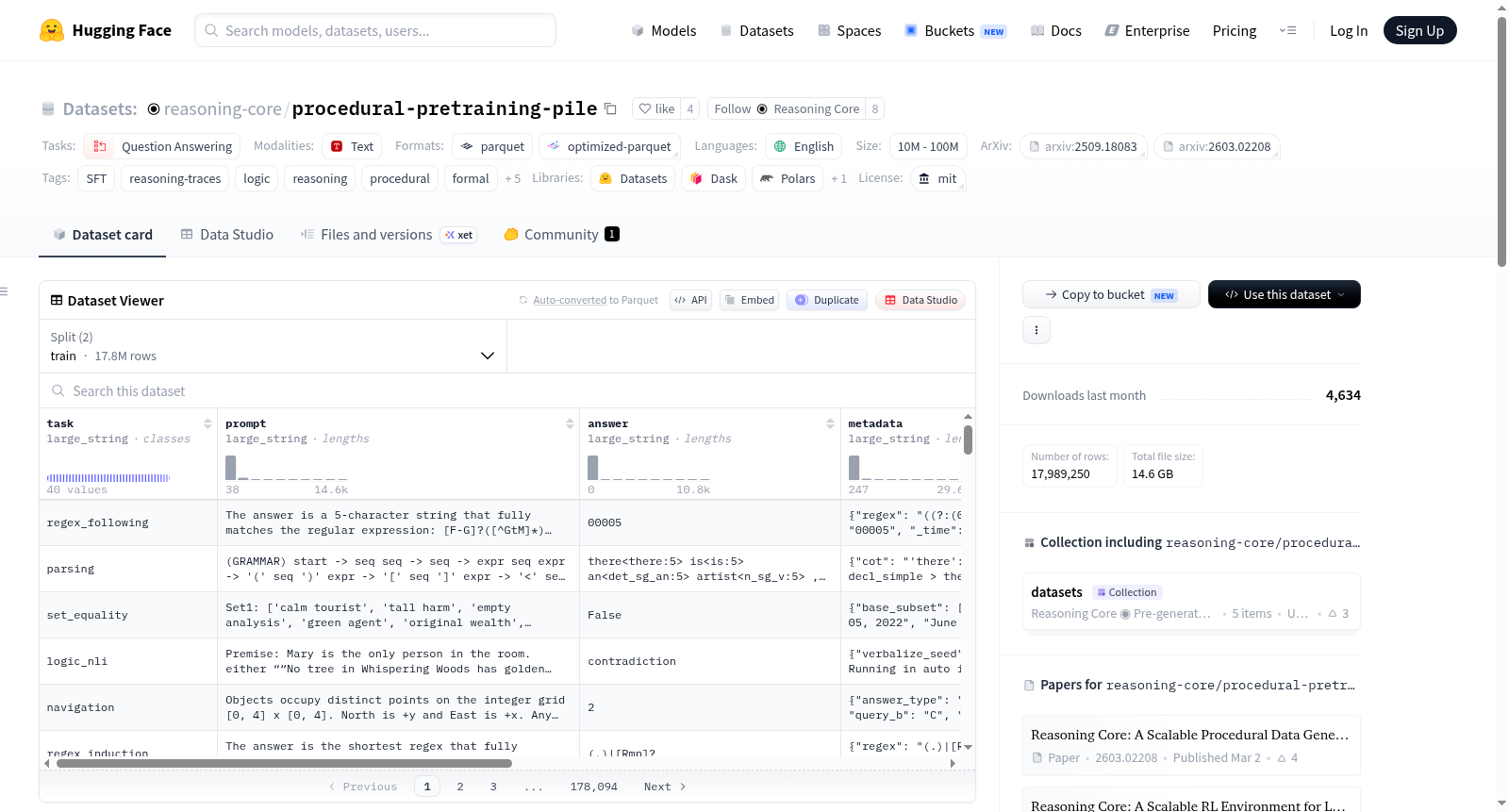
Reasoning-Core: Symbolic Pre-Training pile (SPT)是一个用于符号/形式预训练、中期训练和监督微调(SFT)的数据集。数据通过CPU程序生成,可扩展到万亿令牌规模,且难度可调。数据集涵盖多种任务类别,包括形式推理、形式语义和逻辑、数学计算、代码执行、图论、概率、语言解析和语法、表格处理以及集合操作等。提供三种任务模式:指令模式、跟踪模式和验证模式,以适应不同的训练需求。
Reasoning-Core: Symbolic Pre-Training pile (SPT) is a dataset designed for symbolic/formal pre-training, mid-training, and supervised fine-tuning (SFT). The data is procedurally generated on CPU and can be scaled to trillion tokens, with adjustable difficulty. It covers various task categories such as formal reasoning, formal semantics and logic, mathematical computation, code execution, graph theory, probabilistic tasks, language parsing and syntax, table processing, and set operations. Three task modes are provided: Instruct mode, Trace mode, and Verification mode, catering to different training needs.
提供机构:
reasoning-core
搜集汇总
数据集介绍
构建方式
Procedural-Pretraining-Pile(PPTP)数据集通过程序化生成方式构建,旨在为大型语言模型提供形式化与符号化推理训练资源。其生成过程完全基于CPU,可扩展至万亿token规模,并支持通过单一旋钮调节难度级别。数据涵盖形式推理、形式语义与逻辑、数学计算、代码执行、图论、概率推理、语言解析、表格处理及集合操作等九大任务类别,每个类别又细分为多项具体任务,如规划、证明重构、逻辑蕴含、方程求解、代码差异预测、图路径查找、贝叶斯推理等,确保训练数据的多样性与结构化覆盖。
使用方法
使用PPTP数据集时,可通过HuggingFace的datasets库直接加载,调用`load_dataset('reasoning-core/symbolic-pretraining-pile')`即可获取训练与测试分割。数据以默认配置提供,训练集文件路径为`data/train-*`,测试集为`data/test-*`。用户可根据需求选择特定任务模式,如直接使用提示与答案进行监督微调,或利用推理轨迹进行思维链训练,亦可通过验证模式强化模型的自校验能力。论文与代码仓库已公开,便于进一步探索与复现。
背景与挑战
背景概述
在大型语言模型(LLM)的研发进程中,提升其符号化推理与形式化逻辑能力已成为关键挑战。在此背景下,由Valentin Lacombe、Valentin Quesnel与Damien Sileo等研究人员于2026年提出的Reasoning Core环境应运而生,其配套的Procedural Pre-Training Pile(PPTP)数据集则成为该领域的重要资源。该数据集聚焦于通过程序化生成技术构建涵盖形式推理、数学计算、代码执行、图论、概率推理、语言解析及表处理等十余类核心任务的预训练语料库,旨在弥补现有数据在符号推理深度与结构化逻辑方面的不足。PPTP的推出为LLM的形式化预训练、中间训练及监督微调提供了可扩展至数万亿token的可靠数据源,其基于外部工具验证的答案正确性设计,显著区别于依赖于大模型生成的不确定性合成数据,对推动模型从统计关联向因果推理与逻辑演绎的跃迁具有深远影响。
当前挑战
PPTP数据集所应对的领域核心挑战在于,当前LLM在面临需要严密逻辑推理与形式化操作的任务时,普遍暴露出推理链条不连贯、符号违背约束及抽象规则泛化能力薄弱等缺陷,传统自然语言数据集难以触及此类深层次认知瓶颈。在构建过程中,研究人员需克服多重技术障碍:首先,程序化生成必须确保任务在无限扩充时保持语义一致性及难度可调性,这要求对每类任务设计高泛化性的分布模型;其次,由于涉及PDDL规划、一阶逻辑等复杂形式系统,如何将符号约束转化为可验证的奖励信号并避免答案歧义成为关键挑战;此外,数据规模达数十GB且类别高度异构的背景下,维持不同模态(指令、推理轨迹、验证模式)间的格式统一与质量均一性也构成了显著的工程负担。
常用场景
经典使用场景
Procedural Pre-Training Pile 最为经典的使用场景在于大规模语言模型的符号预训练与中间训练阶段。与传统依赖人工标注或大模型生成的语料不同,该数据集通过程序化生成方式,在 CPU 上高效产出涵盖形式推理、形式语义、数学计算、代码执行、图论、概率推理、语言解析、表格处理及集合操作等九大类任务的海量样本。其难度可通过单一旋钮连续调节,且答案天然正确,无需后验校验。这使得研究者能够在不依赖昂贵人工或不可控生成模型的前提下,为语言模型注入结构化的符号推理能力,尤其适用于增强模型在抽象逻辑、精确计算与形式化任务上的基础素养。数据集同时提供了指令、推理链与验证三种模式,为监督微调与强化学习统一了数据格式,极大便利了多阶段训练流程。
解决学术问题
该数据集系统性地解决了语言模型在符号推理与形式化任务上长期存在的训练数据匮乏与质量不可控问题。学术界普遍面临的一个核心挑战是:大规模语料库中蕴含的自然语言推理链往往隐含歧义,且难以构造出覆盖全面、难度可控的训练样本。PPTP 通过程序化生成确保每一条数据都具备可验证的精确答案,从而为因果推理、图论分析、规划验证等需要严格逻辑闭合的学术问题提供了可靠训练基础。它直接推动了形式化推理与自然语言理解之间的桥接研究,使模型在诸如逻辑蕴含判定、正则表达式推导、计划生成等抽象任务上的表现有了可量化的提升基准,并为后续可验证奖励强化学习(RLVR)范式的学术探索奠定了数据与评估基础。
实际应用
在实际应用层面,PPTP 数据集赋能了多个高价值场景。在软件工程领域,基于代码执行预测与差异补丁生成任务,模型可以被训练用于自动化 bug 修复与代码审查辅助;在数据分析场景中,表格问答与表格转换任务帮助模型掌握结构化查询与跨格式数据理解能力。金融与科学计算领域受益于算术与符号计算任务,使得模型能够可靠处理多步代数方程与序列归纳推理。此外,图论任务如路径查找与同构检测可直接服务于生物信息学与社交网络分析,而概率推理任务如贝叶斯关联与干预则为医疗诊断与因果推断工具提供了底层推理支持。语言解析与正则归纳任务同样为智能文档处理与自然语言界面设计提供了技术支撑。
数据集最近研究
最新研究方向
在形式化符号推理的前沿探索中,Procedural Pre-Training Pile(PPTP)数据集通过程序化生成机制,为大型语言模型提供了可无限扩展且答案天然正确的预训练、中期训练及指令微调资源。其涵盖规划推理、形式语义、数学计算、代码执行、图论分析及概率推理等多元任务,并创新性地设计了指令、推理轨迹与验证三种模式,旨在深度强化模型的链式推理与自我验证能力。结合最新强化学习与可验证奖励(RLVR)环境的集成,PPTP正推动LLM在零样本符号推理任务中突破性能瓶颈,成为连接程序化知识生成与复杂认知能力进化的关键基础设施。
以上内容由遇见数据集搜集并总结生成


