SwissGov-RSD
收藏arXiv2025-12-08 更新2025-12-10 收录
下载链接:
https://huggingface.co/datasets/ZurichNLP/SwissGov-RSD
下载链接
链接失效反馈官方服务:
资源简介:
SwissGov-RSD是由苏黎世大学团队构建的首个跨语言文档级语义差异标注数据集,源自瑞士政府门户网站admin.ch的多语言平行文本。该数据集包含224组英德、英法、英意三语对文档,共计约17-19万Tokens,通过人工标注实现细粒度的token级差异标注(0-5分制)。数据经过严格筛选与双人交叉验证,标注一致性在EN-IT语对表现最佳(F1=55.6)。该数据集旨在解决跨语言内容对齐、机器翻译评估等任务中真实场景下的语义差异检测难题,为自然语言理解研究提供重要基准。
SwissGov-RSD is the first cross-lingual document-level semantic difference annotation dataset developed by the team at the University of Zurich, derived from multilingual parallel texts hosted on the Swiss government portal admin.ch. The dataset comprises 224 sets of trilingual document pairs across English-German, English-French, and English-Italian, with a total of approximately 170,000 to 190,000 Tokens. It features fine-grained token-level difference annotations scored on a 0-5 scale, generated through manual annotation. The dataset has undergone rigorous screening and dual annotator cross-validation, with the highest inter-annotator agreement observed for the EN-IT language pair, yielding an F1 score of 55.6. This dataset aims to address the challenge of real-world semantic difference detection in tasks such as cross-lingual content alignment and machine translation evaluation, serving as a critical benchmark for natural language understanding research.
提供机构:
苏黎世大学计算语言学系
创建时间:
2025-12-08
原始信息汇总
SwissGov-RSD 数据集概述
数据集基本信息
- 数据集名称: SwissGov-RSD
- 许可证: CC-BY-4.0
- 支持语言: 德语 (de)、法语 (fr)、意大利语 (it)、英语 (en)
- 配置: 包含德语 (de)、意大利语 (it)、法语 (fr) 三种配置。
数据集描述
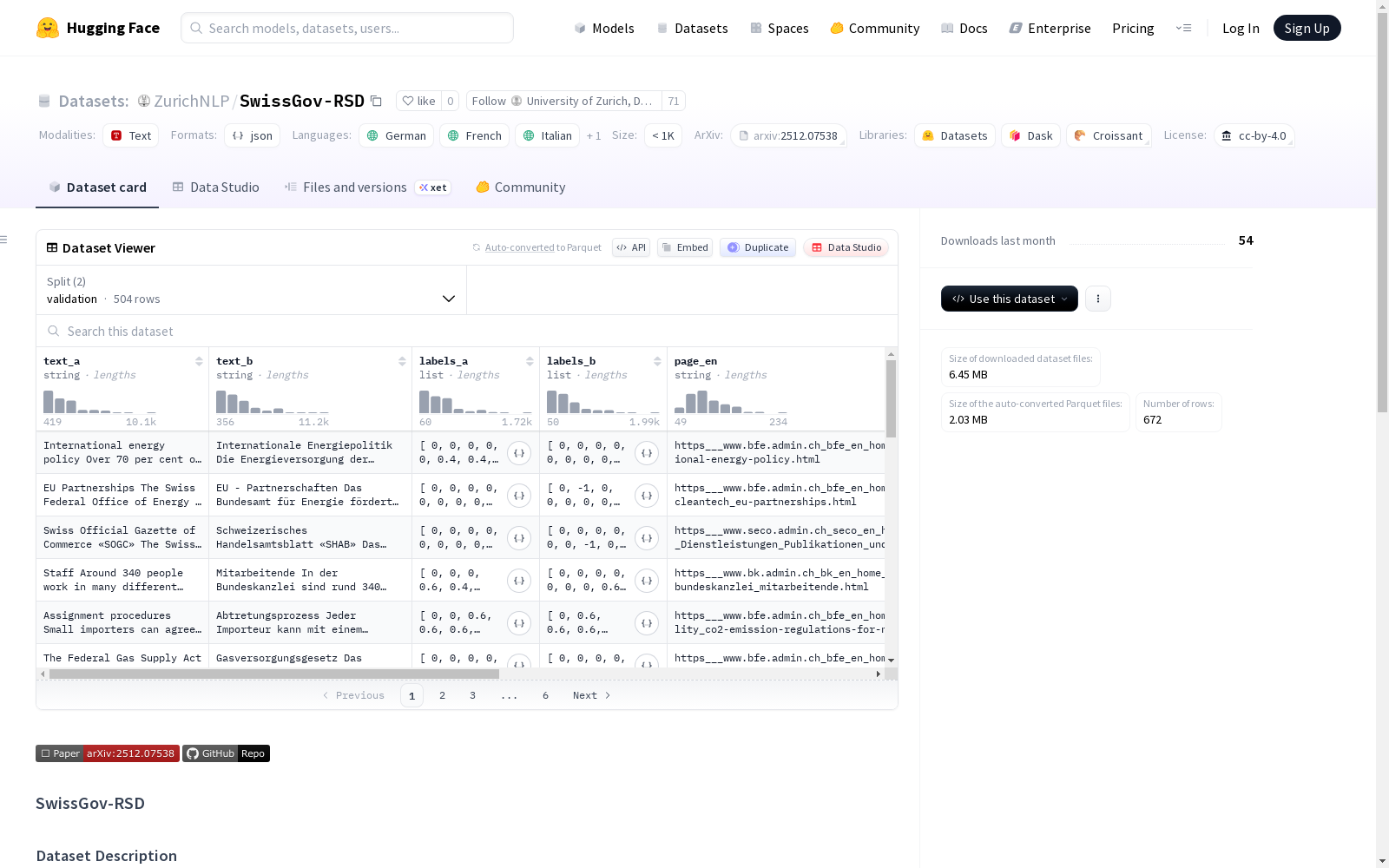
SwissGov-RSD 是一个自然的、人工标注的、文档级别的、跨语言的、用于词元级别语义差异识别 (RSD) 的数据集。它包含来自 admin.ch 的 224 份多语言平行瑞士政府文档,涵盖英语-德语、英语-法语和英语-意大利语,并在词元级别标注了细粒度的语义差异标签 (0–1)。该数据集针对因翻译错误、异步更新或显化导致跨语言内容差异的真实场景。
数据集结构
数据集为每个语言对包含 224 个文档对。每个样本包含以下字段:
- text_a: 文档对的英语侧文本(字符串)。
- text_b: 文档对的非英语侧文本(字符串)。
- labels_a: 英语侧每个单词(以空格分隔)的标签,范围从 0 到 1(标点符号 = -1)。
- labels_b: 非英语侧每个单词(以空格分隔)的标签,范围从 0 到 1(标点符号 = -1)。
- page_en: 英语语言侧被抓取网页的 URL。
- page_other: 非英语语言侧被抓取网页的 URL。
- subset: 根据语言划分的子集名称。
- id: 样本 ID。
引用信息
bibtex @misc{wastl2025swissgovrsdhumanannotatedcrosslingualbenchmark, title={SwissGov-RSD: A Human-annotated, Cross-lingual Benchmark for Token-level Recognition of Semantic Differences Between Related Documents}, author={Michelle Wastl and Jannis Vamvas and Rico Sennrich}, year={2025}, eprint={2512.07538}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2512.07538}, }
相关资源链接
- 论文: https://arxiv.org/pdf/2512.07538
- GitHub 仓库: https://github.com/ZurichNLP/SwissGov-RSD
搜集汇总
数据集介绍
构建方式
在跨语言文档语义差异识别的研究中,构建高质量的自然数据集是推动算法发展的关键。SwissGov-RSD数据集通过系统化的流程构建而成,其核心步骤包括从瑞士政府门户网站admin.ch及其子域中爬取多语言平行文档,涵盖英语、德语、法语和意大利语版本。经过严格的筛选,保留至少包含三个自然语言句子的文档,并剔除非语言类页面。最终,由经过培训的计算语言学专业标注者对文档对进行细粒度的词级语义差异标注,采用五级评分体系,标注过程包含试验阶段和主阶段,并通过重叠样本评估标注者间一致性,确保数据质量。
特点
SwissGov-RSD数据集在跨语言语义差异识别领域展现出独特优势。作为首个自然产生的、文档级别的跨语言基准数据集,它包含224个多平行文档对,覆盖英语-德语、英语-法语和英语-意大利语三种语言组合,文档长度从50到超过2500词不等,平均长度约400词。数据集标注了词级语义差异,差异标签分布显示约10-17%的词被标记为存在语义差异,与合成数据集相比,其语义等效与差异的比例更为倾斜。此外,数据来源于真实的政府多语言网站,差异自然产生于翻译误差或内容更新不同步,因此更具现实性和挑战性。
使用方法
SwissGov-RSD数据集主要用于评估自动识别跨语言文档间语义差异的系统性能。研究人员可将其作为基准测试平台,比较无监督方法、少样本提示、微调大型语言模型以及编码器模型等多种技术。使用该数据集时,通常采用词级斯皮尔曼相关系数等指标,将模型预测的差异分数与人工标注的金标准进行对比。数据集支持跨语言场景下的模型泛化能力分析,尤其适用于检验模型从合成数据到自然数据的迁移效果。此外,其多语言平行结构也便于进行语言对间的性能比较和错误分析。
背景与挑战
背景概述
SwissGov-RSD数据集由苏黎世大学计算语言学系的研究人员于2025年创建,旨在解决跨语言文档间语义差异识别的核心研究问题。该数据集从瑞士政府门户网站admin.ch收集了224组多语言平行文档,涵盖英语-德语、英语-法语和英语-意大利语三种语言对,并提供了人工标注的词级语义差异标签。作为首个自然场景下的文档级跨语言语义差异识别基准,SwissGov-RSD填补了该领域真实数据资源的空白,对机器翻译评估、多语言内容对齐及文本生成质量检验等研究方向具有重要推动力。
当前挑战
SwissGov-RSD数据集面临的挑战主要体现在两个方面:在领域问题层面,该数据集致力于解决跨语言文档间细粒度语义差异识别这一复杂任务,其挑战在于如何准确捕捉从词汇替换到段落省略等多种类型的语义偏差,尤其在长文档和多语言语境下,现有模型表现显著下降。在构建过程中,挑战包括从多语言政府网站中筛选和清洗自然发生的语义差异数据,确保文档对齐质量;同时,人工标注需要处理标注者间一致性差异,尤其是在跨语言语境下对语义差异程度的主观判断,这增加了数据集构建的复杂性和成本。
常用场景
经典使用场景
在跨语言自然语言处理领域,SwissGov-RSD数据集为语义差异识别任务提供了首个基于真实政府文档的细粒度标注基准。该数据集源自瑞士政府门户网站的多语言平行文本,涵盖英语与德语、法语、意大利语之间的224组文档对,每对均包含人工标注的词级语义差异标签。其经典应用场景在于评估和提升大型语言模型及编码器模型在跨语言文档对齐中的性能,尤其适用于检测翻译误差、内容更新不同步导致的语义偏差。研究者通过该数据集能够系统分析模型在真实、长文档场景下识别语义差异的能力,弥补了以往合成数据在自然性和复杂性上的不足。
解决学术问题
SwissGov-RSD数据集主要解决了跨语言语义差异识别中的若干核心学术问题。传统研究多依赖于单语、句子级或合成数据,难以反映真实场景中文档级、跨语言的复杂差异模式。该数据集通过提供自然发生的多语言政府文本,支持对词级语义差异的回归建模,使研究者能够深入探究模型在长文档、跨语言情境下的泛化能力。其意义在于揭示了当前先进模型在合成数据与真实数据之间存在显著性能差距,推动了针对实际应用需求的语义理解方法创新,并为机器翻译评估、多语言内容对齐等任务提供了更可靠的评估基准。
衍生相关工作
SwissGov-RSD数据集的发布催生了一系列围绕跨语言语义差异识别的衍生研究。基于该数据集,学者们进一步探索了无监督对齐算法(如DiffAlign)在长文档场景下的鲁棒性,并比较了不同编码器模型(如XLM-R、ModernBERT)与大型语言模型(如GPT-4o、Llama系列)的性能差异。相关工作还扩展至标签投影技术,利用大型语言模型将英语标注迁移至其他语言,以缓解跨语言标注数据稀缺的问题。这些研究不仅深化了对语义差异识别任务的理解,也为构建更适应真实场景的评估框架与方法论提供了实证基础。
以上内容由遇见数据集搜集并总结生成


