visualwebbench/VisualWebBench
收藏Hugging Face2024-04-11 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/visualwebbench/VisualWebBench
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: action_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: instruction
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 116178465
num_examples: 103
download_size: 116152003
dataset_size: 116178465
- config_name: action_prediction
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: options
sequence: string
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 212320282
num_examples: 281
download_size: 212176366
dataset_size: 212320282
- config_name: element_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 541444180
num_examples: 413
download_size: 425203495
dataset_size: 541444180
- config_name: element_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 177127391
num_examples: 245
download_size: 177036578
dataset_size: 177127391
- config_name: heading_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 36406054
num_examples: 46
download_size: 36401829
dataset_size: 36406054
- config_name: web_caption
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 112890184
num_examples: 134
download_size: 112864700
dataset_size: 112890184
- config_name: webqa
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: test
num_bytes: 271769428
num_examples: 314
download_size: 100761418
dataset_size: 271769428
configs:
- config_name: action_ground
data_files:
- split: test
path: action_ground/test-*
- config_name: action_prediction
data_files:
- split: test
path: action_prediction/test-*
- config_name: element_ground
data_files:
- split: test
path: element_ground/test-*
- config_name: element_ocr
data_files:
- split: test
path: element_ocr/test-*
- config_name: heading_ocr
data_files:
- split: test
path: heading_ocr/test-*
- config_name: web_caption
data_files:
- split: test
path: web_caption/test-*
- config_name: webqa
data_files:
- split: test
path: webqa/test-*
license: apache-2.0
task_categories:
- image-to-text
- visual-question-answering
language:
- en
pretty_name: VisualWebBench
size_categories:
- 1K<n<10K
---
# VisualWebBench
Dataset for the paper: [VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?](https://arxiv.org/abs/2404.05955)
[**🌐 Homepage**](https://visualwebbench.github.io/) | [**🐍 GitHub**](https://github.com/VisualWebBench/VisualWebBench) | [**📖 arXiv**](https://arxiv.org/abs/2404.05955)
## Introduction
We introduce **VisualWebBench**, a multimodal benchmark designed to assess the **understanding and grounding capabilities of MLLMs in web scenarios**. VisualWebBench consists of **seven tasks**, and comprises **1.5K** human-curated instances from **139** real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude 3, and GPT-4V(ision) on WebBench, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe VisualWebBench will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
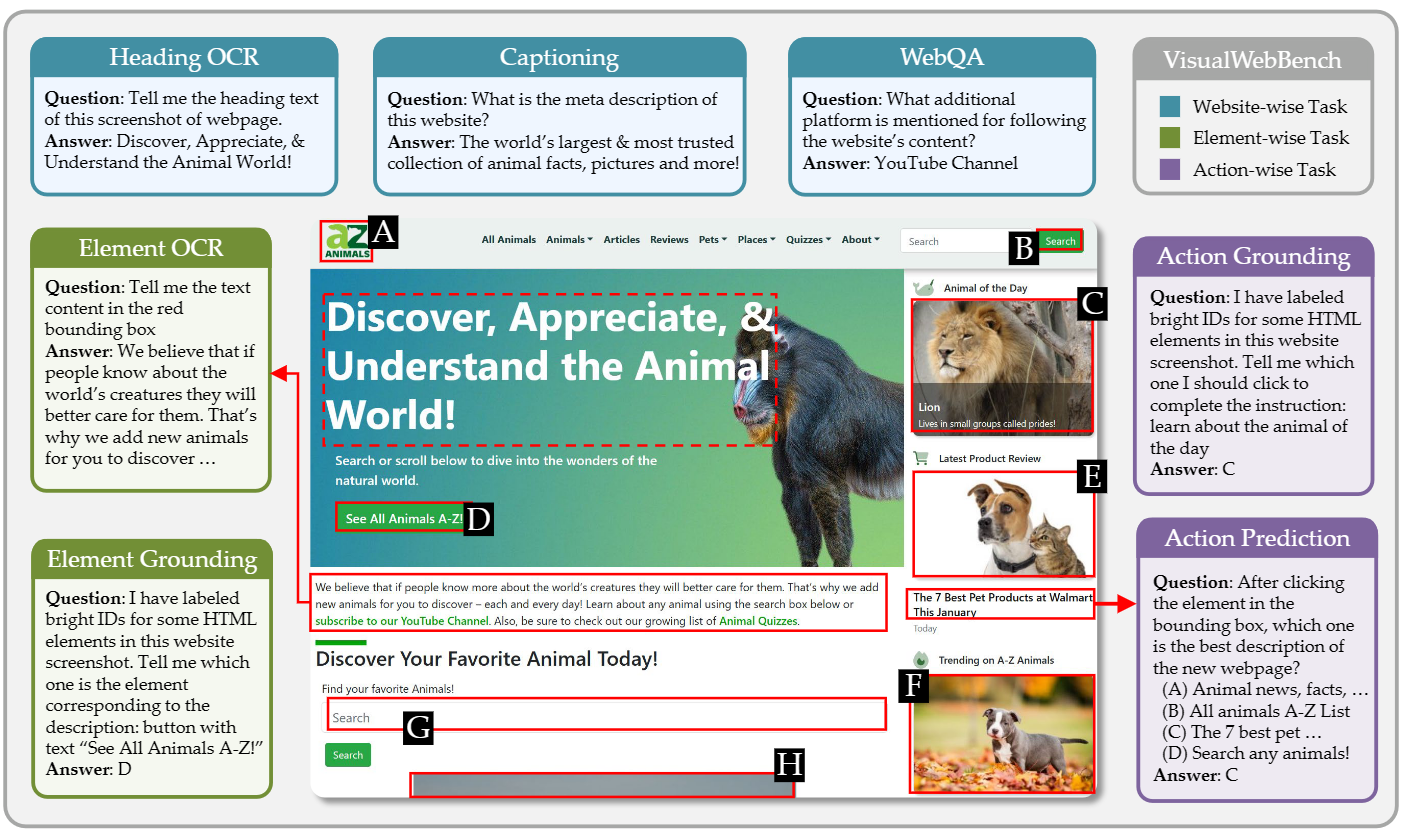
## Benchmark Construction
We introduce VisualWebBench, a comprehensive multimodal benchmark designed to assess the capabilities of MLLMs in the web domain. Inspired by the human interaction process with web browsers, VisualWebBench consists of seven tasks that map to core abilities required for web tasks: captioning, webpage QA, heading OCR, element OCR, element grounding, action prediction, and action grounding, as detailed in the figure. The benchmark comprises 1.5K instances, all uniformly formulated in the QA style, making it easy to evaluate and compare the performance of different MLLMs.
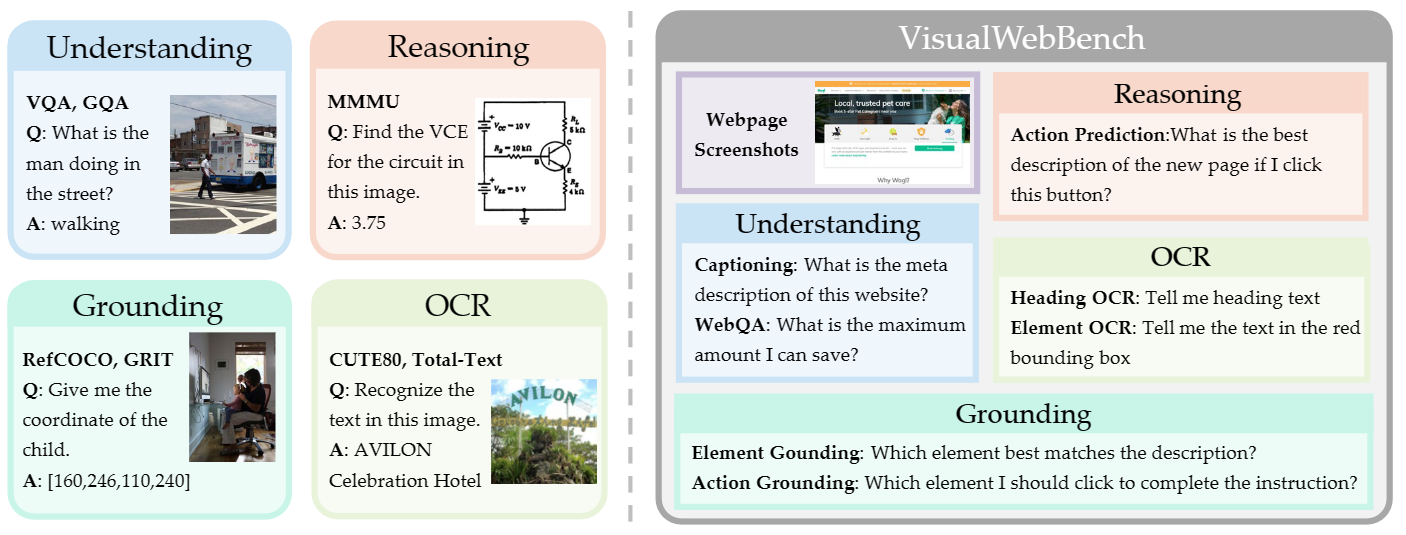
The proposed VisualWebBench possesses the following features:
- **Comprehensiveness**: VisualWebBench spans 139 websites with 1.5K samples, encompassing 12 different domains (e.g., travel, sports, hobby, lifestyle, animals, science, etc.) and 87 sub-domains.
- **Multi-granularity**: VisualWebBench assesses MLLMs at three levels: website-level, element-level, and action-level.
- **Multi-tasks**: WebBench encompasses seven tasks designed to evaluate the understanding, OCR, grounding, and reasoning capabilities of MLLMs.
- **High quality**: Quality is ensured through careful human verification and curation efforts.
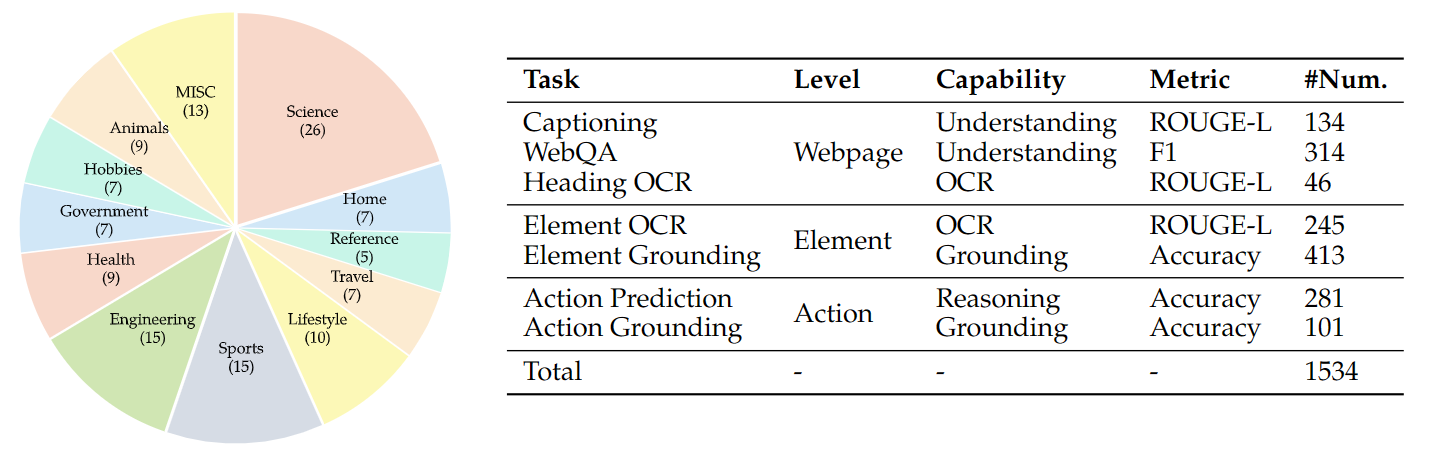
## Evaluation
We provide [evaluation code](https://github.com/VisualWebBench/VisualWebBench) for GPT-4V, Claude, Gemini, and LLaVA 1.6 series.
## Contact
- Junpeng Liu: [jpliu@link.cuhk.edu.hk](jpliu@link.cuhk.edu.hk)
- Yifan Song: [yfsong@pku.edu.cn](yfsong@pku.edu.cn)
- Xiang Yue: [xyue2@andrew.cmu.edu](xyue2@andrew.cmu.edu)
## Citation
If you find this work helpful, please cite out paper:
```
@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
dataset_info:
- 配置名称:action_ground
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:raw_image
数据类型:原始图像(image)
- 字段名:options
数据类型:浮点数序列的序列(sequence: sequence: float64)
- 字段名:instruction
数据类型:字符串
- 字段名:answer
数据类型:64位整数(int64)
拆分:
- 名称:test
字节数:116178465
样本数:103
下载大小:116152003
数据集大小:116178465
- 配置名称:action_prediction
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:options
数据类型:字符串序列(sequence: string)
- 字段名:bbox
数据类型:边界框(Bounding Box,bbox)序列,64位浮点数(sequence: float64)
- 字段名:elem_desc
数据类型:元素描述(elem_desc)
- 字段名:answer
数据类型:64位整数(int64)
拆分:
- 名称:test
字节数:212320282
样本数:281
下载大小:212176366
数据集大小:212320282
- 配置名称:element_ground
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:raw_image
数据类型:原始图像(image)
- 字段名:options
数据类型:浮点数序列的序列(sequence: sequence: float64)
- 字段名:elem_desc
数据类型:元素描述(elem_desc)
- 字段名:answer
数据类型:64位整数(int64)
拆分:
- 名称:test
字节数:541444180
样本数:413
下载大小:425203495
数据集大小:541444180
- 配置名称:element_ocr
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:bbox
数据类型:边界框(Bounding Box,bbox)序列,64位浮点数(sequence: float64)
- 字段名:elem_desc
数据类型:元素描述(elem_desc)
- 字段名:answer
数据类型:字符串(string)
拆分:
- 名称:test
字节数:177127391
样本数:245
下载大小:177036578
数据集大小:177127391
- 配置名称:heading_ocr
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:bbox
数据类型:边界框(Bounding Box,bbox)序列,64位浮点数(sequence: float64)
- 字段名:answer
数据类型:字符串(string)
拆分:
- 名称:test
字节数:36406054
样本数:46
下载大小:36401829
数据集大小:36406054
- 配置名称:web_caption
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:answer
数据类型:字符串(string)
拆分:
- 名称:test
字节数:112890184
样本数:134
下载大小:112864700
数据集大小:112890184
- 配置名称:webqa
特征:
- 字段名:id
数据类型:字符串(string)
- 字段名:task_type
数据类型:字符串
- 字段名:website
数据类型:字符串
- 字段名:image
数据类型:图像(image)
- 字段名:image_size
数据类型:64位整数序列(sequence: int64)
- 字段名:question
数据类型:字符串(string)
- 字段名:answer
数据类型:字符串序列(sequence: string)
拆分:
- 名称:test
字节数:271769428
样本数:314
下载大小:100761418
数据集大小:271769428
配置项:
- 配置名称:action_ground
数据文件:
- 拆分:test
路径:action_ground/test-*
- 配置名称:action_prediction
数据文件:
- 拆分:test
路径:action_prediction/test-*
- 配置名称:element_ground
数据文件:
- 拆分:test
路径:element_ground/test-*
- 配置名称:element_ocr
数据文件:
- 拆分:test
路径:element_ocr/test-*
- 配置名称:heading_ocr
数据文件:
- 拆分:test
路径:heading_ocr/test-*
- 配置名称:web_caption
数据文件:
- 拆分:test
路径:web_caption/test-*
- 配置名称:webqa
数据文件:
- 拆分:test
路径:webqa/test-*
许可证:apache-2.0
任务类别:
- 图像到文本(image-to-text)
- 视觉问答(visual-question-answering)
语言:英语(en)
展示名称:VisualWebBench
样本规模:1000 < 样本数 < 10000
# VisualWebBench
本数据集对应论文:《VisualWebBench:多模态大语言模型(Multimodal Large Language Model,MLLM)在网页理解与定位方面的演进程度如何?》(https://arxiv.org/abs/2404.05955)
[🌐 项目主页](https://visualwebbench.github.io/) | [🐍 GitHub 仓库](https://github.com/VisualWebBench/VisualWebBench) | [📖 arXiv 论文](https://arxiv.org/abs/2404.05955)
## 简介
我们提出**VisualWebBench**,一款用于评估**多模态大语言模型(Multimodal Large Language Model,MLLM)在网页场景下的理解与定位能力**的多模态基准测试集。VisualWebBench包含**7项任务**,共包含来自**139个真实网站**的**1.5K**条人工标注样本,覆盖87个子领域。我们在该基准上测试了14款开源MLLM、Gemini Pro、Claude 3以及GPT-4V(视觉)模型,揭示了当前模型面临的显著挑战与性能差距。进一步的分析指出了当前MLLM的局限性,包括在文本丰富环境中的定位能力不足以及低分辨率图像输入下的表现欠佳。我们相信VisualWebBench将为研究社区提供宝贵的资源,并助力开发适用于网页相关应用的更强大、更通用的MLLM。

## 基准测试集构建
我们提出VisualWebBench,一款用于评估网页领域MLLM能力的全面多模态基准测试集。受人类与网页浏览器交互过程的启发,VisualWebBench包含7项任务,对应网页任务所需的核心能力:图像描述、网页问答、标题光学字符识别(Heading Optical Character Recognition,Heading OCR)、元素光学字符识别(Element Optical Character Recognition,Element OCR)、元素定位(Element Grounding)、动作预测(Action Prediction)以及动作定位(Action Grounding),具体细节如图所示。该基准测试集共包含1.5K条样本,全部统一采用问答(QA)格式,便于评估与对比不同MLLM的性能。

本基准测试集具备以下特点:
- **全面性**:VisualWebBench涵盖139个网站、1.5K条样本,覆盖12个不同领域(例如旅游、体育、爱好、生活方式、动物、科学等)以及87个子领域。
- **多粒度**:VisualWebBench从三个层级评估MLLM:网站层级、元素层级以及动作层级。
- **多任务**:VisualWebBench包含7项任务,用于评估MLLM的理解、光学字符识别、定位与推理能力。
- **高质量**:所有样本均经过严格的人工验证与标注流程,确保数据质量。

## 评估
我们提供了针对GPT-4V、Claude、Gemini以及LLaVA 1.6系列模型的[评估代码](https://github.com/VisualWebBench/VisualWebBench)。
## 联系方式
- 刘俊鹏:[jpliu@link.cuhk.edu.hk](jpliu@link.cuhk.edu.hk)
- 宋一帆:[yfsong@pku.edu.cn](yfsong@pku.edu.cn)
- 岳翔:[xyue2@andrew.cmu.edu](xyue2@andrew.cmu.edu)
## 引用
若您认为本工作对您有所帮助,请引用我们的论文:
@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
visualwebbench
原始信息汇总
数据集概述
数据集名称
- VisualWebBench
数据集配置
-
action_ground
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- raw_image: image
- options: sequence of sequence of float64
- instruction: string
- answer: int64
- 分割:
- test
- num_bytes: 116178465
- num_examples: 103
- download_size: 116152003
- dataset_size: 116178465
- test
- 特征:
-
action_prediction
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- options: sequence of string
- bbox: sequence of float64
- elem_desc: string
- answer: int64
- 分割:
- test
- num_bytes: 212320282
- num_examples: 281
- download_size: 212176366
- dataset_size: 212320282
- test
- 特征:
-
element_ground
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- raw_image: image
- options: sequence of sequence of float64
- elem_desc: string
- answer: int64
- 分割:
- test
- num_bytes: 541444180
- num_examples: 413
- download_size: 425203495
- dataset_size: 541444180
- test
- 特征:
-
element_ocr
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- bbox: sequence of float64
- elem_desc: string
- answer: string
- 分割:
- test
- num_bytes: 177127391
- num_examples: 245
- download_size: 177036578
- dataset_size: 177127391
- test
- 特征:
-
heading_ocr
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- bbox: sequence of float64
- answer: string
- 分割:
- test
- num_bytes: 36406054
- num_examples: 46
- download_size: 36401829
- dataset_size: 36406054
- test
- 特征:
-
web_caption
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- answer: string
- 分割:
- test
- num_bytes: 112890184
- num_examples: 134
- download_size: 112864700
- dataset_size: 112890184
- test
- 特征:
-
webqa
- 特征:
- id: string
- task_type: string
- website: string
- image: image
- image_size: sequence of int64
- question: string
- answer: sequence of string
- 分割:
- test
- num_bytes: 271769428
- num_examples: 314
- download_size: 100761418
- dataset_size: 271769428
- test
- 特征:
许可证
- apache-2.0
任务类别
- image-to-text
- visual-question-answering
语言
- en
大小类别
- 1K<n<10K
搜集汇总
数据集介绍
构建方式
在网页理解与交互的复杂场景中,VisualWebBench的构建遵循了系统化与层次化的设计原则。该数据集从139个真实网站中精心采集了1.5K个高质量样本,覆盖了旅行、体育、科学等12个主要领域及其87个子领域。其构建过程模拟了人类与网页浏览器的交互流程,将核心能力解构为七个具体任务,包括网页描述、问答、光学字符识别、元素定位、动作预测与动作定位等。所有实例均以统一的问答形式进行组织,确保了评估框架的一致性与可比性,并通过严格的人工验证流程保障了数据的准确性与可靠性。
特点
VisualWebBench的显著特征在于其多维度的评估体系与丰富的任务内涵。数据集具备高度的综合性,不仅样本来源广泛,覆盖了多样化的网页主题与交互情境。其评估框架呈现出多粒度特性,从整体网站层面的理解,到具体页面元素的识别,再到用户交互动作的预测,形成了层次分明的能力考察体系。同时,数据集整合了七项核心任务,旨在全面检验多模态大语言模型在理解、识别、定位与推理等方面的综合性能。这种多任务、多粒度的设计,为深入分析模型在富文本、低分辨率图像等复杂网页环境中的能力边界提供了结构化基础。
使用方法
在具体应用层面,VisualWebBench为评估多模态大语言模型的网页理解能力提供了标准化的测试平台。研究人员可通过官方提供的评估代码,对包括GPT-4V、Claude、Gemini及LLaVA系列在内的多种模型进行系统性评测。数据集以配置(config)形式组织,每个任务对应独立的测试分割(test split),用户可根据需要加载特定任务的数据。评估过程主要围绕模型对给定网页截图及自然语言指令的响应展开,通过对比模型输出与标注答案,量化模型在各项任务上的表现。该基准旨在推动模型在真实网页交互场景中的能力演进,并为相关应用开发提供性能参照。
背景与挑战
背景概述
在人工智能与多模态学习模型蓬勃发展的背景下,网页作为信息交互的核心载体,其视觉与文本内容的深度理解成为关键研究课题。VisualWebBench数据集由香港中文大学、北京大学及卡内基梅隆大学等机构的研究团队于2024年共同创建,旨在系统评估多模态大语言模型在网页场景中的理解与定位能力。该数据集涵盖来自139个真实网站的1.5K个高质量样本,涉及网页描述、问答、光学字符识别、元素定位及行为预测等七项核心任务,为衡量模型在复杂网页环境下的综合性能提供了标准化基准,推动了多模态模型在网页交互应用中的演进。
当前挑战
VisualWebBench致力于解决多模态大语言模型在网页理解与定位任务中的核心挑战,包括模型在文本密集环境下的精准定位能力不足、对低分辨率图像输入的适应性较弱,以及跨多样化网页布局与领域的泛化性能有限。在数据集构建过程中,研究团队面临网页样本的多样性与复杂性带来的标注困难,需确保元素边界框与行为指令的精确对齐,同时维持多任务评估框架的一致性与可扩展性,这些挑战共同塑造了数据集的严谨结构与评估深度。
常用场景
经典使用场景
在网页理解与交互的学术探索中,VisualWebBench数据集为评估多模态大语言模型在真实网页环境中的综合能力提供了标准化的测试平台。该数据集通过涵盖网页描述、问答、光学字符识别、元素定位及动作预测等七项任务,模拟了人类与网页交互的核心流程,成为衡量模型在文本密集、视觉复杂的网页场景下理解与推理性能的经典基准。
解决学术问题
该数据集有效应对了多模态模型在网页领域评估体系缺失的学术挑战,通过构建涵盖多粒度、多任务的高质量样本,系统性地揭示了模型在文本丰富环境中的定位能力不足、低分辨率图像处理性能欠佳等关键局限。其意义在于为网页导向的多模态研究提供了可量化的评估框架,推动了模型在细粒度感知与交互推理方面的理论进展,促进了更强大、通用网页智能体的发展。
衍生相关工作
围绕VisualWebBench数据集,学术界衍生了一系列聚焦于提升多模态模型网页理解能力的研究工作。这些工作通常借鉴其任务框架与评估方法,进一步探索模型在元素定位精度、跨模态对齐以及指令跟随鲁棒性等方面的改进。相关研究不仅延续了对模型能力边界的探索,也催生了新的模型架构与训练策略,持续推动着网页智能体向更实用、更可靠的方向演进。
以上内容由遇见数据集搜集并总结生成


