rlcc-new-data-palate
收藏官方服务:
资源简介:
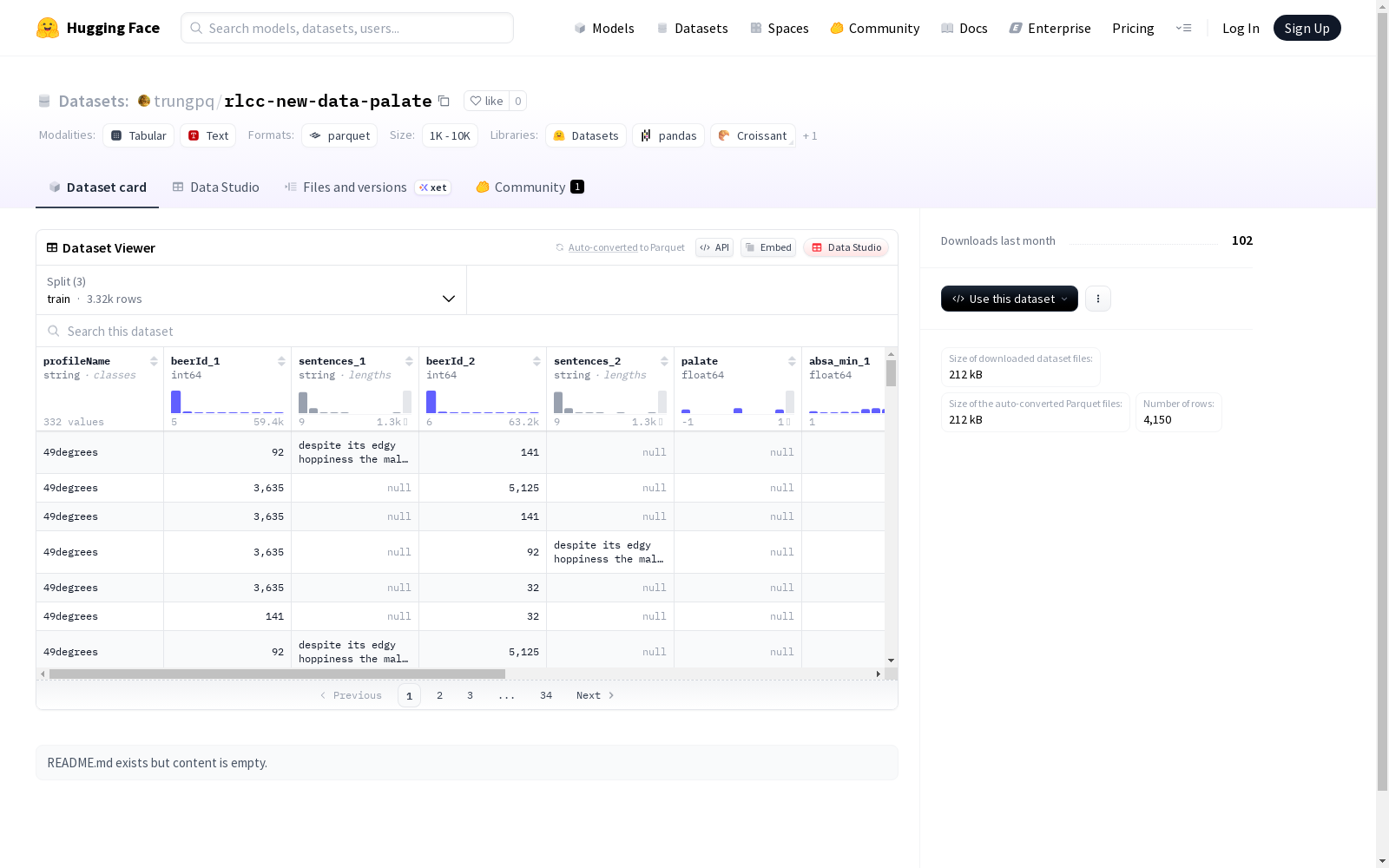
该数据集包含用户对啤酒的评论信息,其中包括用户名(profileName)、两个啤酒的ID(beerId_1和beerId_2)、两个啤酒的评论句子(sentences_1和sentences_2)、口感评分(palate),以及每个啤酒评论的ABSA情感分析的最小值、最大值和平均值(absa_min_1、absa_max_1、absa_avg_1、absa_min_2、absa_max_2和absa_avg_2)。数据集分为训练集、验证集和测试集,分别有3320、420和410个示例。
创建时间:
2025-09-10
原始信息汇总
数据集概述
基本信息
- 数据集名称:rlcc-new-data-palate
- 存储位置:https://huggingface.co/datasets/trungpq/rlcc-new-data-palate
数据特征
- profileName:字符串类型
- beerId_1:整型(int64)
- sentences_1:字符串类型
- beerId_2:整型(int64)
- sentences_2:字符串类型
- palate:浮点型(float64)
- absa_min_1:浮点型(float64)
- absa_max_1:浮点型(float64)
- absa_avg_1:浮点型(float64)
- absa_min_2:浮点型(float64)
- absa_max_2:浮点型(float64)
- absa_avg_2:浮点型(float64)
数据划分
- 训练集(train):3,320个样本,大小682,745字节
- 验证集(validation):420个样本,大小88,817字节
- 测试集(test):410个样本,大小90,454字节
存储信息
- 下载大小:212,408字节
- 数据集总大小:862,016字节
搜集汇总
数据集介绍
构建方式
在啤酒评论分析领域,rlcc-new-data-palate数据集通过精心设计的流程构建而成。该数据集采集了用户对啤酒的文本评论,并整合了啤酒标识符与感官评分数据,每条记录包含两个啤酒产品的对比评论及对应的口感评分。数据经过标准化清洗与标注,划分训练集、验证集和测试集,确保数据质量与一致性,为口味偏好研究提供可靠基础。
特点
该数据集具备多维度特征,涵盖用户昵称、啤酒ID、评论文本及口感评分等关键字段。特别之处在于包含每对啤酒评论的ABSA情感分析指标,如最小值、最大值和平均值,支持细粒度的情感与口味关联分析。数据规模适中,划分科学,适用于机器学习模型训练与验证,满足复杂分析需求。
使用方法
该数据集适用于啤酒口味分析与推荐系统研究,用户可加载训练集进行模型训练,利用验证集调参,并通过测试集评估性能。评论文本与ABSA指标结合,支持情感分析、口味预测或对比学习任务。数据以标准格式存储,可直接用于主流机器学习框架,促进啤酒行业智能化应用。
背景与挑战
背景概述
在自然语言处理与推荐系统交叉领域,rlcc-new-data-palate数据集由研究机构于近年构建,专注于啤酒风味评价的文本分析与用户偏好建模。该数据集通过整合用户评论与风味评分数据,旨在探索多维度感官描述与数值评分间的语义关联,为核心研究问题——基于文本的细粒度风味预测提供数据支撑。其创新性体现在将抽象的风味感知转化为可计算的文本表征,对食品计算与个性化推荐领域的发展具有显著推动作用。
当前挑战
该数据集需解决风味描述主观性与数值评分客观性之间的映射挑战,包括文本中隐含感官特征的提取、跨用户评价一致性建模等核心问题。构建过程中面临双重挑战:一是需从非结构化评论中精准提取风味属性并量化其强度,涉及细粒度情感分析技术;二是需对齐多源异构数据,如处理同一风味术语在不同语境下的语义漂移问题,以及解决评分尺度差异导致的数据标准化难题。
常用场景
经典使用场景
在自然语言处理与推荐系统交叉研究中,rlcc-new-data-palate数据集被广泛应用于啤酒风味对比分析任务。研究者通过该数据集中的用户评论文本与风味评分数据,训练模型理解不同啤酒产品的感官特征差异,从而构建精准的风味偏好预测系统。
解决学术问题
该数据集有效解决了细粒度情感分析与跨商品对比推荐的学术难题。通过提供配对啤酒评论与量化风味指标,支持研究者开发端到端的对比学习模型,显著提升了基于文本的推荐系统在风味维度上的可解释性与准确性,推动了多模态推荐算法的理论创新。
衍生相关工作
该数据集衍生出多项对比学习与注意力机制的创新研究,例如基于双向编码器的风味特征提取模型、结合数值评分与文本语义的融合推荐框架。这些工作显著推动了细粒度情感分析技术在食品领域的应用深度,为后续跨域商品对比数据集构建提供了重要范式参考。
以上内容由遇见数据集搜集并总结生成


