ClueWeb22
收藏arXiv2025-09-30 收录
下载链接:
https://lemurproject.org/clueweb22/
下载链接
链接失效反馈官方服务:
资源简介:
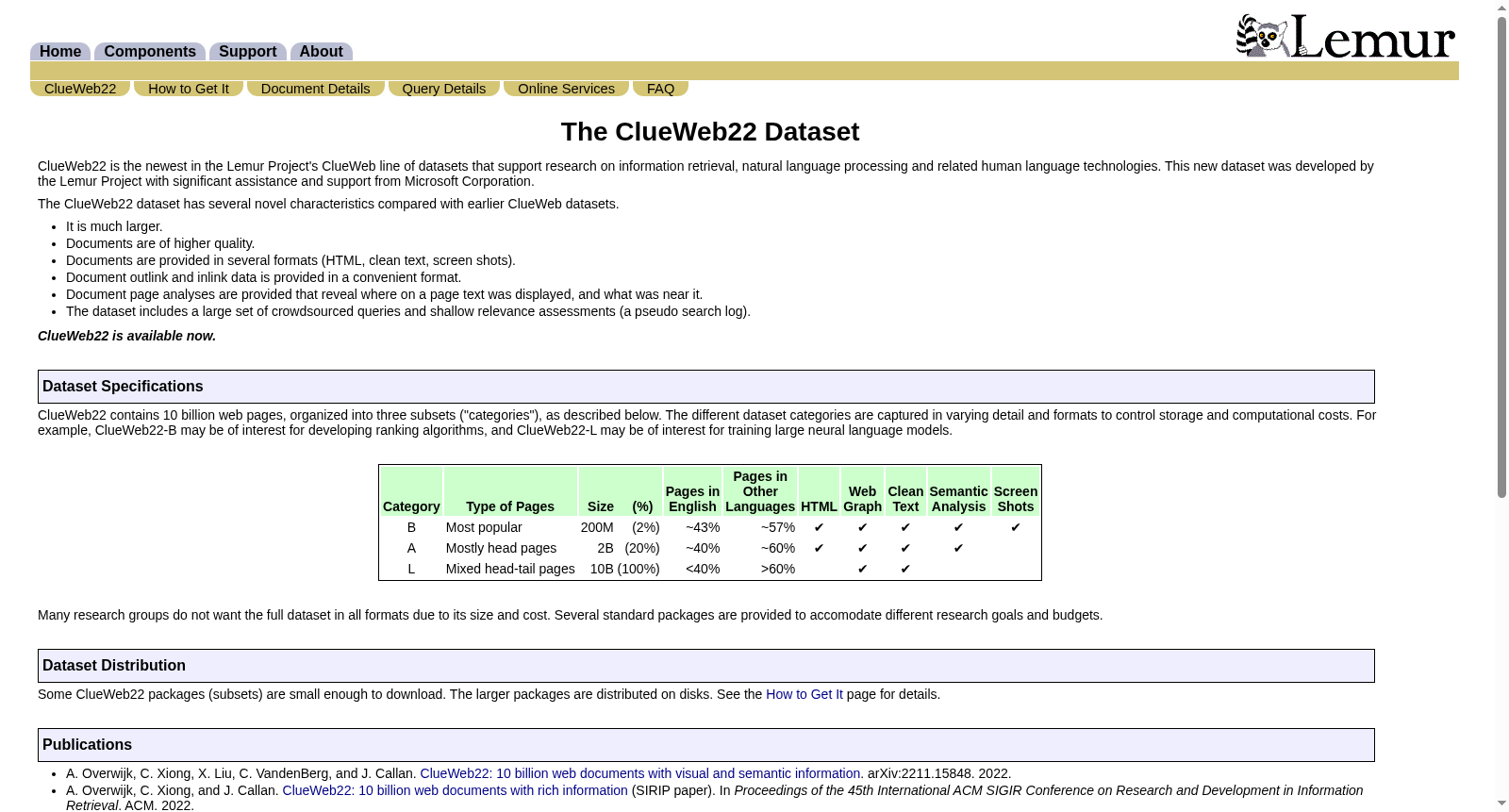
该数据集名为ClueWeb22,包含了100亿个文档,这些文档是从富含信息的网页中收集而来的。在其中的B类别中,RAGViz系统选用了8000万份英文文档,这些文档来源于访问频率最高的网页,用以测试RAGViz系统的演示。此外,该数据集的规模为8000万份文档,任务是对检索增强生成性能进行评估。
The dataset named ClueWeb22 consists of 10 billion documents collected from information-rich web pages. Within its Category B, the RAGViz system selected 80 million English documents sourced from the most frequently accessed web pages for demonstration testing of its own system. Additionally, this subset, comprising 80 million documents, is utilized to evaluate the performance of retrieval-augmented generation (RAG).
搜集汇总
数据集介绍
背景与挑战
背景概述
ClueWeb22是由Lemur Project与Microsoft合作开发的大规模网页数据集,包含100亿网页,分为三个子集(B、A、L),提供多种数据格式和丰富信息(如链接数据、语义分析等),特别适合信息检索和自然语言处理研究。
以上内容由遇见数据集搜集并总结生成


