有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
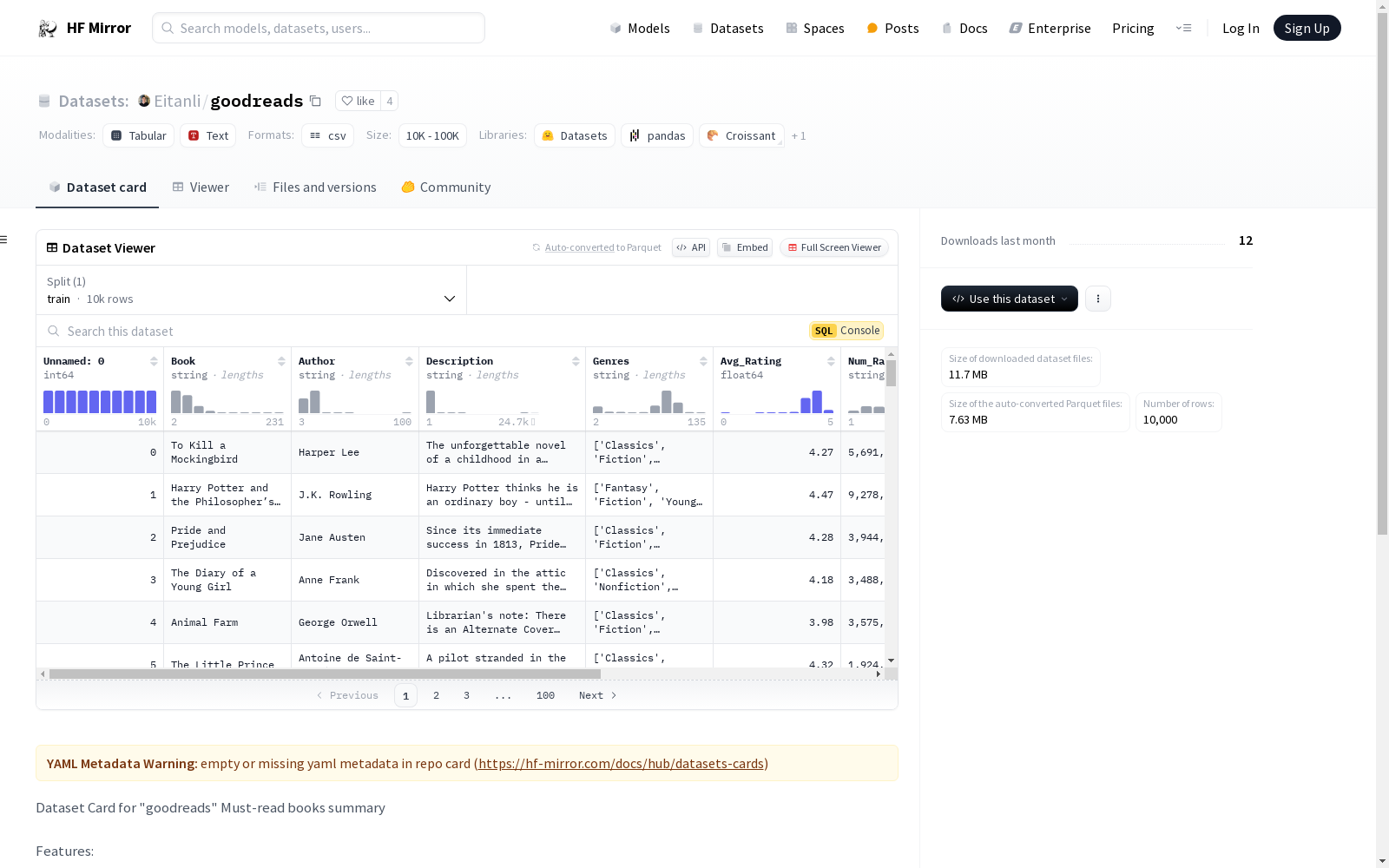
"goodreads"
Must-read books summary
Wind Turbine Data
该数据集包含风力涡轮机的运行数据,包括风速、风向、发电量等参数。数据记录了多个风力涡轮机在不同时间点的运行状态,适用于风能研究和风力发电系统的优化分析。
www.kaggle.com 收录
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录
MFE-ETP
MFE-ETP数据集由天津大学智能与计算学部创建,是一个针对具身任务规划的多模态基础模型综合评估基准。该数据集包含1184个高质量测试案例,覆盖100个具身任务,涉及对象理解、时空感知、任务理解和具身推理等多个能力维度。数据集的创建过程结合了从BEHAVIOR-100和VirtualHome平台收集的典型家庭任务数据,并通过人工标注和设计任务指令进行精细化处理。MFE-ETP数据集主要应用于提升多模态基础模型在具身人工智能领域的任务规划能力,旨在解决模型在复杂任务场景中的性能瓶颈问题。
arXiv 收录
ELSA
ELSA(English Longitudinal Study of Ageing)是一个纵向研究项目,旨在调查英国50岁及以上人群的健康、经济状况和社会关系。数据集包括参与者的健康状况、生活方式、经济状况、社会网络等多方面的信息。
www.elsa-project.ac.uk 收录
Wikipedia Dump
Wikipedia Dump 数据集包含了维基百科的完整内容,包括文章、页面、分类、模板等。数据以XML格式存储,每月更新一次。
dumps.wikimedia.org 收录