Eitanli/goodreads
收藏Hugging Face2023-05-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Eitanli/goodreads
下载链接
链接失效反馈官方服务:
资源简介:
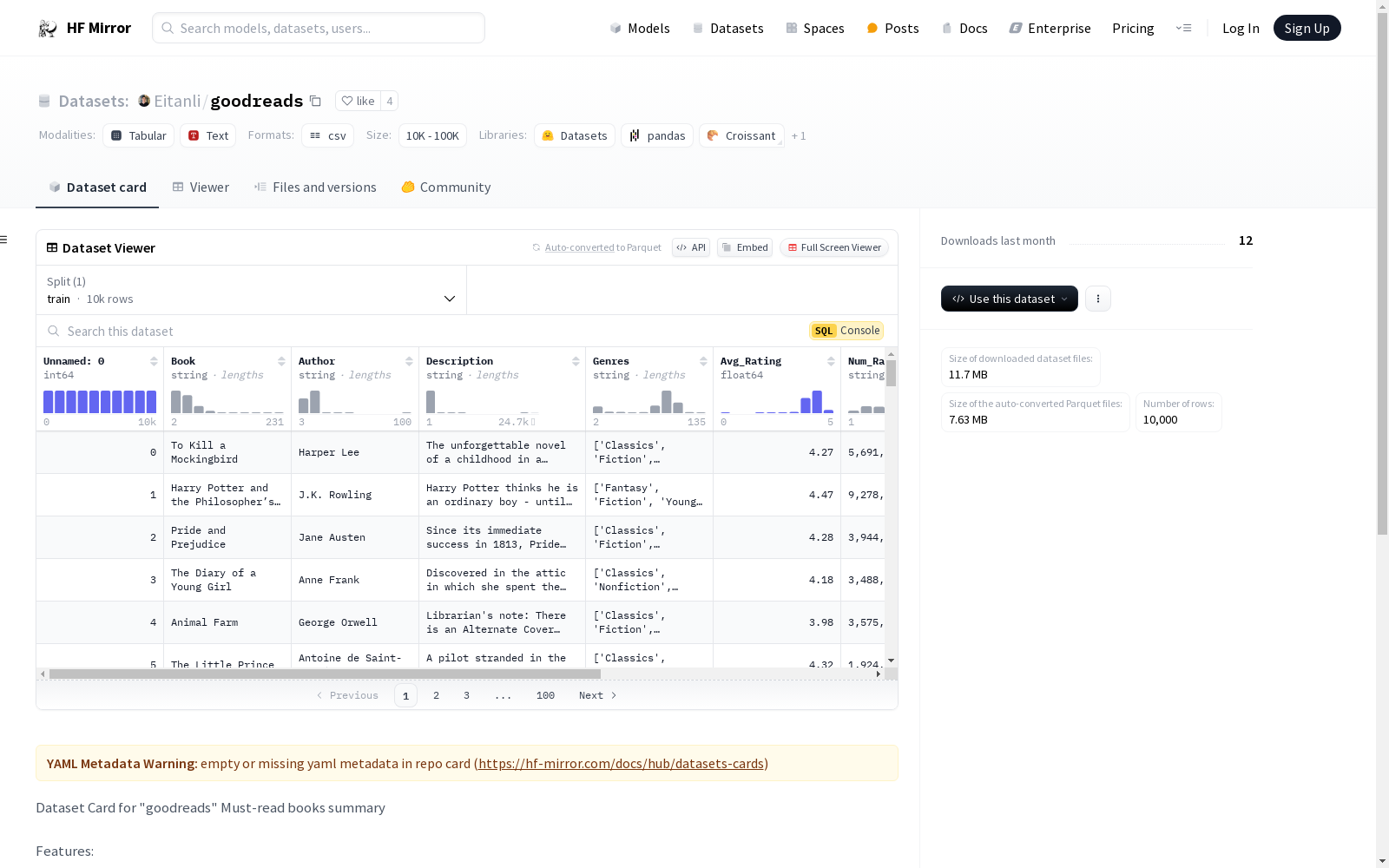
Dataset Card for "goodreads"
Must-read books summary
Features:
* Book - Name of the book. Soemtimes this includes the details of the Series it belongs to inside a parenthesis. This information can be further extracted to analyse only series.
* Author - Name of the book's Author
* Description - The book's description as mentioned on Goodreads
* Genres - Multiple Genres as classified on Goodreads. Could be useful for Multi-label classification or Content based recommendation and Clustering.
* Average Rating - The average rating (Out of 5) given on Goodreads
* Number of Ratings - The Number of users that have Ratings. (Not to be confused with reviews)
* URL - The Goodreads URL for the book's details' page
---
license: mit
---
## 「Goodreads」数据集卡片
### 必读书目概要
### 数据集特征
* **书籍名称**:部分书名会以括号形式标注其所属系列信息,可提取该字段以单独针对系列开展专项分析。
* **作者**:书籍作者的姓名。
* **图书简介**:Goodreads平台展示的书籍官方详情介绍。
* **书籍体裁**:Goodreads平台标注的多类体裁标签,可应用于多标签分类、基于内容的推荐系统构建及聚类任务。
* **平均评分**:Goodreads平台的5分制平均评分结果。
* **评分人次**:参与该书籍评分的用户总数,需注意与评论数量相区分。
* **详情页链接**:Goodreads平台对应书籍详情页的URL。
---
许可证:MIT许可证
---
提供机构:
Eitanli
原始信息汇总
数据集概述
数据集名称
"goodreads"
数据集主题
Must-read books summary
数据集特征
- Book - 书名,有时包含所属系列的详细信息。
- Author - 作者名。
- Description - 书籍描述,来自Goodreads。
- Genres - 多个分类的流派,适用于多标签分类、基于内容的推荐和聚类分析。
- Average Rating - 平均评分,满分5分。
- Number of Ratings - 评分用户数。
- URL - 书籍详细信息页面的Goodreads链接。
搜集汇总
数据集介绍
构建方式
该数据集通过从Goodreads平台采集书籍信息构建而成,涵盖了书籍名称、作者、描述、分类、平均评分、评分数量及书籍详情页的URL等关键特征。数据集的构建旨在为书籍推荐、分类及聚类分析提供丰富的数据支持,特别是针对多标签分类和基于内容的推荐系统。
特点
该数据集的显著特点在于其多维度的书籍信息,包括详细的书籍描述和多标签的分类信息,这为多标签分类和内容推荐提供了坚实的基础。此外,数据集还包含了书籍的平均评分和评分数量,这些数据对于评估书籍的受欢迎程度和进行用户行为分析具有重要价值。
使用方法
该数据集可广泛应用于书籍推荐系统、多标签分类模型以及内容聚类分析等领域。用户可以通过提取书籍的详细描述和分类信息,构建基于内容的推荐算法;同时,利用平均评分和评分数量数据,可以进行用户偏好分析和市场趋势预测。数据集的URL信息也为进一步的网络爬虫和数据扩展提供了可能。
背景与挑战
背景概述
在数字阅读日益普及的背景下,Eitanli/goodreads数据集应运而生,旨在为书籍推荐系统和多标签分类研究提供丰富的资源。该数据集由Eitanli创建,汇集了来自Goodreads平台的书籍信息,包括书名、作者、描述、分类、平均评分、评分数量及书籍详情页的URL。这些数据不仅为研究者提供了深入分析书籍内容和用户偏好的机会,还为构建高效的推荐算法和分类模型奠定了基础。通过该数据集,研究者能够探索书籍的多维度特征,从而推动个性化阅读推荐技术的发展。
当前挑战
尽管Eitanli/goodreads数据集为书籍推荐和分类研究提供了宝贵的资源,但其构建和应用过程中仍面临若干挑战。首先,数据集中书名的多样性可能导致系列书籍信息的提取和分类复杂化。其次,多标签分类的实现需要处理高维度的分类特征,这对算法的效率和准确性提出了较高要求。此外,用户评分的分布和质量可能影响平均评分的代表性,进而影响推荐系统的性能。最后,数据集的规模和更新频率也是确保其持续有效性的关键挑战。
常用场景
经典使用场景
在文学与数据科学的交汇处,Eitanli/goodreads数据集为研究者提供了一个丰富的资源,用于探索和分析书籍的多样性及其在读者中的影响。该数据集的经典使用场景包括多标签分类任务,其中书籍的多个类别标签被用于训练模型,以预测新书籍的潜在读者群体。此外,基于内容的推荐系统也是该数据集的一个重要应用,通过分析书籍描述和类别,系统能够为读者提供个性化的阅读建议。
衍生相关工作
Eitanli/goodreads数据集的发布激发了众多相关研究工作。例如,基于该数据集的书籍推荐系统研究不仅提升了推荐算法的性能,还推动了个性化推荐技术在其他领域的应用。此外,数据集中的多标签分类特性也启发了在其他领域(如电影和音乐推荐)中进行类似的多标签分类研究。研究者还利用该数据集进行书籍描述的自然语言处理研究,以提高文本分析和生成的准确性。这些衍生工作不仅丰富了数据科学的研究内容,也为实际应用提供了有力的技术支持。
数据集最近研究
最新研究方向
在图书推荐与文学分析领域,Eitanli/goodreads数据集因其丰富的图书元数据和用户评分信息,成为研究多标签分类、内容推荐及聚类分析的热点。该数据集不仅涵盖了图书的基本信息如书名、作者和描述,还提供了多维度的分类标签和用户评分数据,为研究者提供了深入探索用户偏好与图书内容之间关系的宝贵资源。近年来,基于此数据集的研究主要集中在开发更精准的推荐算法,以及通过多标签分类技术提升图书分类的准确性,这些研究成果对于优化图书推荐系统、提升用户体验具有重要意义。
以上内容由遇见数据集搜集并总结生成


