Open Materials 2024 (OMat24)
收藏arXiv2024-10-17 更新2024-10-18 收录
下载链接:
https://huggingface.co/datasets/fairchem/OMAT24
下载链接
链接失效反馈官方服务:
资源简介:
Open Materials 2024 (OMat24) 是由Meta的基础AI研究(FAIR)团队创建的一个大规模无机材料数据集,包含超过1.18亿个密度泛函理论(DFT)计算结果,专注于结构和组成的多样性。数据集通过多种非平衡结构生成方法(如Boltzmann采样、AIMD和结构弛豫)构建,旨在提高模型的非平衡和动态特性预测能力。OMat24数据集的应用领域广泛,包括新材料发现、催化剂设计、金属有机框架等,旨在通过AI加速材料科学的发展,解决新材料发现中的计算和实验挑战。
Open Materials 2024 (OMat24) is a large-scale inorganic materials dataset developed by Meta's Fundamental AI Research (FAIR) team. It contains over 118 million density functional theory (DFT) calculation results, with a focus on structural and compositional diversity. Constructed using multiple non-equilibrium structure generation approaches including Boltzmann sampling, AIMD, and structural relaxation, this dataset is designed to improve the predictive performance of models for non-equilibrium and dynamic material properties. The OMat24 dataset covers a wide range of application fields, such as novel material discovery, catalyst design, metal-organic frameworks (MOFs) and others. It aims to accelerate the development of materials science through AI, addressing computational and experimental challenges encountered in novel material discovery.
提供机构:
Meta的基础AI研究(FAIR)
创建时间:
2024-10-17
搜集汇总
数据集介绍
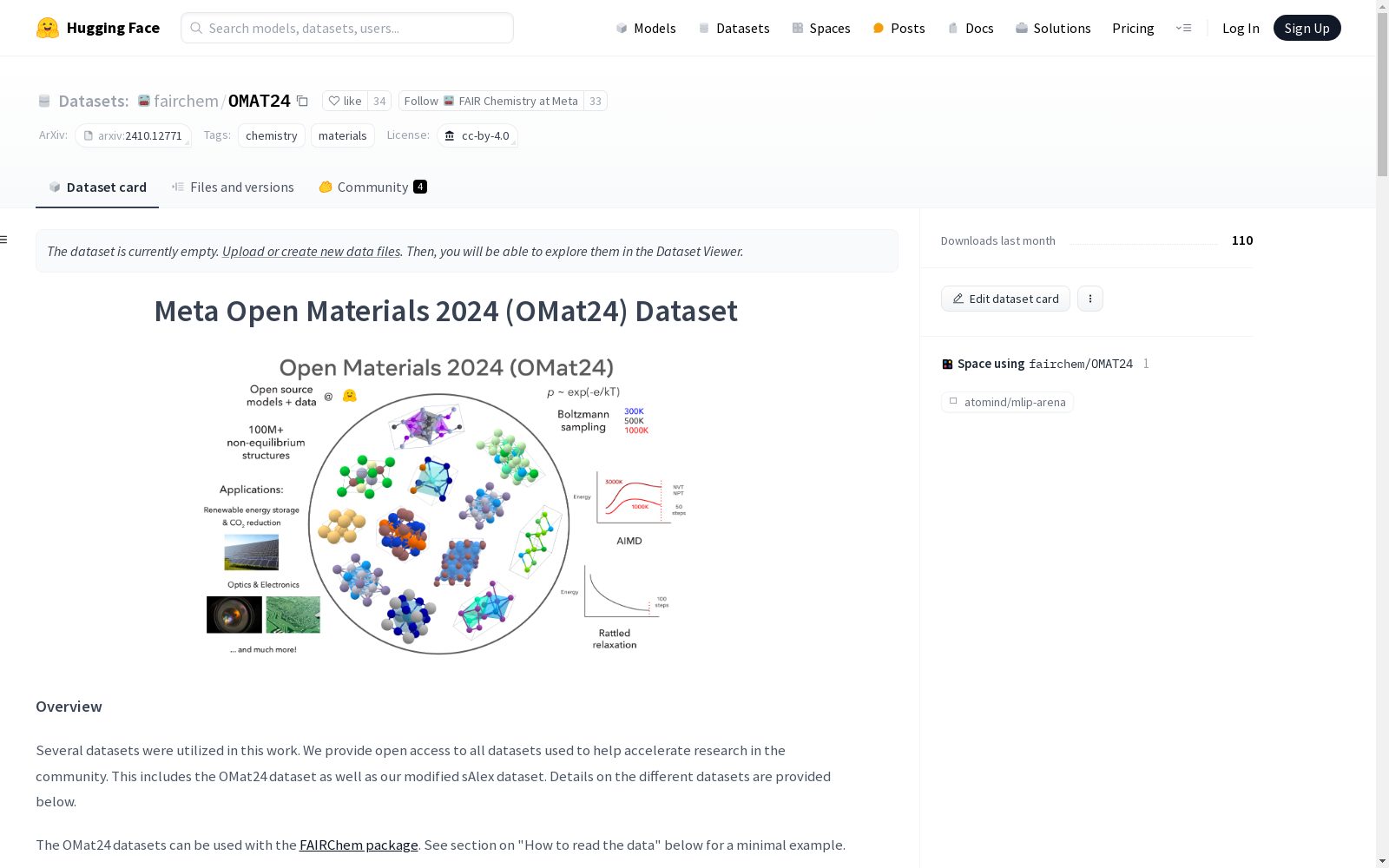
构建方式
OMat24数据集的构建基于大规模密度泛函理论(DFT)计算,涵盖了超过1.18亿个非平衡原子构型和元素组成的单点DFT计算。该数据集通过三种主要方法生成多样化的非平衡结构:Boltzmann采样振动的结构、从头算分子动力学(AIMD)以及振动结构的弛豫。这些方法确保了数据集在能量、力和应力分布上的广泛多样性,从而为训练远离平衡态的模型提供了丰富的数据资源。
特点
OMat24数据集的显著特点在于其巨大的规模和结构多样性,包含超过1.18亿个DFT计算结果,覆盖了从1到100个原子的广泛范围。此外,数据集在元素分布上几乎涵盖了整个周期表,特别强调了氧化物的代表性。这种广泛的元素和结构多样性使得OMat24成为训练和验证材料科学中机器学习模型的理想数据集。
使用方法
OMat24数据集主要用于训练和验证基于图神经网络(GNN)的机器学习模型,以预测材料的稳定性和形成能。研究者可以通过预训练和微调策略,利用OMat24数据集提升模型在Matbench Discovery基准测试中的表现。数据集的开放性和多样性也鼓励研究社区在此基础上进一步开发和优化AI辅助材料科学的新方法。
背景与挑战
背景概述
Open Materials 2024 (OMat24) 数据集由 Meta 的 Fundamental AI Research (FAIR) 团队于 2024 年发布,旨在解决材料科学领域中新型材料发现的关键问题。该数据集包含了超过 1.1 亿个密度泛函理论 (DFT) 计算,专注于无机材料的结构和成分多样性。OMat24 的发布填补了公开可用训练数据和预训练模型的空白,推动了人工智能在材料发现和设计中的应用。通过 EquiformerV2 模型,OMat24 在 Matbench Discovery 排行榜上取得了最先进的性能,能够以高精度预测基态稳定性和形成能。
当前挑战
OMat24 数据集在构建过程中面临多个挑战。首先,密度泛函理论 (DFT) 计算的计算成本极高,限制了其在探索新材料组合搜索空间中的应用。其次,现有的大多数数据集和训练模型仍为专有,这使得研究社区难以在此基础上进一步发展。此外,OMat24 数据集仅包含周期性体结构,未考虑点缺陷、表面、非化学计量和低维结构等重要效应。最后,数据集中的计算设置与 Materials Project 的 PBE 和 PBE+U 计算设置有所不同,这需要在分析或训练模型时特别注意。
常用场景
经典使用场景
在材料科学领域,Open Materials 2024 (OMat24) 数据集的经典应用场景主要集中在加速新材料的发现与设计。通过整合超过1亿次密度泛函理论(DFT)计算,OMat24为研究人员提供了一个大规模、多样化的数据集,用于训练和验证机器学习模型。这些模型能够预测材料的形成能和稳定性,从而在广泛的化学空间中筛选出具有潜在应用价值的材料。
实际应用
在实际应用中,OMat24数据集被广泛用于开发和优化新材料,特别是在可再生能源存储和碳中和燃料生产领域。例如,研究人员利用OMat24数据集训练的模型来筛选和设计高效的催化剂材料,这些材料在太阳能电池和燃料电池中具有重要应用。此外,OMat24还支持了直接空气捕获吸附剂的发现,这对于减少大气中的二氧化碳浓度具有重要意义。
衍生相关工作
OMat24数据集的发布催生了一系列相关研究工作,特别是在图神经网络(GNN)和机器学习势能面的开发方面。许多研究团队基于OMat24数据集开发了新的模型和算法,这些模型在Matbench Discovery等基准测试中表现出色。此外,OMat24还促进了跨学科的合作,吸引了来自计算机科学、物理学和化学等领域的研究人员共同推动材料科学的发展。
以上内容由遇见数据集搜集并总结生成


