AcademicEval/AcademicEval
收藏Hugging Face2024-06-15 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/AcademicEval/AcademicEval
下载链接
链接失效反馈官方服务:
资源简介:
AcademicEval是一个用于评估大语言模型在长文本生成任务中的表现的基准测试数据集,特别针对学术写作任务,如标题生成、摘要生成、引言生成和相关工作生成。数据集基于arXiv上的论文,提供了多种配置(如title_10K、abs_9K、intro_8K等),每个配置包含多个字段,如url、title、abstract、authors等。数据集的特点是自动标注、分层抽象、少样本演示和实时更新,且无需手动标注。
AcademicEval is a benchmark dataset designed to evaluate the performance of large language models (LLMs) in long-context generation tasks, particularly focusing on academic writing tasks such as title generation, abstract generation, introduction generation, and related work generation. The dataset is based on papers from arXiv and provides multiple configurations (e.g., title_10K, abs_9K, intro_8K, etc.), each containing various fields such as url, title, abstract, authors, etc. The dataset features automatic annotation, hierarchical abstraction, few-shot demonstrations, and live updates, all without the need for manual labeling.
提供机构:
AcademicEval
原始信息汇总
AcademicEval 数据集概述
基本信息
- 许可证: cc-by-4.0
- 任务类别:
- 总结
- 文本生成
- 语言: 英语
- 标签: croissant
- 数据量: 10K < n < 100K
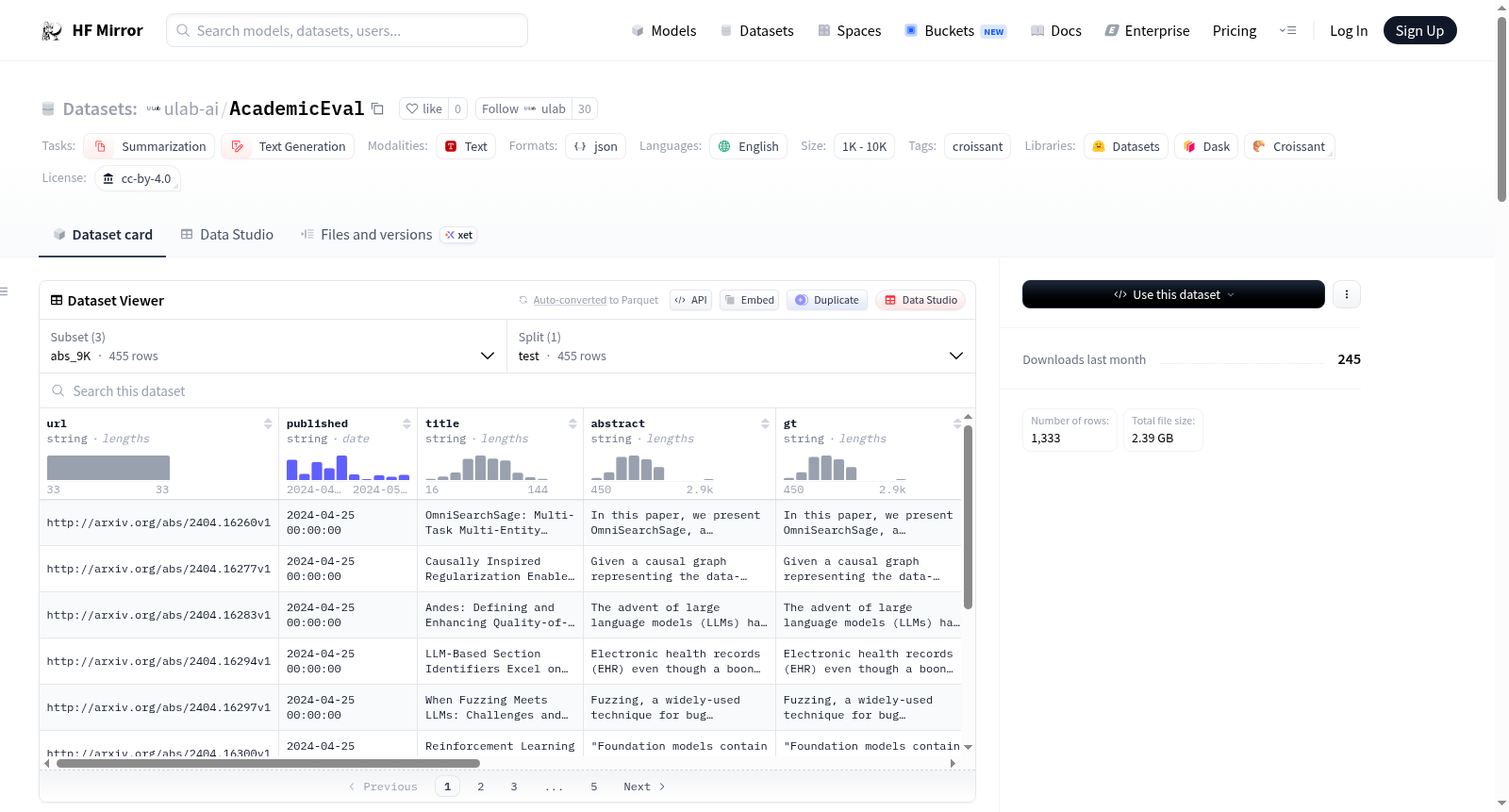
数据集配置
title_10K
- 特征:
- url: string
- published: string
- title: string
- abstract: string
- gt: string
- primary_cat: string
- paper_cat: string
- updated: string
- main_content: string
- authors: string
- label: string
- cats: sequence (string)
- 数据文件:
- split: test
- path: title_10K/test_*.json
abs_9K
- 特征:
- url: string
- published: string
- title: string
- abstract: string
- gt: string
- primary_cat: string
- paper_cat: string
- updated: string
- main_content: string
- authors: string
- label: string
- cats: sequence (string)
- 数据文件:
- split: test
- path: abs_9K/test_*.json
intro_8K
- 特征:
- url: string
- published: string
- title: string
- abstract: string
- gt: string
- primary_cat: string
- paper_cat: string
- updated: string
- main_content: string
- authors: string
- label: string
- cats: sequence (string)
- 数据文件:
- split: test
- path: intro_8K/test_*.json
数据字段
- url: 原始论文在 arXiv 上的 URL
- title: 论文标题
- abstract: 论文摘要
- authors: 论文作者
- published: 论文发表时间戳
- primary_cat: arXiv 分类
- gt: 对应任务的 ground truth
- main_content: 论文主体内容(不包括对应部分内容)
- additional_info: 随机选择的论文中的 few-shot 示例
- additional_graph_info: 带有合著者子图结构的 few-shot 示例
搜集汇总
数据集介绍
构建方式
在学术文本生成领域,构建高质量的数据集对于评估大语言模型的长上下文生成能力至关重要。AcademicEval数据集以arXiv平台上的学术论文为数据源,通过自动化流程提取论文的标题、摘要、引言及相关工作等核心部分,构建了涵盖不同抽象层次的生成任务。数据集的构建无需人工标注,利用论文自身的结构化内容作为真实标签,确保了数据的准确性与时效性。其灵活的长度设计允许模型处理从数千到数万词汇的文本,为长上下文生成任务提供了丰富的评估素材。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,利用其提供的测试集进行模型评估。数据集支持多种配置,如title_10K、abs_9K和intro_8K,用户可根据任务需求选择相应配置。使用过程中,模型以论文主体内容为输入,生成对应的标题、摘要或引言等部分,并通过与真实标签的对比进行性能度量。数据集还提供少样本演示,支持上下文学习,有助于深入探究模型在复杂学术语境下的生成效果与泛化能力。
背景与挑战
背景概述
在自然语言处理领域,长文本生成任务的评估一直是推动大语言模型发展的关键环节。AcademicEval数据集由ulab-ai等研究机构构建,旨在通过学术论文这一富含复杂语义和结构化信息的载体,为大语言模型在长上下文生成任务上的性能提供系统性评估基准。该数据集以arXiv平台的海量学术论文为源,精心设计了涵盖标题、摘要、引言及相关工作等多个学术写作维度的生成任务,其核心研究问题聚焦于如何精准评估模型在理解并生成具有不同抽象层级和逻辑深度的长文本内容方面的能力。自推出以来,AcademicEval凭借其自动标注、分层抽象和实时更新等特性,显著提升了长文本生成评估的效率和信度,为相关领域的研究提供了重要的数据支撑和比较基准。
当前挑战
AcademicEval数据集致力于解决学术长文本生成这一复杂领域问题的评估挑战,其核心在于如何设计能够全面衡量模型对冗长、专业且结构化学术内容进行理解和创造性生成的评估体系。在构建过程中,研究团队面临多重挑战:首先,从arXiv等开放平台大规模获取并清洗高质量学术论文数据,需确保数据的完整性、时效性及版权合规性;其次,为不同抽象层级的生成任务(如标题、摘要)自动构建高质量的真实标签,需克服学术文本语义密度高、结构多样所带来的标注一致性难题;再者,设计支持灵活上下文长度、分层抽象评估且能实时更新的基准框架,需在数据规模、任务复杂性和评估效率之间取得精巧平衡。这些挑战共同塑造了数据集的技术深度与应用价值。
常用场景
经典使用场景
在自然语言处理领域,长文本生成任务的评估一直是研究难点。AcademicEval数据集通过利用arXiv学术论文构建了标题、摘要、引言和相关工作等多个层次的写作任务,为大型语言模型在长上下文生成能力上的系统性评测提供了经典场景。该数据集以其灵活的输入长度和自动标注机制,成为衡量模型在学术文本生成中理解、概括和创造性表达能力的标准测试平台。
解决学术问题
该数据集有效解决了长上下文语言模型评估中缺乏层次化抽象任务和自动标注的学术研究问题。传统基准往往依赖人工标注,难以覆盖不同抽象级别且存在数据泄露风险。AcademicEval通过结构化提取论文不同章节,构建了从具体到抽象的连续评估谱系,为模型的长文本理解、信息压缩和连贯生成能力提供了可量化的分析框架,推动了长文本生成评估方法的标准化进程。
实际应用
在实际应用中,AcademicEval为学术写作辅助工具和智能文献处理系统的开发提供了关键训练与评估数据。基于该数据集训练的模型能够协助研究者自动生成论文标题、提炼摘要精华、撰写引言背景或归纳相关工作,显著提升学术生产效率。同时,其实时更新特性确保了评估与前沿学术发展同步,为教育出版和知识管理领域的智能化升级提供了可靠的技术支撑。
数据集最近研究
最新研究方向
在长文本生成模型评估领域,AcademicEval数据集正推动着前沿研究向自动化、层次化与动态化方向演进。该数据集基于arXiv学术论文构建,涵盖标题、摘要、引言及相关工作等多层次生成任务,其灵活的长度设计、自动标注机制与实时更新特性,为评估大语言模型在长上下文环境下的学术写作能力提供了新颖框架。近期研究热点聚焦于利用该数据集的层次化抽象任务,探索模型在不同信息密度要求下的生成一致性,并结合其提供的少样本示例,深入分析模型在复杂学术语境中的知识整合与结构推理能力。这一进展不仅响应了当前长上下文模型评估对标准化、可扩展基准的迫切需求,也为推动生成式人工智能在学术辅助写作等专业场景的可靠应用奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


