---
annotations_creators: []
language:
- en
- de
- fr
- es
- pl
- it
- ro
- hu
- cs
- nl
- fi
- hr
- sk
- sl
- et
- lt
language_creators: []
license:
- cc0-1.0
- other
multilinguality:
- multilingual
pretty_name: VoxPopuli
size_categories: []
source_datasets: []
tags: []
task_categories:
- automatic-speech-recognition
task_ids: []
---
# Dataset Card for Voxpopuli
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/facebookresearch/voxpopuli
- **Repository:** https://github.com/facebookresearch/voxpopuli
- **Paper:** https://arxiv.org/abs/2101.00390
- **Point of Contact:** [changhan@fb.com](mailto:changhan@fb.com), [mriviere@fb.com](mailto:mriviere@fb.com), [annl@fb.com](mailto:annl@fb.com)
### Dataset Summary
VoxPopuli is a large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation.
The raw data is collected from 2009-2020 [European Parliament event recordings](https://multimedia.europarl.europa.eu/en/home). We acknowledge the European Parliament for creating and sharing these materials.
This implementation contains transcribed speech data for 18 languages.
It also contains 29 hours of transcribed speech data of non-native English intended for research in ASR for accented speech (15 L2 accents)
### Example usage
VoxPopuli contains labelled data for 18 languages. To load a specific language pass its name as a config name:
```python
from datasets import load_dataset
voxpopuli_croatian = load_dataset("facebook/voxpopuli", "hr")
```
To load all the languages in a single dataset use "multilang" config name:
```python
voxpopuli_all = load_dataset("facebook/voxpopuli", "multilang")
```
To load a specific set of languages, use "multilang" config name and pass a list of required languages to `languages` parameter:
```python
voxpopuli_slavic = load_dataset("facebook/voxpopuli", "multilang", languages=["hr", "sk", "sl", "cs", "pl"])
```
To load accented English data, use "en_accented" config name:
```python
voxpopuli_accented = load_dataset("facebook/voxpopuli", "en_accented")
```
**Note that L2 English subset contains only `test` split.**
### Supported Tasks and Leaderboards
* automatic-speech-recognition: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER).
Accented English subset can also be used for research in ASR for accented speech (15 L2 accents)
### Languages
VoxPopuli contains labelled (transcribed) data for 18 languages:
| Language | Code | Transcribed Hours | Transcribed Speakers | Transcribed Tokens |
|:---:|:---:|:---:|:---:|:---:|
| English | En | 543 | 1313 | 4.8M |
| German | De | 282 | 531 | 2.3M |
| French | Fr | 211 | 534 | 2.1M |
| Spanish | Es | 166 | 305 | 1.6M |
| Polish | Pl | 111 | 282 | 802K |
| Italian | It | 91 | 306 | 757K |
| Romanian | Ro | 89 | 164 | 739K |
| Hungarian | Hu | 63 | 143 | 431K |
| Czech | Cs | 62 | 138 | 461K |
| Dutch | Nl | 53 | 221 | 488K |
| Finnish | Fi | 27 | 84 | 160K |
| Croatian | Hr | 43 | 83 | 337K |
| Slovak | Sk | 35 | 96 | 270K |
| Slovene | Sl | 10 | 45 | 76K |
| Estonian | Et | 3 | 29 | 18K |
| Lithuanian | Lt | 2 | 21 | 10K |
| Total | | 1791 | 4295 | 15M |
Accented speech transcribed data has 15 various L2 accents:
| Accent | Code | Transcribed Hours | Transcribed Speakers |
|:---:|:---:|:---:|:---:|
| Dutch | en_nl | 3.52 | 45 |
| German | en_de | 3.52 | 84 |
| Czech | en_cs | 3.30 | 26 |
| Polish | en_pl | 3.23 | 33 |
| French | en_fr | 2.56 | 27 |
| Hungarian | en_hu | 2.33 | 23 |
| Finnish | en_fi | 2.18 | 20 |
| Romanian | en_ro | 1.85 | 27 |
| Slovak | en_sk | 1.46 | 17 |
| Spanish | en_es | 1.42 | 18 |
| Italian | en_it | 1.11 | 15 |
| Estonian | en_et | 1.08 | 6 |
| Lithuanian | en_lt | 0.65 | 7 |
| Croatian | en_hr | 0.42 | 9 |
| Slovene | en_sl | 0.25 | 7 |
## Dataset Structure
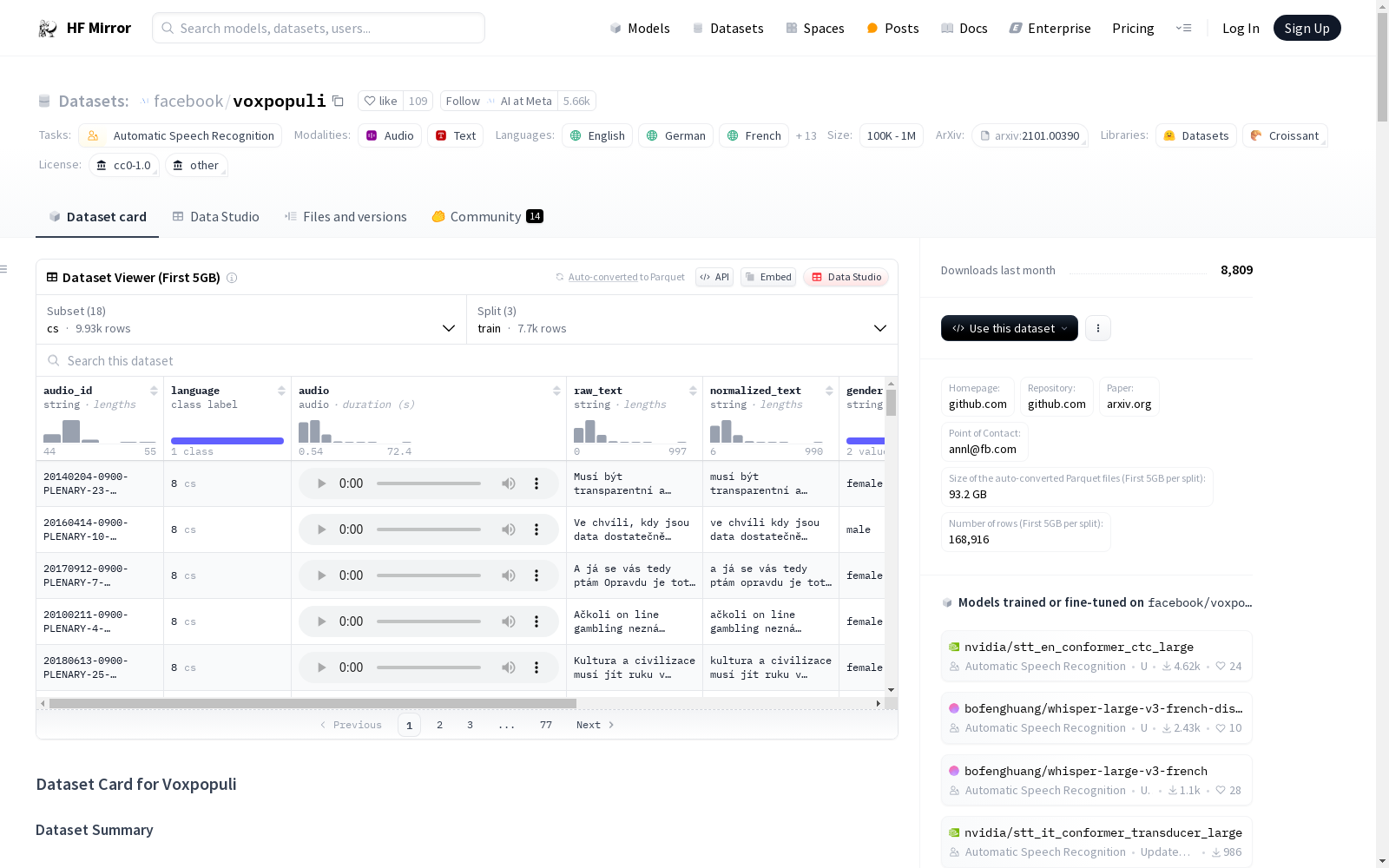
### Data Instances
```python
{
'audio_id': '20180206-0900-PLENARY-15-hr_20180206-16:10:06_5',
'language': 11, # "hr"
'audio': {
'path': '/home/polina/.cache/huggingface/datasets/downloads/extracted/44aedc80bb053f67f957a5f68e23509e9b181cc9e30c8030f110daaedf9c510e/train_part_0/20180206-0900-PLENARY-15-hr_20180206-16:10:06_5.wav',
'array': array([-0.01434326, -0.01055908, 0.00106812, ..., 0.00646973], dtype=float32),
'sampling_rate': 16000
},
'raw_text': '',
'normalized_text': 'poast genitalnog sakaenja ena u europi tek je jedna od manifestacija takve tetne politike.',
'gender': 'female',
'speaker_id': '119431',
'is_gold_transcript': True,
'accent': 'None'
}
```
### Data Fields
* `audio_id` (string) - id of audio segment
* `language` (datasets.ClassLabel) - numerical id of audio segment
* `audio` (datasets.Audio) - a dictionary containing the path to the audio, the decoded audio array, and the sampling rate. In non-streaming mode (default), the path points to the locally extracted audio. In streaming mode, the path is the relative path of an audio inside its archive (as files are not downloaded and extracted locally).
* `raw_text` (string) - original (orthographic) audio segment text
* `normalized_text` (string) - normalized audio segment transcription
* `gender` (string) - gender of speaker
* `speaker_id` (string) - id of speaker
* `is_gold_transcript` (bool) - ?
* `accent` (string) - type of accent, for example "en_lt", if applicable, else "None".
### Data Splits
All configs (languages) except for accented English contain data in three splits: train, validation and test. Accented English `en_accented` config contains only test split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
The raw data is collected from 2009-2020 [European Parliament event recordings](https://multimedia.europarl.europa.eu/en/home)
#### Initial Data Collection and Normalization
The VoxPopuli transcribed set comes from aligning the full-event source speech audio with the transcripts for plenary sessions. Official timestamps
are available for locating speeches by speaker in the full session, but they are frequently inaccurate, resulting in truncation of the speech or mixture
of fragments from the preceding or the succeeding speeches. To calibrate the original timestamps,
we perform speaker diarization (SD) on the full-session audio using pyannote.audio (Bredin et al.2020) and adopt the nearest SD timestamps (by L1 distance to the original ones) instead for segmentation.
Full-session audios are segmented into speech paragraphs by speaker, each of which has a transcript available.
The speech paragraphs have an average duration of 197 seconds, which leads to significant. We hence further segment these paragraphs into utterances with a
maximum duration of 20 seconds. We leverage speech recognition (ASR) systems to force-align speech paragraphs to the given transcripts.
The ASR systems are TDS models (Hannun et al., 2019) trained with ASG criterion (Collobert et al., 2016) on audio tracks from in-house deidentified video data.
The resulting utterance segments may have incorrect transcriptions due to incomplete raw transcripts or inaccurate ASR force-alignment.
We use the predictions from the same ASR systems as references and filter the candidate segments by a maximum threshold of 20% character error rate(CER).
#### Who are the source language producers?
Speakers are participants of the European Parliament events, many of them are EU officials.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
Gender speakers distribution is imbalanced, percentage of female speakers is mostly lower than 50% across languages, with the minimum of 15% for the Lithuanian language data.
VoxPopuli includes all available speeches from the 2009-2020 EP events without any selections on the topics or speakers.
The speech contents represent the standpoints of the speakers in the EP events, many of which are EU officials.
### Other Known Limitations
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The dataset is distributet under CC0 license, see also [European Parliament's legal notice](https://www.europarl.europa.eu/legal-notice/en/) for the raw data.
### Citation Information
Please cite this paper:
```bibtex
@inproceedings{wang-etal-2021-voxpopuli,
title = "{V}ox{P}opuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation",
author = "Wang, Changhan and
Riviere, Morgane and
Lee, Ann and
Wu, Anne and
Talnikar, Chaitanya and
Haziza, Daniel and
Williamson, Mary and
Pino, Juan and
Dupoux, Emmanuel",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.80",
pages = "993--1003",
}
```
### Contributions
Thanks to [@polinaeterna](https://github.com/polinaeterna) for adding this dataset.
annotations_creators: []
language:
- en
- de
- fr
- es
- pl
- it
- ro
- hu
- cs
- nl
- fi
- hr
- sk
- sl
- et
- lt
language_creators: []
license:
- cc0-1.0
- other
multilinguality:
- multilingual
pretty_name: VoxPopuli
size_categories: []
source_datasets: []
tags: []
task_categories:
- automatic-speech-recognition
task_ids: []
# VoxPopuli数据集卡片
## 目录
- [目录](#table-of-contents)
- [数据集描述](#dataset-description)
- [数据集概览](#dataset-summary)
- [支持的任务与排行榜](#supported-tasks-and-leaderboards)
- [语言覆盖](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [数据集构建依据](#curation-rationale)
- [源数据](#source-data)
- [标注](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏见讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献](#contributions)
## 数据集描述
- **主页**:https://github.com/facebookresearch/voxpopuli
- **代码仓库**:https://github.com/facebookresearch/voxpopuli
- **论文**:https://arxiv.org/abs/2101.00390
- **联系人**:[changhan@fb.com](mailto:changhan@fb.com), [mriviere@fb.com](mailto:mriviere@fb.com), [annl@fb.com](mailto:annl@fb.com)
### 数据集概览
VoxPopuli是一款大规模多语言语音语料库,可用于表征学习、半监督学习与语音语义解读。原始数据采集自2009年至2020年的**欧洲议会活动录音**(European Parliament event recordings),在此感谢欧洲议会制作并公开这些素材。本数据集包含18种语言的标注语音数据,此外还涵盖29小时的非母语英语标注语音数据,用于带口音语音自动语音识别(Automatic Speech Recognition, ASR)研究,覆盖15种第二语言口音。
### 示例用法
VoxPopuli包含18种语言的标注数据。若要加载特定语言的数据,可将该语言代码作为配置名称传入:
python
from datasets import load_dataset
voxpopuli_croatian = load_dataset("facebook/voxpopuli", "hr")
若要在单个数据集中加载所有语言的数据,可使用"multilang"配置名称:
python
voxpopuli_all = load_dataset("facebook/voxpopuli", "multilang")
若要加载特定语种集合的数据,可使用"multilang"配置名称,并将所需语言列表传入`languages`参数:
python
voxpopuli_slavic = load_dataset("facebook/voxpopuli", "multilang", languages=["hr", "sk", "sl", "cs", "pl"])
若要加载带口音英语数据,可使用"en_accented"配置名称:
python
voxpopuli_accented = load_dataset("facebook/voxpopuli", "en_accented")
**注意**:非母语英语子集仅包含`test`划分。
### 支持的任务与排行榜
* 自动语音识别(automatic-speech-recognition):本数据集可用于训练自动语音识别(Automatic Speech Recognition, ASR)模型。模型接收音频文件,并需将其转录为书面文本,最常用的评估指标为词错误率(Word Error Rate, WER)。
带口音英语子集还可用于带口音语音的ASR研究(涵盖15种第二语言口音)。
### 语言覆盖
VoxPopuli包含18种语言的标注(带转录)数据:
| 语言 | 代码 | 标注时长(小时) | 标注说话者数量 | 标注Token数 |
|:---:|:---:|:---:|:---:|:---:|
| 英语 | En | 543 | 1313 | 4.8M |
| 德语 | De | 282 | 531 | 2.3M |
| 法语 | Fr | 211 | 534 | 2.1M |
| 西班牙语 | Es | 166 | 305 | 1.6M |
| 波兰语 | Pl | 111 | 282 | 802K |
| 意大利语 | It | 91 | 306 | 757K |
| 罗马尼亚语 | Ro | 89 | 164 | 739K |
| 匈牙利语 | Hu | 63 | 143 | 431K |
| 捷克语 | Cs | 62 | 138 | 461K |
| 荷兰语 | Nl | 53 | 221 | 488K |
| 芬兰语 | Fi | 27 | 84 | 160K |
| 克罗地亚语 | Hr | 43 | 83 | 337K |
| 斯洛伐克语 | Sk | 35 | 96 | 270K |
| 斯洛文尼亚语 | Sl | 10 | 45 | 76K |
| 爱沙尼亚语 | Et | 3 | 29 | 18K |
| 立陶宛语 | Lt | 2 | 21 | 10K |
| 总计 | | 1791 | 4295 | 15M |
带口音语音标注数据包含15种不同的第二语言口音:
| 口音 | 代码 | 标注时长(小时) | 标注说话者数量 |
|:---:|:---:|:---:|:---:|
| 荷兰语口音英语 | en_nl | 3.52 | 45 |
| 德语口音英语 | en_de | 3.52 | 84 |
| 捷克语口音英语 | en_cs | 3.30 | 26 |
| 波兰语口音英语 | en_pl | 3.23 | 33 |
| 法语口音英语 | en_fr | 2.56 | 27 |
| 匈牙利语口音英语 | en_hu | 2.33 | 23 |
| 芬兰语口音英语 | en_fi | 2.18 | 20 |
| 罗马尼亚语口音英语 | en_ro | 1.85 | 27 |
| 斯洛伐克语口音英语 | en_sk | 1.46 | 17 |
| 西班牙语口音英语 | en_es | 1.42 | 18 |
| 意大利语口音英语 | en_it | 1.11 | 15 |
| 爱沙尼亚语口音英语 | en_et | 1.08 | 6 |
| 立陶宛语口音英语 | en_lt | 0.65 | 7 |
| 克罗地亚语口音英语 | en_hr | 0.42 | 9 |
| 斯洛文尼亚语口音英语 | en_sl | 0.25 | 7 |
## 数据集结构
### 数据实例
python
{
'audio_id': '20180206-0900-PLENARY-15-hr_20180206-16:10:06_5',
'language': 11, # "hr"
'audio': {
'path': '/home/polina/.cache/huggingface/datasets/downloads/extracted/44aedc80bb053f67f957a5f68e23509e9b181cc9e30c8030f110daaedf9c510e/train_part_0/20180206-0900-PLENARY-15-hr_20180206-16:10:06_5.wav',
'array': array([-0.01434326, -0.01055908, 0.00106812, ..., 0.00646973], dtype=float32),
'sampling_rate': 16000
},
'raw_text': '',
'normalized_text': 'poast genitalnog sakaenja ena u europi tek je jedna od manifestacija takve tetne politike.',
'gender': 'female',
'speaker_id': '119431',
'is_gold_transcript': True,
'accent': 'None'
}
### 数据字段
* `audio_id`(字符串类型):音频片段的唯一标识符
* `language`(datasets.ClassLabel类型):音频片段的数字编号
* `audio`(datasets.Audio类型):包含音频路径、解码后的音频数组与采样率的字典。在非流式模式(默认模式)下,路径指向本地已提取的音频文件;在流式模式下,路径为音频在归档文件内的相对路径(因文件未在本地下载和解压)。
* `raw_text`(字符串类型):音频片段的原始正字法文本
* `normalized_text`(字符串类型):音频片段转录结果的标准化文本
* `gender`(字符串类型):说话者的性别
* `speaker_id`(字符串类型):说话者的唯一标识符
* `is_gold_transcript`(布尔类型):是否为标准转录文本
* `accent`(字符串类型):口音类型,例如`en_lt`,若不适用则为`None`。
### 数据划分
除带口音英语配置外,所有语言配置均包含训练(train)、验证(validation)与测试(test)三个划分;带口音英语的`en_accented`配置仅包含测试划分。
## 数据集构建
### 数据集构建依据
[需补充更多信息]
### 源数据
原始数据采集自2009年至2020年的欧洲议会活动录音。
#### 初始数据采集与标准化
VoxPopuli的标注数据集通过将完整活动的源语音音频与全体会议的转录文本对齐得到。官方时间戳可用于在完整会话中定位说话者的发言,但时常不准确,导致发言被截断或混入前后发言的片段。为校准原始时间戳,我们使用pyannote.audio(Bredin等人,2020)对完整会话音频进行说话人diarization(Speaker Diarization),并采用与原始时间戳L1距离最近的diarization时间戳来进行分段。完整会话音频被按说话人分割为多个发言段落,每个段落均配有对应转录文本。
这些发言段落的平均时长为197秒,过长的段落会带来处理难度,因此我们进一步将其分割为最大时长不超过20秒的话语片段。我们借助自动语音识别(ASR)系统将发言段落强制对齐至给定的转录文本。所用ASR系统为基于ASG准则(Collobert等人,2016)训练的TDS模型(Hannun等人,2019),训练数据来自内部的去标识化视频音频数据。
由于原始转录文本不完整或ASR强制对齐不准确,生成的话语片段可能存在错误转录。我们使用相同ASR系统的预测结果作为参考,以字符错误率(Character Error Rate, CER)不超过20%为阈值过滤候选片段。
#### 源语言产出者是谁?
说话者为欧洲议会活动的参与者,其中多数为欧盟官员。
### 标注
#### 标注流程
[需补充更多信息]
#### 标注人员
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏见讨论
说话者性别分布不均衡:多数语言的女性说话者占比低于50%,立陶宛语数据的女性占比最低,仅为15%。
VoxPopuli收录了2009年至2020年欧洲议会活动中所有可用的发言,未对主题或说话者进行任何筛选。发言内容代表了欧洲议会活动中说话者的立场,其中多数为欧盟官员。
### 其他已知局限性
## 附加信息
### 数据集维护者
[需补充更多信息]
### 许可证信息
本数据集采用CC0许可证发布,原始数据的相关说明请参阅[欧洲议会法律声明](https://www.europarl.europa.eu/legal-notice/en/)。
### 引用信息
请引用以下论文:
bibtex
@inproceedings{wang-etal-2021-voxpopuli,
title = "{V}ox{P}opuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation",
author = "Wang, Changhan and
Riviere, Morgane and
Lee, Ann and
Wu, Anne and
Talnikar, Chaitanya and
Haziza, Daniel and
Williamson, Mary and
Pino, Juan and
Dupoux, Emmanuel",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.80",
pages = "993--1003",
}
### 贡献
感谢[@polinaeterna](https://github.com/polinaeterna)添加本数据集。