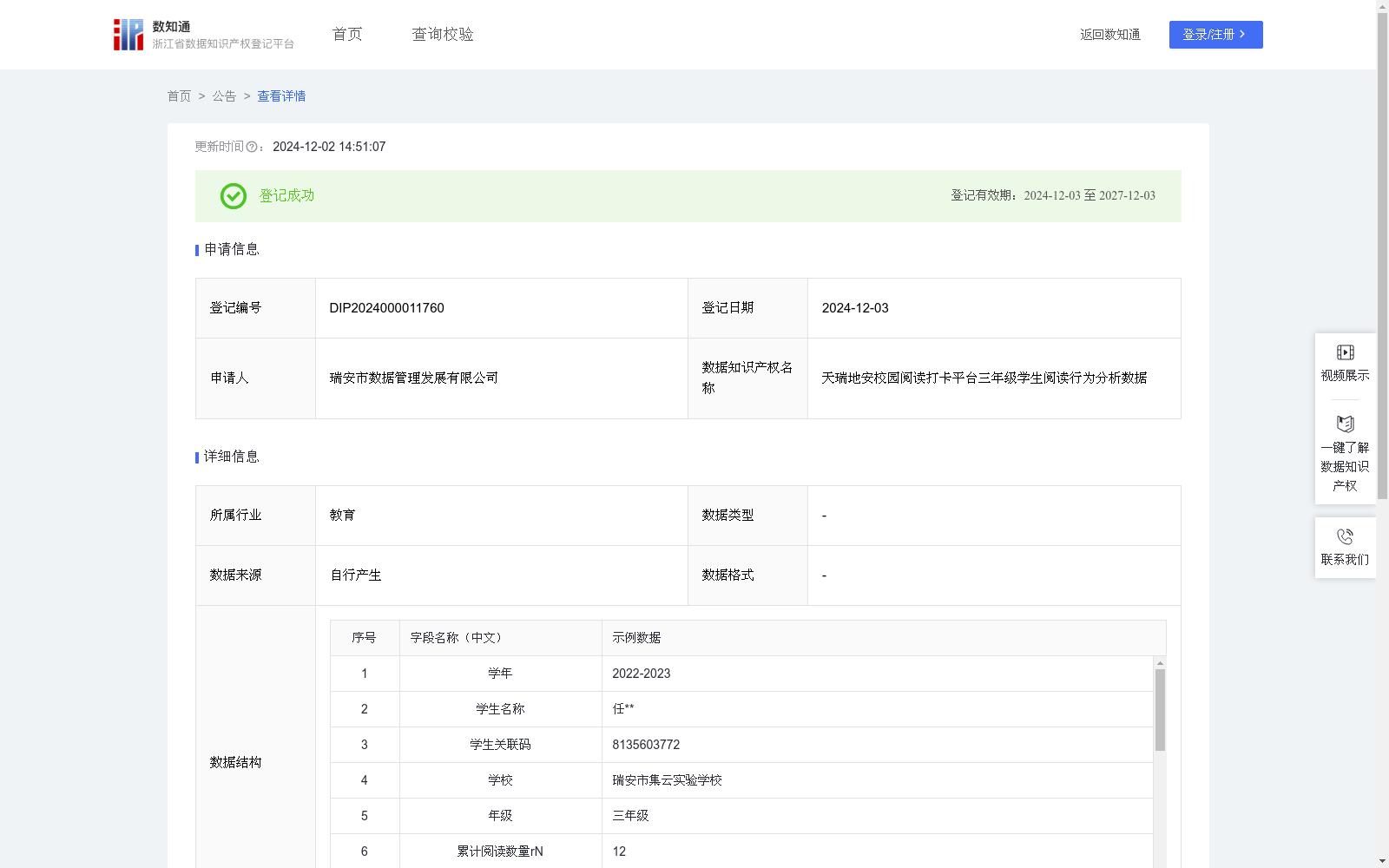
天瑞地安校园阅读打卡平台三年级学生阅读行为分析数据
收藏浙江省数据知识产权登记平台2024-12-02 更新2024-12-03 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/92356
下载链接
链接失效反馈官方服务:
资源简介:
对天瑞地安APP校园阅读打卡平台上各年级段学生的阅读数据进行统计分析,对同一年级的学生数据做聚类分析,将学生的阅读情况进行迭代聚类,可以识别不同学生的阅读效果,可以使老师们了解到学生的阅读情况,从而实现更加精细化的学生管理,提升老师们的教学质量。同时,分析数据可以与书目类型数据结合,更有针对性的了解各年级段学生各类型书目的阅读情况,进而实现营销转化。数据采集:通过学生用户在天瑞地安APP上的阅读打卡行为,采集阅读过程中的时间、书目等数据;数据处理:在融媒综合管理平台上,通过机器学习分析学生阅读打卡的时间、书目、时长等数据,基于整体的打卡数据进行活跃度权重建模,将权重低于0.1的用户进行清洗;算法规则:将用户的累计阅读数量(变量1)、累计阅读时长(变量2)与累计阅读天数(变量3)进行归一化处理(减少极值数据对分析的影响),对归一化后的数据进行因子分析,将数据聚合为两个独立的公共因子(因子1反映变量1与变量2的信息,因子2反映变量3的信息),通过聚类分析(K-means算法)进行迭代分析产生三个聚类的中点(中心A、B、C),根据聚类迭代结果确定用户的聚类类型(Ad最小为类型A,Bd最小为类型B,Cd最小为类型C)与阅读等级标签(类型A、B、C分别对应低等级、中等级、高等级)。
This work conducts statistical analysis on the reading data of students across all grade levels on the Tianruidi'an APP campus reading check-in platform. Cluster analysis is performed on student data from the same grade, and iterative clustering of students' reading status is carried out to identify the reading performance of different students. This enables teachers to gain a clear understanding of students' reading situations, thereby achieving more refined student management and improving teaching quality.
Additionally, integrating the analyzed data with book genre data allows for more targeted insights into the reading status of students across different grade levels for various book types, further enabling marketing conversion.
Data Collection: Data including reading timestamps and book titles are collected through the reading check-in behaviors of student users on the Tianruidi'an APP during their reading processes.
Data Processing: On the Integrated Media Management Platform, machine learning is used to analyze data such as students' reading check-in timestamps, book titles, and reading durations. Activity weight modeling is conducted based on overall check-in data, and users with a weight lower than 0.1 are filtered out.
Algorithm Specifications: First, normalization processing is applied to three variables: the cumulative number of books read (Variable 1), cumulative reading duration (Variable 2), and cumulative reading days (Variable 3) — this mitigates the impact of extreme values on the analysis. Factor analysis is then performed on the normalized data to aggregate the data into two independent common factors: Factor 1 reflects the information of Variable 1 and Variable 2, while Factor 2 reflects the information of Variable 3. Iterative cluster analysis using the K-means algorithm generates three cluster centroids (Centroid A, B, C). Based on the iterative clustering results, the cluster type of each user is determined: users with the smallest distance to Centroid A belong to Type A, those with the smallest distance to Centroid B belong to Type B, and those with the smallest distance to Centroid C belong to Type C. Corresponding reading level tags are assigned: Type A, B, and C correspond to low, medium, and high reading levels, respectively.
提供机构:
瑞安市数据管理发展有限公司
创建时间:
2024-10-17
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


