AtharvImmverse/IndicVisionBench
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/AtharvImmverse/IndicVisionBench
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: mmt
features:
- name: id
dtype: string
- name: image
dtype: image
- name: topic
dtype: string
- name: State/UT
dtype: string
- name: English
dtype: string
- name: Hindi
dtype: string
- name: Bengali
dtype: string
- name: Gujarati
dtype: string
- name: Kannada
dtype: string
- name: Malayalam
dtype: string
- name: Marathi
dtype: string
- name: Odia
dtype: string
- name: Punjabi
dtype: string
- name: Tamil
dtype: string
- name: Telugu
dtype: string
- name: source_url
dtype: string
splits:
- name: test
num_bytes: 14424797
num_examples: 106
download_size: 13255747
dataset_size: 14424797
- config_name: ocr
features:
- name: id
dtype: string
- name: image
dtype: image
- name: text
dtype: string
- name: language
dtype: string
- name: page_url
dtype: string
splits:
- name: test
num_bytes: 614014454
num_examples: 876
download_size: 612223184
dataset_size: 614014454
- config_name: vqa_en
features:
- name: id
dtype: string
- name: image
dtype: image
- name: topic
dtype: string
- name: State/UT
dtype: string
- name: language
dtype: string
- name: short_q1
dtype: string
- name: short_a1
dtype: string
- name: short_q2
dtype: string
- name: short_a2
dtype: string
- name: mcq
dtype: string
- name: mcq_a
dtype: string
- name: mcq_opt1
dtype: string
- name: mcq_opt2
dtype: string
- name: mcq_opt3
dtype: string
- name: mcq_opt4
dtype: string
- name: true_false_q
dtype: string
- name: true_false_a
dtype: string
- name: long_q
dtype: string
- name: long_a
dtype: string
- name: adversarial_question
dtype: string
- name: adversarial_answer
dtype: string
- name: source_url
dtype: string
splits:
- name: test
num_bytes: 1131332865
num_examples: 4117
download_size: 1127187152
dataset_size: 1131332865
- config_name: vqa_indic
features:
- name: id
dtype: string
- name: image
dtype: image
- name: topic
dtype: string
- name: State/UT
dtype: string
- name: language
dtype: string
- name: short_q1
dtype: string
- name: short_a1
dtype: string
- name: short_q2
dtype: string
- name: short_a2
dtype: string
- name: mcq
dtype: string
- name: mcq_a
dtype: string
- name: mcq_opt1
dtype: string
- name: mcq_opt2
dtype: string
- name: mcq_opt3
dtype: string
- name: mcq_opt4
dtype: string
- name: true_false_q
dtype: string
- name: true_false_a
dtype: string
- name: long_q
dtype: string
- name: long_a
dtype: string
- name: adversarial_question
dtype: string
- name: adversarial_answer
dtype: string
- name: source_url
dtype: string
splits:
- name: test
num_bytes: 276711951
num_examples: 1007
download_size: 273419974
dataset_size: 276711951
- config_name: vqa_parallel
features:
- name: id
dtype: string
- name: image
dtype: image
- name: topic
dtype: string
- name: State/UT
dtype: string
- name: language
dtype: string
- name: short_q1
dtype: string
- name: short_a1
dtype: string
- name: short_q2
dtype: string
- name: short_a2
dtype: string
- name: mcq
dtype: string
- name: mcq_a
dtype: string
- name: mcq_opt1
dtype: string
- name: mcq_opt2
dtype: string
- name: mcq_opt3
dtype: string
- name: mcq_opt4
dtype: string
- name: true_false_q
dtype: string
- name: true_false_a
dtype: string
- name: long_q
dtype: string
- name: long_a
dtype: string
- name: adversarial_question
dtype: string
- name: adversarial_answer
dtype: string
- name: source_url
dtype: string
splits:
- name: test
num_bytes: 324650384
num_examples: 1166
download_size: 321701661
dataset_size: 324650384
configs:
- config_name: mmt
data_files:
- split: test
path: mmt/test-*
- config_name: ocr
data_files:
- split: test
path: ocr/test-*
- config_name: vqa_en
data_files:
- split: test
path: vqa_en/test-*
- config_name: vqa_indic
data_files:
- split: test
path: vqa_indic/test-*
- config_name: vqa_parallel
data_files:
- split: test
path: vqa_parallel/test-*
task_categories:
- visual-question-answering
language:
- en
- hi
- ta
- te
- ml
- mr
- gu
- pa
- or
- kn
- bn
tags:
- vision
- ocr
- vqa
- indic
- benchmark
- cultural
- mmt
- multimodal
size_categories:
- 10K<n<100K
---
# IndicVisionBench
[](https://openreview.net/forum?id=LmJoLn04iL)
[](https://arxiv.org/abs/2511.04727)
[](https://github.com/ola-krutrim/IndicVisionBench)
This repository contains the dataset for **IndicVisionBench**, introduced in
**“IndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs”**
📄 [arXiv:2511.04727](https://arxiv.org/abs/2511.04727)
🏛️ Accepted at **ICLR 2026**
🔗 OpenReview: https://openreview.net/forum?id=LmJoLn04iL
IndicVisionBench is a **culturally grounded, multilingual vision-language benchmark** designed to evaluate Vision–Language Models (VLMs) on visual understanding tasks in the Indian context. The benchmark focuses on:
- Multilingual Visual Question Answering (VQA)
- Culturally-aware reasoning
- Adversarial robustness
- Parallel cross-lingual consistency
- Optical Character Recognition (OCR) in Indic scripts
- Multimodal Machine Translation (MMT)
Unlike generic VQA datasets, IndicVisionBench emphasizes **Indian cultural context, regional diversity, and Indic language coverage**, enabling systematic evaluation of multilingual and culturally-aware VLMs.
---
## Languages Covered
- English
- Hindi
- Tamil
- Telugu
- Malayalam
- Marathi
- Gujarati
- Punjabi
- Odia
- Kannada
- Bengali
---
## Benchmark Overview
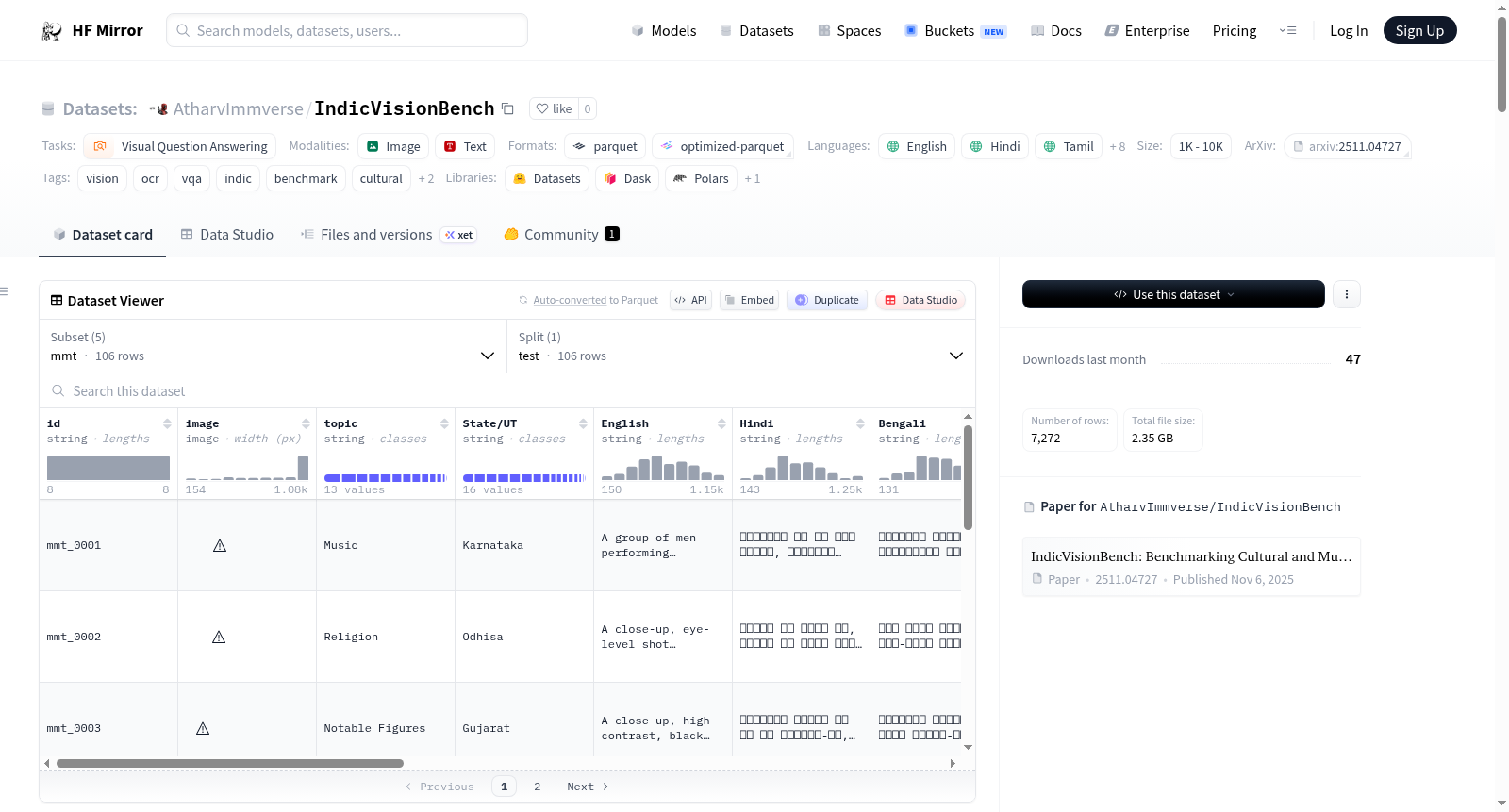
IndicVisionBench consists of five main configurations:
| Config | Task | #Images | Description |
|--------|------|-----------|-------------|
| `mmt` | Multimodal Machine Translation | 106 | Image-grounded translations across Indic languages |
| `ocr` | Optical Character Recognition | 876 | OCR in multiple Indic scripts |
| `vqa_en` | Visual Question Answering | 4,117 | Culturally grounded VQA in English |
| `vqa_indic` | Visual Question Answering | 1,007 | Culturally grounded VQA in Indic languages |
| `vqa_parallel` | Visual Question Answering | 1,166 | Same QA pairs across multiple languages for cross-lingual consistency |
- **Total images across all configs:** 4993
- **Total questions across VQA En, Indic and Parallel:** (4117 + 1007 + 1166)*6 = 37,740
---
## Subset Descriptions
### 1️⃣ Multimodal Machine Translation (`mmt`)
Image-grounded translation benchmark with aligned captions across multiple Indic languages.
**Features:**
- `image`
- `topic`
- `State/UT`
- Parallel captions in 11 languages
- `source_url`
This subset evaluates:
- Cultural terminology consistency
- Visual grounding in translation
### 2️⃣ Optical Character Recognition (`ocr`)
OCR dataset consisting of scanned pages in Indic scripts from Wikisource.
**Features:**
- `image`
- `text`
- `language`
- `page_url`
This subset evaluates OCR capabitilies on Indic scripts/languages.
### 3️⃣ English VQA (`vqa_en`)
Culturally grounded VQA in English.
Each example includes:
- 2 short-answer questions
- 1 multiple-choice question (4 options)
- 1 true/false question
- 1 long-form reasoning question
- 1 adversarial question
- Metadata: `topic`, `language`, `State/UT`, 'source_url'
This subset evaluates:
- Object & scene understanding
- Cultural knowledge
- Fine-grained attribute recognition
- Robustness to false assumptions in the adversarial questions
### 4️⃣ Indic VQA (`vqa_indic`)
Same VQA format as in `vqa_en`, but in Indic languages.
This subset evaluates:
- Multilingual reasoning
- Cultural alignment in local languages
### 5️⃣ Parallel VQA (`vqa_parallel`)
Same VQA format as in `vqa_en`. Parallel multilingual QA pairs for the same image.
This subset enables the study of
- cross-lingual performance of VLMs across 11 languages (English and 10 Indic languages)
- region-specific strengths or biases
## Usage
All configurations can be loaded using `datasets`:
```python
from datasets import load_dataset
# Example: load English VQA split
ds = load_dataset("krutrim-ai-labs/IndicVisionBench", "vqa_en")["test"]
print(ds[0])
```
The following five configurations/splits are present in the dataset:
- mmt
- ocr
- vqa_en
- vqa_indic
- vqa_parallel
Images are stored directly within the dataset and loaded automatically by 🤗 Datasets.
## Evaluation Dimensions
IndicVisionBench is designed to measure:
- Scene & contextual understanding
- Attribute detection
- Cultural understanding
- Bias & adversarial robustness
- Cross-lingual consistency
- OCR performance
- Image-grounded translation capability
## Code & Evaluation
The official inference and evaluation codebase for IndicVisionBench is available on GitHub.
**GitHub Repository:**
[https://github.com/ola-krutrim/IndicVisionBench](https://github.com/ola-krutrim/IndicVisionBench)
The repository provides the complete pipeline for running inference and reproducing benchmark results across all evaluation tracks.
The codebase includes:
- End-to-end inference pipelines for **Vision-Language Models (VLMs)** and **OCR systems**
- Modular wrappers enabling easy integration of **API-based models** and **open-source models**
- Evaluation pipelines for all benchmark tasks:
- **OCR evaluation**
- **Visual Question Answering (VQA)**
- Structured questions (MCQ, True/False)
- Open-ended questions (short answer, long answer, adversarial)
- **Multimodal Machine Translation (MMT)**
- **LLM-as-a-judge evaluation** for open-ended VQA responses
- Data generation scripts for constructing a similar multimodal benchmark.
### Citation
If you use this dataset, please cite:
```bibtex
@inproceedings{faraz2026indicvisionbench,
title={IndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs},
author={Ali Faraz and Akash and Shaharukh Khan and Raja Kolla and Akshat Patidar and Suranjan Goswami and Abhinav Ravi and Chandra Khatri and Shubham Agarwal},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026},
url={https://openreview.net/forum?id=LmJoLn04iL}
}
```
提供机构:
AtharvImmverse
搜集汇总
数据集介绍
构建方式
IndicVisionBench由Krutrim AI Labs构建,旨在系统评估视觉语言模型在印度文化背景下的多语言理解能力。该数据集包含五个核心配置:多模态机器翻译(mmt)、光学字符识别(ocr)、英语视觉问答(vqa_en)、印度语言视觉问答(vqa_indic)和平行视觉问答(vqa_parallel)。这些配置从印度各邦的公共资源及维基文库中采集图像,并针对每张图像人工标注了涵盖多种印度语言的文本描述、问答对及OCR转录内容。其中,VQA部分设计了短答案、多项选择、是非题、长答案及对抗性问题等多种题型,以确保评估的全面性和挑战性。数据集的构建过程高度注重区域多样性、文化术语一致性以及跨语言对齐,最终形成了总计4993张图像、超过37000个问答对的基准测试集合。
特点
IndicVisionBench的核心特点在于其深度扎根于印度文化语境,并覆盖英语及十种主要印度语言,包括印地语、泰米尔语、孟加拉语等。该数据集不仅考察视觉识别能力,更强调场景理解、文化知识、属性精细化识别、对抗性鲁棒性以及跨语言一致性。其VQA部分整合了多种问题类型,能够从多维度评估模型的理解深度,而平行VQA配置则专门用于研究模型在不同语言间的性能差异与区域偏好。此外,mmt和ocr配置分别聚焦于图像引导的翻译能力和印度文字的OCR识别,赋予了基准多模态、多任务的评估广度,使其成为衡量视觉语言模型在非西方语境中表现的重要工具。
使用方法
研究人员可通过Hugging Face的datasets库便捷加载IndicVisionBench,使用如load_dataset('krutrim-ai-labs/IndicVisionBench', 'vqa_en')['test']的命令即可获取指定配置的测试集。数据集中的图像已内嵌存储,加载时会自动处理。对于评估,官方GitHub仓库提供了完整的推理与评分管线,支持视觉语言模型和OCR系统的集成。其中,开放式VQA回答采用LLM-as-a-judge策略进行自动评分,而多项选择、是非题等结构化问题则通过精确匹配进行评判。用户亦可参考仓库中的数据生成脚本,自行构建类似的多模态基准数据集,以适应更广泛的研究需求。
背景与挑战
背景概述
IndicVisionBench是由Ali Faraz、Akash、Shaharukh Khan等研究者在Krutrim AI实验室主导创建,于2025年发布于arXiv(编号2511.04727),并已被ICLR 2026接收。该数据集聚焦于评估视觉语言模型(VLM)在印度文化语境下的多语言视觉理解能力,覆盖英语及10种印度本地语言(如印地语、泰米尔语、孟加拉语等),涵盖多模态机器翻译、光学字符识别、视觉问答以及对抗性鲁棒性等任务。其创建背景源于当前主流VLM基准大多以英语为中心,缺乏对非英语、高语境文化的深度覆盖,而印度作为语言和文化多样性极为丰富的区域,对评估模型的文化泛化能力具有不可替代的代表性。IndicVisionBench通过包含地域特定主题、州邦元数据以及跨语言一致性测试,为研究多语言与文化对齐的VLM提供了系统性评估框架,对推动包容性人工智能的发展具有重要意义。
当前挑战
IndicVisionBench所解决的领域问题核心在于:现有视觉语言基准普遍忽视文化多样性与多语言理解,尤其对印度次大陆的视觉文化语境(如宗教符号、地方服饰、日常场景)覆盖不足,导致模型在此类任务中表现脆弱,且常因训练数据偏差出现文化不敏感或刻板印象。具体挑战包括:1)构建过程中需跨10种印度语言收集并验证平行语料,确保翻译的文化术语一致性;2)视觉问答子集需设计对抗性问题以检测模型对虚假假设的鲁棒性;3)OCR子集面临多种非拉丁手写体与历史扫描件噪声的识别困难;4)多模态翻译任务需保持视觉上下文与跨语言语义的精准对齐。此外,数据采集覆盖11种语言的4527张图像,地域分布需平衡各邦文化的代表性以避免区域偏倚,这本身就构成了工程与数据伦理层面的双重挑战。
常用场景
经典使用场景
IndicVisionBench作为一项面向印度文化背景的多语言视觉语言基准,其经典使用场景集中于评估视觉语言模型(VLM)在印度次大陆语境下的综合视觉理解能力。研究者可借助该数据集的五个核心配置——包括多模态机器翻译(MMT)、光学字符识别(OCR)、英文视觉问答(VQA_EN)、印度语言视觉问答(VQA_Indic)以及平行视觉问答(VQA_Parallel)——系统性地测试模型在场景理解、属性识别、文化常识推理及对抗鲁棒性等维度上的表现。该基准特别强调对印度各邦区域特性、11种主流语言的覆盖,以及跨语言一致性的考察,为多模态模型的细粒度评估提供了具有文化地理标识的标准化测试平台。
解决学术问题
该数据集着力回应当前视觉语言模型研究中文化多样性缺失与多语言泛化能力不足的核心学术困境。传统VQA基准多以西方文化数据为主,导致模型在非英语或非西方语境下表现骤降。IndicVisionBench通过构建蕴含印度区域知识、宗教符号、传统服饰及日常场景的图像-文本对,首次实现了对模型文化敏感性、视觉接地翻译能力及多语言推理一致性的统一量化评估。其引入的对抗性问题设计,更是为揭露模型在面对误导性预设时的脆弱性提供了关键分析维度,从而推动学界从“通用视觉理解”向“文化包容性智能”的范式转变。
衍生相关工作
IndicVisionBench的发布催生了一系列富有启发性的衍生研究工作。其一,基于其平行VQA配置,学者们率先开展了跨语言视觉问答中的锚点对齐研究,提出了用于缓解低资源语言表示偏移的对比学习框架。其二,该数据集的对抗性问题集合激发了针对VLM虚假相关性的鲁棒性增强算法,如基于文化常识图谱的防御网络。其三,在OCR领域,该基准推动了零样本印地语混合字体识别方案的诞生,结合了视觉Transformer与字素分割技术。最后,该数据集还被用作大规模多语言视觉预训练模型的验证标准,显著提升了如XLM-SE等模型在印度语境下的迁移学习效率,形成了闭环的学术创新生态。
以上内容由遇见数据集搜集并总结生成


