Charades-Ego
收藏arXiv2025-09-30 收录
下载链接:
https://prior.allenai.org/projects/charades-ego
下载链接
链接失效反馈官方服务:
资源简介:
该数据集旨在识别第一人称视角视频中的动作,其评估指标为平均平均精度(mAP),主要任务是对动作进行识别。
This dataset aims to recognize actions in first-person perspective videos. Mean Average Precision (mAP) is used as its evaluation metric, and the main task of this dataset is action recognition.
搜集汇总
数据集介绍
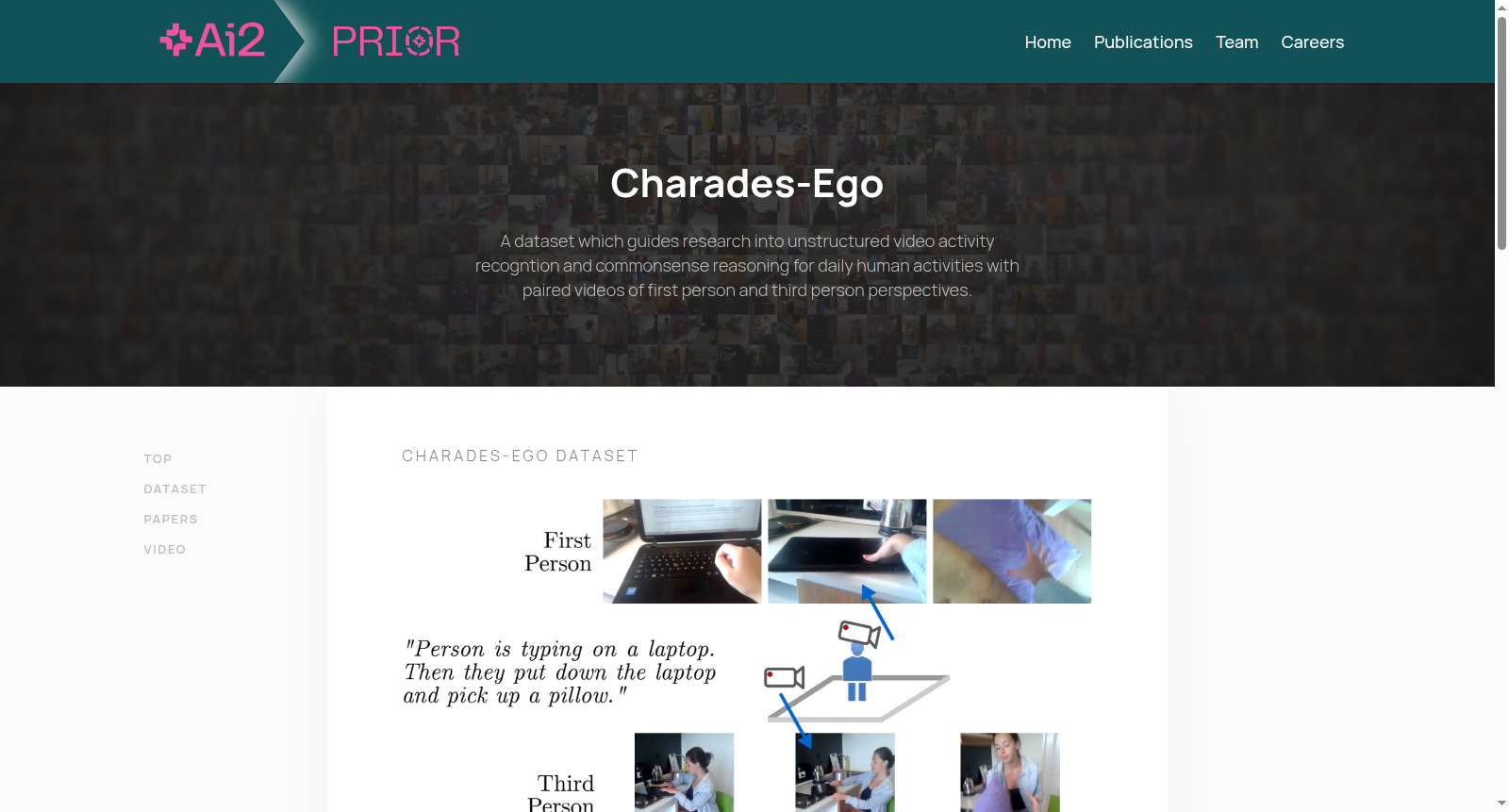
构建方式
在增强现实与虚拟现实技术蓬勃发展的背景下,Charades-Ego数据集的构建遵循了“家庭好莱坞”的采集范式。研究团队通过亚马逊众包平台招募参与者,要求每位参与者依据统一脚本,分别录制第三人称视角与第一人称视角的视频。第一人称视频通过将摄像头固定于前额的方式获取,这一设计在保证视角配对的同时兼顾了采集的可扩展性。数据采集过程涵盖了112位参与者在其家庭环境中的多样场景,最终形成了总计68.8小时的配对视频,包含68,536个活动实例,其脚本与活动类别均与原有的Charades数据集高度共享,确保了数据的丰富性与连续性。
使用方法
为促进跨视角视频理解研究,Charades-Ego数据集通常按8:2的比例划分为训练集与测试集,并确保不同集合间的参与者完全独立。研究者可利用其配对视频特性,开展监督学习、跨视角迁移学习或零样本识别等实验。例如,可先在第三人称数据上预训练模型,再使用数据集中的第一人称标注进行微调,以提升模型在自我中心视角下的识别性能。数据集中提供的时间标注与活动标签,使得其能够广泛应用于动作识别、时序行为检测、视频描述生成等计算机视觉任务,为模型在复杂真实场景中的泛化能力评估提供了标准基准。
背景与挑战
背景概述
随着增强现实与虚拟现实等应用的兴起,第一人称视角视频理解领域在近年来迅速发展。为了弥合第三人称与第一人称视频理解之间的鸿沟,卡内基梅隆大学、Inria及艾伦人工智能研究所的研究团队于2018年共同创建了Charades-Ego数据集。该数据集采用“家庭好莱坞”众包策略,邀请网络用户按照既定脚本录制成对的第三与第一人称视频,核心研究问题在于探索跨视角视频的联合建模,以利用海量易得的第三人称视频提升第一人称视频的理解能力。Charades-Ego包含68.8小时的双视角视频,涵盖68,536个活动实例,其规模与多样性在当时位居前列,为第一人称视频分类、定位、描述等任务提供了重要基准,显著推动了跨模态视频分析领域的发展。
当前挑战
在领域问题层面,Charades-Ego致力于解决第一人称动作理解的挑战,包括视角差异导致的视觉内容变化、遮挡频繁以及动作边界模糊等问题,这些因素使得模型在跨视角迁移学习中难以保持高精度。构建过程中,研究团队面临多重挑战:为确保双视角视频的对应性,需设计兼顾同步性与可扩展性的采集方案;通过众包获取高质量视频时,需平衡参与者使用自制头戴设备与单手操作的可行性;此外,标注过程需同时处理双视角视频,以第三人称视频为参照提升第一人称标注的准确性,这一协同标注机制虽提升了质量,却增加了标注复杂度与成本。
常用场景
经典使用场景
在增强现实与虚拟现实技术蓬勃发展的背景下,Charades-Ego数据集通过配对的第一人称与第三人称视频,为自我中心视觉理解领域提供了关键研究平台。该数据集最经典的应用场景在于训练和评估跨视角动作识别模型,研究者利用其大规模、多样化的视频对,探索从第三人称视角到第一人称视角的知识迁移机制,从而推动自我中心视频分析算法的性能边界。
解决学术问题
该数据集有效解决了自我中心视觉中数据稀缺与标注困难的核心挑战。通过提供同步且内容一致的双视角视频,它支持跨模态学习、零样本识别以及时序动作定位等前沿研究问题。其丰富的时空标注与文本描述,使得模型能够更精确地理解日常活动的语义与上下文,显著提升了自我中心动作识别的准确性与鲁棒性,为连接不同视角的视频理解领域奠定了数据基础。
实际应用
在实际应用层面,Charades-Ego数据集为智能可穿戴设备、家庭服务机器人以及沉浸式交互系统提供了关键技术支撑。基于该数据集训练的模型能够实时解析用户的第一人称视角视频,实现精准的活动监测、行为辅助与环境理解,从而推动个性化健康管理、智能家居控制以及增强现实导航等实用场景的落地与优化。
数据集最近研究
最新研究方向
在计算机视觉领域,随着增强现实和虚拟现实应用的兴起,第一人称视角视频理解成为研究热点。Charades-Ego数据集凭借其大规模成对的第三与第一人称视频,为跨视角动作识别提供了关键支撑。当前前沿研究聚焦于利用该数据集的跨模态特性,探索零样本学习与迁移学习策略,以提升模型在未知环境下的泛化能力。同时,研究者正致力于开发联合建模方法,通过融合双视角信息来优化动作分类、定位与描述任务,推动人机交互与智能辅助系统的发展。这些进展不仅深化了视觉理解的理论基础,也为实际应用场景如智能监控与沉浸式体验提供了技术保障。
相关研究论文
- 1Charades-Ego: A Large-Scale Dataset of Paired Third and First Person Videos卡内基梅隆大学 · 2018年
以上内容由遇见数据集搜集并总结生成


